

Wie Mixture-of-Adaptations die Feinabstimmung von Sprachmodellen günstiger und intelligenter macht
Tabelle der Links
Abstrakt und 1. Einleitung
-
Hintergrund
2.1 Mixture-of-Experts
2.2 Adapter
-
Mixture-of-Adaptations
3.1 Routing-Richtlinie
3.2 Konsistenzregularisierung
3.3 Zusammenführung von Adaptationsmodulen und 3.4 Gemeinsame Nutzung von Adaptationsmodulen
3.5 Verbindung zu Bayesschen Neuronalen Netzwerken und Modell-Ensembling
-
Experimente
4.1 Experimenteller Aufbau
4.2 Wichtigste Ergebnisse
4.3 Ablationsstudie
-
Verwandte Arbeiten
-
Schlussfolgerungen
-
Einschränkungen
-
Danksagung und Referenzen
Anhang
A. Few-shot NLU Datensätze B. Ablationsstudie C. Detaillierte Ergebnisse zu NLU-Aufgaben D. Hyperparameter
3 Mixture-of-Adaptations

\
3.1 Routing-Richtlinie
Neuere Arbeiten wie THOR (Zuo et al., 2021) haben gezeigt, dass stochastische Routing-Richtlinien wie zufälliges Routing genauso gut funktionieren wie klassische Routing-Mechanismen wie Switch-Routing (Fedus et al., 2021) mit den folgenden Vorteilen. Da Eingabebeispiele zufällig an verschiedene Experten weitergeleitet werden, ist keine zusätzliche Lastverteilung erforderlich, da jeder Experte die gleiche Chance hat, aktiviert zu werden, was das Framework vereinfacht. Darüber hinaus gibt es keine zusätzlichen Parameter und daher keine zusätzliche Berechnung auf der Switch-Ebene für die Expertenauswahl. Letzteres ist in unserer Einstellung für parametereffizientes Fine-Tuning besonders wichtig, um die Parameter und FLOPs gleich zu halten wie bei einem einzelnen Adaptationsmodul. Um die Funktionsweise von AdaMix zu analysieren, zeigen wir in Abschnitt 3.5 Verbindungen zu stochastischem Routing und Modellgewichtsmittelung zu Bayesschen Neuronalen Netzwerken und Modell-Ensembling auf.
\ \ 
\ \ Ein solches stochastisches Routing ermöglicht es Adaptationsmodulen, während des Trainings verschiedene Transformationen zu erlernen und mehrere Ansichten der Aufgabe zu erhalten. Dies schafft jedoch auch eine Herausforderung, welche Module während der Inferenz verwendet werden sollen, aufgrund des zufälligen Routing-Protokolls während des Trainings. Wir begegnen dieser Herausforderung mit den folgenden zwei Techniken, die es uns weiterhin ermöglichen, Adaptationsmodule zusammenzuführen und die gleichen Rechenkosten (FLOPs, #abstimmbare Adaptationsparameter) wie bei einem einzelnen Modul zu erhalten.
3.2 Konsistenzregularisierung
\ 
\ \ \ 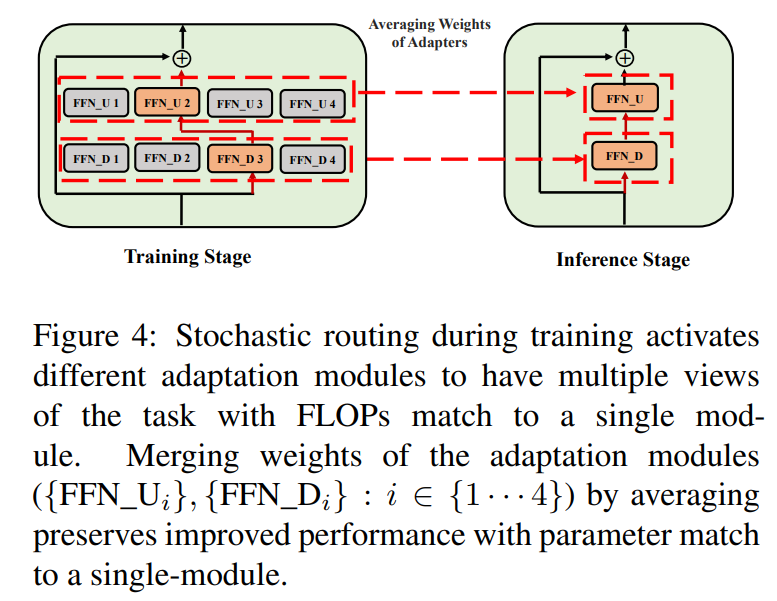
3.3 Zusammenführung von Adaptationsmodulen
Während die obige Regularisierung Inkonsistenzen bei der zufälligen Modulauswahl während der Inferenz mildert, führt sie dennoch zu erhöhten Bereitstellungskosten für die Unterbringung mehrerer Adaptationsmodule. Frühere Arbeiten zum Fine-Tuning von Sprachmodellen für nachgelagerte Aufgaben haben eine verbesserte Leistung bei der Mittelung der Gewichte verschiedener Modelle gezeigt, die mit verschiedenen Zufallsinitialisierungen feinabgestimmt wurden und ein einzelnes feinabgestimmtes Modell übertreffen. Neuere Arbeiten (Wortsman et al., 2022) haben auch gezeigt, dass unterschiedlich feinabgestimmte Modelle aus derselben Initialisierung im selben Fehlerbecken liegen, was die Verwendung von Gewichtsaggregation für eine robuste Aufgabenzusammenfassung motiviert. Wir übernehmen und erweitern frühere Techniken für das Fine-Tuning von Sprachmodellen für unser parametereffizientes Training von Multi-View-Adaptationsmodulen
\ \ 
\
3.4 Gemeinsame Nutzung von Adaptationsmodulen
\ 
3.5 Verbindung zu Bayesschen Neuronalen Netzwerken und Modell-Ensembling
\ 
\ \ Dies erfordert die Mittelung über alle möglichen Modellgewichte, was in der Praxis nicht durchführbar ist. Daher wurden mehrere Approximationsmethoden entwickelt, die auf Variationsinferenzmethoden und stochastischen Regularisierungstechniken mit Dropouts basieren. In dieser Arbeit nutzen wir eine weitere stochastische Regularisierung in Form von zufälligem Routing. Hier besteht das Ziel darin, eine Ersatzverteilung qθ(w) in einer berechenbaren Familie von Verteilungen zu finden, die die wahre Modellposterior ersetzen kann, die schwer zu berechnen ist. Der ideale Ersatz wird durch Minimierung der Kullback-Leibler (KL) Divergenz zwischen dem Kandidaten und der wahren Posterior identifiziert.
\ \ 
\ \ \ 
\ \ \ 
\ \ \ \
:::info Autoren:
(1) Yaqing Wang, Purdue University (wang5075@purdue.edu);
(2) Sahaj Agarwal, Microsoft (sahagar@microsoft.com);
(3) Subhabrata Mukherjee, Microsoft Research (submukhe@microsoft.com);
(4) Xiaodong Liu, Microsoft Research (xiaodl@microsoft.com);
(5) Jing Gao, Purdue University (jinggao@purdue.edu);
(6) Ahmed Hassan Awadallah, Microsoft Research (hassanam@microsoft.com);
(7) Jianfeng Gao, Microsoft Research (jfgao@microsoft.com).
:::
:::info Dieses Paper ist auf arxiv verfügbar unter der CC BY 4.0 DEED Lizenz.
:::
\
Das könnte Ihnen auch gefallen

Cyberangriff als Ursache?: Großer IT-Ausfall während Selenskyj-Besuch im Bundestag

Sogar Macron kommt ins Schwärmen: Die Geschichte hinter dem besten Spiel des Jahres ist absolut verrückt
