

Wie hybride KI-Modelle Speicher und Effizienz ausbalancieren
Inhaltsverzeichnis
Abstrakt und 1. Einleitung
-
Methodik
-
Experimente und Ergebnisse
3.1 Sprachmodellierung auf vQuality-Daten
3.2 Untersuchung zu Aufmerksamkeit und linearer Rekurrenz
3.3 Effiziente Längenextrapolation
3.4 Verständnis langer Kontexte
-
Analyse
-
Fazit, Danksagung und Referenzen
A. Implementierungsdetails
B. Zusätzliche Versuchsergebnisse
C. Details zur Entropiemessung
D. Einschränkungen
\
A Implementierungsdetails
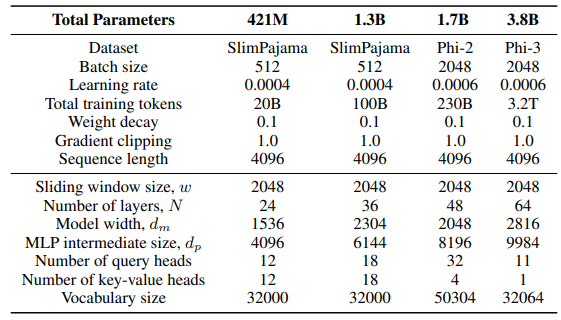
\ Für die GLA-Schicht in der Sliding-GLA-Architektur verwenden wir die Anzahl der Köpfe dm/384, ein Schlüsselerweiterungsverhältnis von 0,5 und ein Werterweiterungsverhältnis von 1. Für die RetNet-Schicht verwenden wir eine Anzahl von Köpfen, die der Hälfte der Anzahl der Aufmerksamkeitsabfrageköpfe entspricht, ein Schlüsselerweiterungsverhältnis von 1 und ein Werterweiterungsverhältnis von 2. Die GLA- und RetNet-Implementierungen stammen aus dem Flash Linear Attention Repository[3] [YZ24]. Wir verwenden die FlashAttention-basierte Implementierung für die Self-Extend-Extrapolation[4]. Das Mamba 432M-Modell hat eine Modellbreite von 1024 und das Mamba 1.3B-Modell hat eine Modellbreite von 2048. Alle auf SlimPajama trainierten Modelle haben die gleichen Trainingskonfigurationen und die MLP-Zwischengröße wie Samba, sofern nicht anders angegeben. Die Trainingsinfrastruktur auf SlimPajama basiert auf einer modifizierten Version des TinyLlama-Codebasis[5].
\ 
\ In den Generierungskonfigurationen für die nachgelagerten Aufgaben verwenden wir Greedy-Decoding für GSM8K und Nucleus Sampling [HBD+19] mit einer Temperatur von τ = 0,2 und top-p = 0,95 für HumanEval. Für MBPP und SQuAD setzen wir τ = 0,01 und top-p = 0,95.
B Zusätzliche Versuchsergebnisse
\ 
\ 
\ 
\
C Details zur Entropiemessung
\ 
\
D Einschränkungen
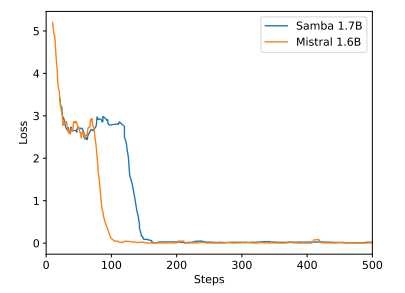
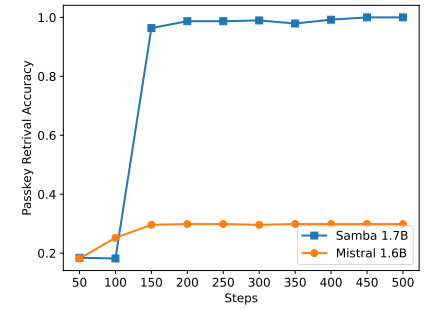
Obwohl Samba durch Instruktionstraining eine vielversprechende Speicherabrufleistung zeigt, hat sein vortrainiertes Basismodell eine Abrufleistung, die der des SWA-basierten Modells ähnlich ist, wie in Abbildung 7 gezeigt. Dies eröffnet zukünftige Richtungen zur weiteren Verbesserung der Abruffähigkeit von Samba, ohne seine Effizienz und Extrapolationsfähigkeit zu beeinträchtigen. Darüber hinaus ist die Hybridisierungsstrategie von Samba nicht durchgängig besser als andere Alternativen in allen Aufgaben. Wie in Tabelle 2 gezeigt, zeigt MambaSWA-MLP verbesserte Leistung bei Aufgaben wie WinoGrande, SIQA und GSM8K. Dies gibt uns das Potenzial, in einen anspruchsvolleren Ansatz zu investieren, um eingabeabhängige dynamische Kombinationen von SWA-basierten und SSM-basierten Modellen durchzuführen.
\
:::info Autoren:
(1) Liliang Ren, Microsoft und University of Illinois at Urbana-Champaign (liliangren@microsoft.com);
(2) Yang Liu†, Microsoft (yaliu10@microsoft.com);
(3) Yadong Lu†, Microsoft (yadonglu@microsoft.com);
(4) Yelong Shen, Microsoft (yelong.shen@microsoft.com);
(5) Chen Liang, Microsoft (chenliang1@microsoft.com);
(6) Weizhu Chen, Microsoft (wzchen@microsoft.com).
:::
:::info Dieses Paper ist auf arxiv verfügbar unter der CC BY 4.0 Lizenz.
:::
[3] https://github.com/sustcsonglin/flash-linear-attention
\ [4] https://github.com/datamllab/LongLM/blob/master/selfextendpatch/Llama.py
\ [5] https://github.com/jzhang38/TinyLlama
Das könnte Ihnen auch gefallen

Exor lehnt Tethers Vorschlag in Höhe von 1 Milliarde Dollar zur Übernahme von Juventus ab

Shiba Inu (SHIB) Preiskampf: Ist eine Rally in Richtung $0,00002370 möglich?
