

Neue IIL-Einstellung: Verbesserung eingesetzter Modelle nur mit neuen Daten
Inhaltsverzeichnis
Abstrakt und 1 Einleitung
-
Verwandte Arbeiten
-
Problemstellung
-
Methodik
4.1. Entscheidungsgrenze-bewusste Destillation
4.2. Wissenskonsolidierung
-
Experimentelle Ergebnisse und 5.1. Versuchsaufbau
5.2. Vergleich mit SOTA-Methoden
5.3. Ablationsstudie
-
Schlussfolgerung und zukünftige Arbeit und Referenzen
\
Zusatzmaterial
- Details der theoretischen Analyse des KCEMA-Mechanismus in IIL
- Algorithmusübersicht
- Datensatzdetails
- Implementierungsdetails
- Visualisierung von verstaubten Eingabebildern
- Weitere experimentelle Ergebnisse
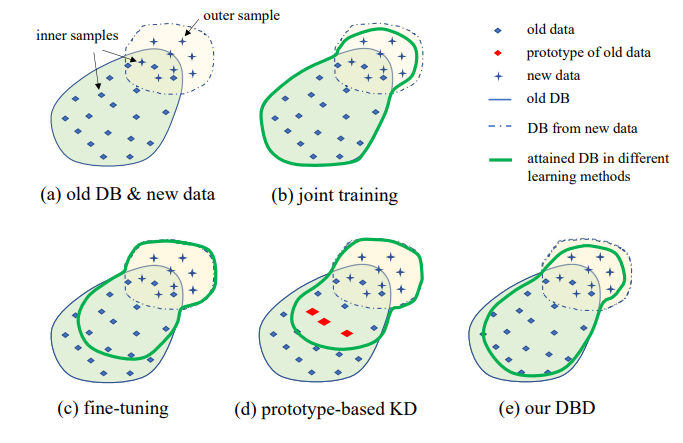
3. Problemstellung
Die Illustration der vorgeschlagenen IIL-Einstellung ist in Abb. 1 dargestellt. Wie zu sehen ist, werden Daten kontinuierlich und unvorhersehbar im Datenstrom generiert. In realen Anwendungen neigen Menschen dazu, zuerst genügend Daten zu sammeln und ein starkes Modell M0 für den Einsatz zu trainieren. Unabhängig davon, wie stark das Modell ist, wird es unweigerlich auf Out-of-Distribution-Daten stoßen und daran scheitern. Diese fehlgeschlagenen Fälle und andere neue Beobachtungen mit niedrigem Score werden von Zeit zu Zeit annotiert, um das Modell zu trainieren. Das Neutraining des Modells mit allen kumulierten Daten führt jedes Mal zu höheren Zeit- und Ressourcenkosten. Daher zielt das neue IIL darauf ab, das bestehende Modell jedes Mal nur mit den neuen Daten zu verbessern.
\ 
\ 
\
:::info Autoren:
(1) Qiang Nie, Hong Kong University of Science and Technology (Guangzhou);
(2) Weifu Fu, Tencent Youtu Lab;
(3) Yuhuan Lin, Tencent Youtu Lab;
(4) Jialin Li, Tencent Youtu Lab;
(5) Yifeng Zhou, Tencent Youtu Lab;
(6) Yong Liu, Tencent Youtu Lab;
(7) Qiang Nie, Hong Kong University of Science and Technology (Guangzhou);
(8) Chengjie Wang, Tencent Youtu Lab.
:::
:::info Dieses Paper ist auf arxiv verfügbar unter der CC BY-NC-ND 4.0 Deed (Attribution-Noncommercial-Noderivs 4.0 International) Lizenz.
:::
\
Das könnte Ihnen auch gefallen

Zweimal an einem Tag: Fußballfans wüten in Regionalbahn und entkommen unerkannt

KI-Investitionen stocken – Bremse für Wirtschaft und Gefahr für Bitcoin
