

Are Large Language Models the Future of Game State Simulation?
:::info Authors:
(1) Ruoyao Wang, University of Arizona (ruoyaowang@arizona.edu);
(2) Graham Todd, New York University (gdrtodd@nyu.edu);
(3) Ziang Xiao, Johns Hopkins University (ziang.xiao@jhu.edu);
(4) Xingdi Yuan, Microsoft Research Montréal (eric.yuan@microsoft.com);
(5) Marc-Alexandre Côté, Microsoft Research Montréal (macote@microsoft.com);
(6) Peter Clark, Allen Institute for AI (PeterC@allenai.org).;
(7) Peter Jansen, University of Arizona and Allen Institute for AI (pajansen@arizona.edu).
:::
Table of Links
Abstract and 1. Introduction and Related Work
-
Methodology
2.1 LLM-Sim Task
2.2 Data
2.3 Evaluation
-
Experiments
-
Results
-
Conclusion
-
Limitations and Ethical Concerns, Acknowledgements, and References
A. Model details
B. Game transition examples
C. Game rules generation
D. Prompts
E. GPT-3.5 results
F. Histograms
Abstract
Virtual environments play a key role in benchmarking advances in complex planning and decision-making tasks but are expensive and complicated to build by hand. Can current language models themselves serve as world simulators, correctly predicting how actions change different world states, thus bypassing the need for extensive manual coding? Our goal is to answer this question in the context of text-based simulators. Our approach is to build and use a new benchmark, called BYTESIZED32-State-Prediction, containing a dataset of text game state transitions and accompanying game tasks. We use this to directly quantify, for the first time, how well LLMs can serve as text-based world simulators. We test GPT-4 on this dataset and find that, despite its impressive performance, it is still an unreliable world simulator without further innovations. This work thus contributes both new insights into current LLM’s capabilities and weaknesses, as well as a novel benchmark to track future progress as new models appear.
1 Introduction and Related Work
Simulating the world is crucial for studying and understanding it. In many cases, however, the breadth and depth of available simulations are limited by the fact that their implementation requires extensive work from a team of human experts over weeks or months. Recent advances in large language models (LLMs) have pointed towards an alternate approach by leveraging the huge amount of knowledge contained in their pre-training datasets. But are they ready to be used directly as simulators?
\ We examine this question in the domain of textbased games, which naturally express the environment and its dynamics in natural language and have long been used as part of advances in decision making processes (Côté et al., 2018; Fan et al., 2020; Urbanek et al., 2019; Shridhar et al., 2020; Hausknecht et al., 2020; Jansen, 2022; Wang et al.,2023), information extraction (Ammanabrolu and Hausknecht, 2020; Adhikari et al., 2020), and artificial reasoning (Wang et al., 2022).
\ 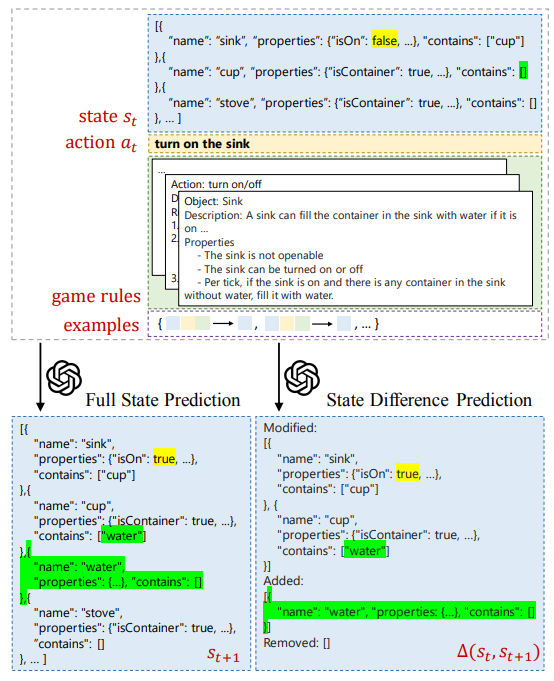
\ Broadly speaking, there are two ways to leverage LLMs in the context of world modeling and simulation. The first is neurosymbolic: a number of efforts use language models to generate code in a symbolic representation that allows for formal planning or inference (Liu et al., 2023; Nottingham et al., 2023; Wong et al., 2023; Tang et al., 2024). REASONING VIA PLANNING (RAP) (Hao et al., 2023) is one such approach – it constructs a world model using LLM priors and then uses a dedicated planning algorithm to decide on agent policies (LLMs themselves continue to struggle to act directly as planners (Valmeekam et al., 2023)). Similarly, BYTESIZED32 (Wang et al., 2023) tasks LLMs with instantiating simulations of scientific reasoning concepts in the form of large PYTHON programs. These efforts are in contrast to the second, and comparatively less studied, approach of direct simulation. For instance, AI-DUNGEON represents a game world purely through the generated output of a language model, with inconsistent results (Walton, 2020). In this work, we provide the first quantitative analysis of the abilities of LLMs to directly simulate virtual environments. We make use of structured representations in the JSON schema as a scaffold that both improves simulation accuracy and allows for us to directly probe the LLM’s abilities across a variety of conditions.
\ In a systematic analysis of GPT-4 (Achiam et al., 2023), we find that LLMs broadly fail to capture state transitions not directly related to agent actions, as well as transitions that require arithmetic, common-sense, or scientific reasoning. Across a variety of conditions, model accuracy does not exceed 59.9% for transitions in which a non-trivial change in the world state occurs. These results suggest that, while promising and useful for downstream tasks, LLMs are not yet ready to act as reliable world simulators without further innovation.[1]
\
:::info This paper is available on arxiv under CC BY 4.0 license.
:::
[1] Code and data are available at https://github. com/cognitiveailab/GPT-simulator.


You May Also Like

Robinhood (HOOD) Stock Surges 6% as the $25K Trading Wall Finally Comes Down

Immutep (IMM) Stock Doubles on FDA Orphan Drug Win for Rare Cancer Drug




