

Make Class-Agnostic 3D Segmentation Efficient with 3DIML
Table of Links
Abstract and I. Introduction
II. Background
III. Method
IV. Experiments
V. Conclusion and References
\
IV. EXPERIMENTS
We benchmark our method against Panoptic and Contrastive Lifting using the same Mask2Former frontend. For fairness, we render semantics as in [5], [6] using the same multiresolution hashgrid for semantics and instances. For other experiments, we utilize GroundedSAM as our frontend and FastSAM for runtime performance critical tasks such as label merging and InstanceLoc.
\ A. Datasets
\ We evaluate our methods on a challenging subset of scans from Replica and ScanNet, which provide ground truth annotations. Since our methods are based on structure from motion techniques, we utilize the Replica-vMap [20] sequences, which is more indicative of real-world collected image sequences. For Replica and ScanNet, we avoid scans with various incompatibilities with our method (multi-room, low visibility, Nerfacto doesn’t converge) as well as those containing many close-up views of identical objects that easily confuse NetVLAD and LoFTR.
\ B. Metrics
\ For lifting panoptic segmentation, we utilize Scene Level Panoptic Quality [5], defined as the Panoptic Quality for the concatenated sequence of images. For Grounded SAM, especially with instance masks for smaller objects, there is a divergence in alignment with ground truth annotations. As such, we report mIoU for predicted, reference masks that have IoU > 0.5 over all frames (TP in Scene Level Panoptic Quality) as well as the number of such matched masks and the total number of reference masks.
\ C. Implementation Details
\ 
\ D. Results
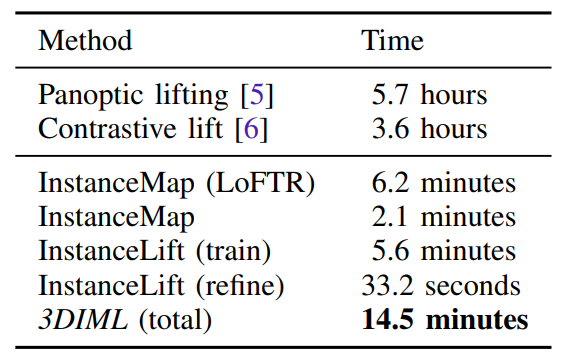
\ Comparison with Panoptic and Contrastive Lifting: Table II shows the Scene Level Panoptic Quality for 3DIML and other methods on Replica-vMap sequences subsampled by 10 (200 frames). We observe 3DIML approaches Panoptic Lifting in performance while achieving a much larger practical runtime (considering implementation) than Panoptic and Contrastive Lifting. Intuitively, this is achieved by efficiently relying on implicit scene representation methods only at critical junctions i.e. post InstanceMap, greatly reducing the number of training iterations of the neural field (25x less). Figure 4 compares the instances identified by Panoptic Lifting to 3DIML.
\ We benchmark all runtimes using a single RTX 3090 post-mask generation. Specifically, comparing their implementation to ours, Panoptic Lifting requires 5.7 hours of training over all scans, with a min and max of 3.6 and 6.6 hours, respectively, since its runtime depends on the number of objects. Contrastive Lifting takes around 3.5 hours on average while 3DIML runs under 20 minutes (14.5 minutes on average) for all scans. Note several components of 3DIML can be easily parallelized, such as dense descriptors extraction using LoFTR and label merging. The runtime of our method is dependent on the number of correspondences produced by LofTR, which doesn’t change for different frontend segmentation models, and we observe similar runtimes for other experiments.
\ 
\ ![TABLE I: Quantitative comparison between pannoptic lifting [5], contrastive lift [6], and our framework components, InstanceMap and InstanceLift. We measure the scene level panoptic quality metric (higher value indicates better performance). Our approach offers competitive performance while being far more efficient to train. Best performing numbers for each scene are in bold, while the second-best numbers are shaded yellow.](https://cdn.hackernoon.com/images/null-fa3334n.png)
\ 
\ 
\ Grounded SAM Table III shows our results for lifting GroundedSAM masks for Replica-vMap. From Figure 5 we see that InstanceLift is effective at interpolating labels missed by InstanceMap and resolving ambiguities produced by GroundedSAM[1]. Figure 7 shows that InstanceMap and 3DIML are robust to large viewpoint changes and as well as duplicate objects, assuming nice scans, that is enough context for NetVLAD and LoFTR to somewhat distinguish between them. Table IV and Fig. 6 illustrate our performance on ScanNet [21].
\ ![Fig. 6: Some results for scans 0144 01, 0050 02, and 0300 01 from ScanNet [21] (one scene per row, top to bottom), showcasing how 3DIML accurately and consistently delineates instances in 3D.](https://cdn.hackernoon.com/images/null-ew633g6.png)
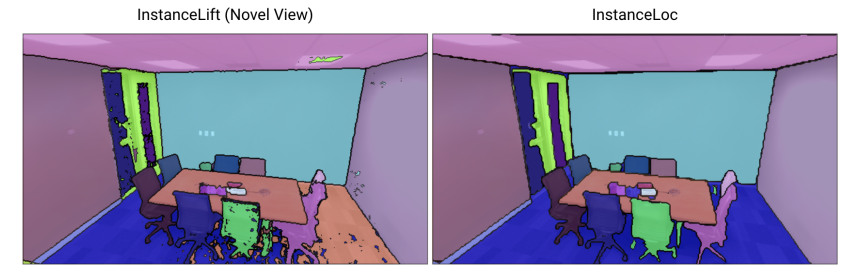
\ Novel View Rendering and InstanceLoc Table V shows the performance if 3DIML on the second track provided in Replica-vMap. We observe that InstanceLift is effective at rendering new views, and therefore InstanceLoc performs well. For Replica-vMap and FastSAM, InstanceLoc takes on average 0.16s per localized image (6.2 frames per second). In addition, InstanceLoc can be applied as a post-processing step to the renders of the input sequence as a denoising operation.
\ E. Limitations and Future Work
\ In extreme viewpoint changes, our method sometimes produced discontinuous 3D instance labels. For example, on the worst performing scene, office2, we see that since the scan images only the front of a chair facing the back of the room and the back of a chair facing the front of the room for many frames, InstanceMap is not able to conclude these labels refer to the same object, and InstanceLift was unable to fix it, as NeRF’s correction performance rapidly degrades with increasing label inconsistency [12]. However, there are very few of these left per scene post 3DIML, and they can be easily fixed via sparse human annotation.
V. CONCLUSION
In this paper, we present 3DIML, which addresses the problem of 3D instance segmentation in a class-agnostic and computationally efficient manner. By employing a novel approach that utilizes InstanceMap and InstanceLift for generating and refining view-consistent pseudo instance masks from a sequence of posed RGB images, we circumvent the complexities associated with previous methods that only optimize a neural field. Furthermore, the introduction of InstanceLoc allows rapid localization of instances in unseen views by combining fast segmentation models and a refined neural label field. Our evaluations across Replica and ScanNet and different frontend segmentation models showcase *3DIML’*s speed and effectiveness. It offers a promising avenue for real-world applications requiring efficient and accurate scene analysis.
\ ![Fig. 7: Qualitative results on office3 and room1 from the Replica-vMap split [20]. Both InstanceMap and InstanceLift are able to maintain quality and consistency over the image sequence despite duplicate objects due to sufficient image context overlap across the sequence.](https://cdn.hackernoon.com/images/null-o60339a.png)
\ 
\ 
\ ![TABLE V: Quantitative (mIoU, TP) results for InstanceLift and InstanceLoc on novel views over the Replica-vMap split [20].](https://cdn.hackernoon.com/images/null-18333l3.png)
\ 
\ ![Fig. 9: Our methods do not perform well in cases where the scan sequence contains only images of the different sides of an object (chair) or surface (floor) from differing directions without any smooth transitions in between, which occurs for office2 from Replica (vMap split [20]).](https://cdn.hackernoon.com/images/null-ql533m0.png)
\
REFERENCES
[1] B. Cheng, I. Misra, A. G. Schwing, A. Kirillov, and R. Girdhar, “Masked-attention mask transformer for universal image segmentation,” CoRR, vol. abs/2112.01527, 2021. [Online]. Available: https://arxiv.org/abs/2112.01527 1, 2
\ [2] A. Kirillov, E. Mintun, N. Ravi, H. Mao, C. Rolland, L. Gustafson, T. Xiao, S. Whitehead, A. C. Berg, W.-Y. Lo et al., “Segment anything,” arXiv preprint arXiv:2304.02643, 2023. 1, 2, 3
\ [3] J. Schult, F. Engelmann, A. Hermans, O. Litany, S. Tang, and B. Leibe, “Mask3d: Mask transformer for 3d semantic instance segmentation,” in 2023 IEEE International Conference on Robotics and Automation (ICRA). IEEE, 2023, pp. 8216–8223. 1
\ [4] A. Takmaz, E. Fedele, R. W. Sumner, M. Pollefeys, F. Tombari, and F. Engelmann, “Openmask3d: Open-vocabulary 3d instance segmentation,” arXiv preprint arXiv:2306.13631, 2023. 1
\ [5] Y. Siddiqui, L. Porzi, S. R. Bulo, N. Muller, M. Nießner, A. Dai, and P. Kontschieder, “Panoptic lifting for 3d scene understanding with neural fields,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2023, pp. 9043–9052. 2, 3, 4, 5
\ [6] Y. Bhalgat, I. Laina, J. F. Henriques, A. Zisserman, and A. Vedaldi, “Contrastive lift: 3d object instance segmentation by slow-fast contrastive fusion,” 2023. 2, 4, 5
\ [7] B. Mildenhall, P. P. Srinivasan, M. Tancik, J. T. Barron, R. Ramamoorthi, and R. Ng, “Nerf: Representing scenes as neural radiance fields for view synthesis,” Communications of the ACM, vol. 65, no. 1, pp. 99–106, 2021. 2, 3
\ [8] X. Zhao, W. Ding, Y. An, Y. Du, T. Yu, M. Li, M. Tang, and J. Wang, “Fast segment anything,” arXiv preprint arXiv:2306.12156, 2023. 2, 4
\ [9] L. Ke, M. Ye, M. Danelljan, Y. Liu, Y.-W. Tai, C.-K. Tang, and F. Yu, “Segment anything in high quality,” arXiv preprint arXiv:2306.01567, 2023. 2
\ [10] Y. Zhang, X. Huang, J. Ma, Z. Li, Z. Luo, Y. Xie, Y. Qin, T. Luo, Y. Li, S. Liu, Y. Guo, and L. Zhang, “Recognize anything: A strong image tagging model,” 2023. 2
\ [11] S. Liu, Z. Zeng, T. Ren, F. Li, H. Zhang, J. Yang, C. Li, J. Yang, H. Su, J. Zhu, and L. Zhang, “Grounding dino: Marrying dino with grounded pre-training for open-set object detection,” 2023. 2
\ [12] S. Zhi, T. Laidlow, S. Leutenegger, and A. J. Davison, “In-place scene labelling and understanding with implicit scene representation,” in Proceedings of the IEEE/CVF International Conference on Computer Vision, 2021, pp. 15 838–15 847. 2, 5
\ [13] A. Chen, Z. Xu, A. Geiger, J. Yu, and H. Su, “Tensorf: Tensorial radiance fields,” in European Conference on Computer Vision (ECCV), 2022. 2
\ [14] B. Hu, J. Huang, Y. Liu, Y.-W. Tai, and C.-K. Tang, “Instance neural radiance field,” arXiv preprint arXiv:2304.04395, 2023. 2, 3
\ [15] ——, “Nerf-rpn: A general framework for object detection in nerfs,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2023, pp. 23 528–23 538. 2
\ [16] P.-E. Sarlin, C. Cadena, R. Siegwart, and M. Dymczyk, “From coarse to fine: Robust hierarchical localization at large scale,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2019, pp. 12 716–12 725. 2
\ [17] J. Sun, Z. Shen, Y. Wang, H. Bao, and X. Zhou, “Loftr: Detectorfree local feature matching with transformers,” in Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2021, pp. 8922–8931. 2, 3
\ [18] M. Tancik, E. Weber, E. Ng, R. Li, B. Yi, T. Wang, A. Kristoffersen, J. Austin, K. Salahi, A. Ahuja et al., “Nerfstudio: A modular framework for neural radiance field development,” in ACM SIGGRAPH 2023 Conference Proceedings, 2023, pp. 1–12. 3, 4
\ [19] T. Muller, A. Evans, C. Schied, and A. Keller, “Instant neural ¨ graphics primitives with a multiresolution hash encoding,” ACM Transactions on Graphics, vol. 41, no. 4, p. 1–15, Jul. 2022. [Online]. Available: http://dx.doi.org/10.1145/3528223.3530127 3, 4
\ [20] X. Kong, S. Liu, M. Taher, and A. J. Davison, “vmap: Vectorised object mapping for neural field slam,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2023, pp. 952–961. 4, 6
\ [21] A. Dai, A. X. Chang, M. Savva, M. Halber, T. Funkhouser, and M. Nießner, “Scannet: Richly-annotated 3d reconstructions of indoor scenes,” in Proc. Computer Vision and Pattern Recognition (CVPR), IEEE, 2017. 5
\
:::info Authors:
(1) George Tang, Massachusetts Institute of Technology;
(2) Krishna Murthy Jatavallabhula, Massachusetts Institute of Technology;
(3) Antonio Torralba, Massachusetts Institute of Technology.
:::
:::info This paper is available on arxiv under CC by 4.0 Deed (Attribution 4.0 International) license.
:::
[1] GroundedSAM produces lower quality frontend masks than SAM due to prompting using bounding boxes instead of a point grid.


You May Also Like

Solana price confirms bearish crossover following Drift exploit, will it crash?

AI giants Meta, Microsoft, NVIDIA stocks slip amid Iran threat, AI cryptos crash




