

Bitcoin (BTC) Price: BTC Jumps 7% the Day After Jane Street Gets Sued — Coincidence?
TLDR
- Bitcoin surged ~7% as speculation grew that Jane Street halted a daily “10 a.m. dump” algorithm after being sued
- Terraform Labs’ bankruptcy administrator filed an 83-page lawsuit against Jane Street on Feb. 23, alleging insider trading tied to the 2022 TerraUSD collapse
- Bitcoin climbed above $68,000, adding over $170 billion to total crypto market cap
- The “10 a.m. dump” pattern saw Bitcoin fall in the first hour of U.S. trading in over 60% of sessions since early November
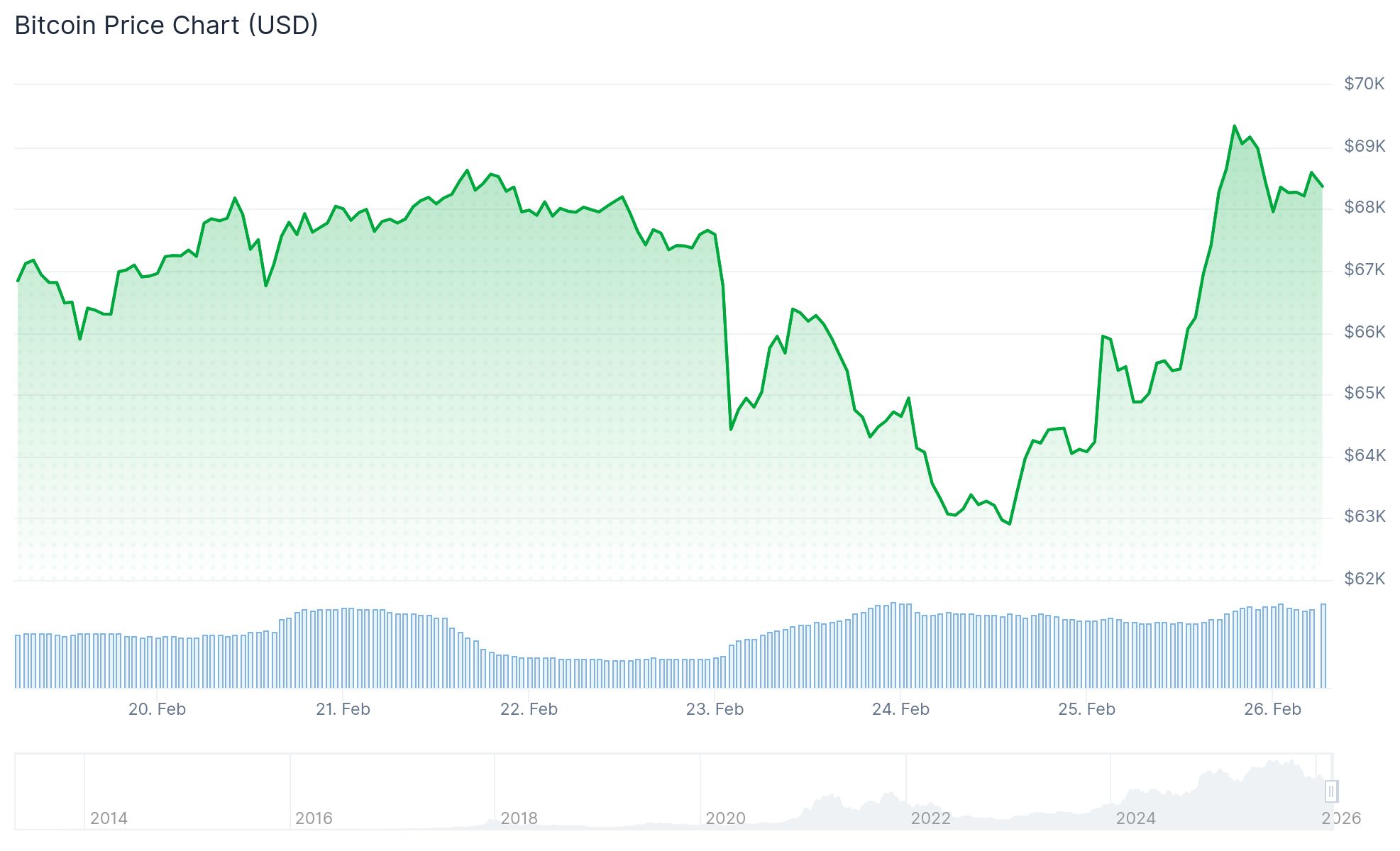
- Analysts say Bitcoin needs to hold above $64,000 and break $66,535 to sustain the move
Bitcoin posted one of its strongest single-day gains of the year on Wednesday, rising nearly 7% to above $68,000. The move added more than $170 billion to the total crypto market cap, pushing it to $2.4 trillion.
 Bitcoin (BTC) Price
Bitcoin (BTC) Price
The rally came as online speculation about trading firm Jane Street went viral. Traders on Crypto X and Reddit had long pointed to a pattern where Bitcoin’s overnight gains disappeared within minutes of the U.S. equity market opening around 10 a.m. Eastern Time.
Since early November, Bitcoin had declined during the first hour of U.S. trading in more than 60% of sessions, often shedding up to 3% in that window. On Dec. 4, it dropped 2.1% within 18 minutes of the S&P 500 opening flat.
The theory was that Jane Street was running an automated algorithm that sold Bitcoin at 10 a.m. daily, suppressing potential rallies and buying back at lower prices.
Investor Mike Alfred added fuel to the story, claiming to have spoken with an internal Jane Street source who said management had ordered an “immediate cessation” of the trading strategy. Alfred wrote that the “10 a.m. algo” had been shut down. CCN reached out to both Alfred and Jane Street but received no response. These claims remain unverified.
 Source: Mike Aldred on X
Source: Mike Aldred on X
Jane Street has denied all allegations, calling them “baseless.”
The Lawsuit Behind the Speculation
The renewed scrutiny follows a lawsuit filed Feb. 23 by the bankruptcy administrator of Terraform Labs. The 83-page complaint accuses Jane Street, co-founder Robert Granieri, and two employees of insider trading and market manipulation before the 2022 TerraUSD collapse, which wiped out roughly $40 billion in market value.
The suit alleges confidential, non-public information from Terraform insiders was shared with Jane Street to front-run trades.
Bloomberg ETF analyst Eric Balchunas commented that if consistent sell pressure had stopped, Bitcoin could see a sustained rebound.
Technical Levels to Watch
Analysts noted Bitcoin’s RSI had recently fallen near 30, an oversold level often associated with short-term relief rallies.
Data from CoinMarketCap showed a 95% correlation between Bitcoin and the S&P 500 over the 24-hour period, suggesting macro conditions also played a role. Wall Street rose that session as AI-related concerns eased ahead of Nvidia earnings.
Bitcoin hit a session high of $69,819 before pulling back. Analysts say it must hold above $64,000 and clear resistance at $66,535 to maintain momentum. A failure to do so could see it retest support near $60,074.
Bitcoin had fallen below $63,000 earlier in the week and remains down nearly 50% from its October record highs.
The post Bitcoin (BTC) Price: BTC Jumps 7% the Day After Jane Street Gets Sued — Coincidence? appeared first on CoinCentral.


You May Also Like

Mark Cuban Says He Sold Most of His Bitcoin, Calling It a Failed Hedge

Blockchain.com Submits Confidential IPO Filing to SEC Amid Crypto Market Revival

What Trump’s 'utterly bonkers' turn of phrase reveals: analysis



