

V-TechHub: Database Locking Made Easy: Guarding Data Integrity Without the Headache
Is your database silently corrupting your bottom line during peak traffic?
In 2026, high-speed applications make race conditions a million-dollar threat to data integrity. When two processes update the same record simultaneously—like an ATM withdrawal hitting at the exact moment as a utility bill payment—the math often fails. Without a precise locking strategy, your system stays vulnerable to expensive errors. Choosing between pessimistic and optimistic locking is a critical business decision for maintaining consistency.
How is your current infrastructure handling these high-stakes collisions? This month, V-TechHub digs into how you can waded through the challenge of data integrity with ease with database locking.
1. The Core Problem
In the world of high-performance apps, speed is king. But what happens when two processes try to be “fast” at the exact same millisecond on the same piece of data? You get a Race Condition.
Imagine Hưng has $1,000 in his bank account. Two things happen simultaneously:
- Thread A: You withdraw $500 at an ATM.
- Thread B: An automated system deducts $700 for your electricity bill.
Without locking, both threads read the balance as $1,000. Thread A finishes and sets the balance to $500. Thread B finishes a millisecond later and sets it to $300. The Disaster: You’ve spent $1,200, but your account still shows $300. The bank just lost $200 because of a lack of Data Consistency.
2. Database storage matter
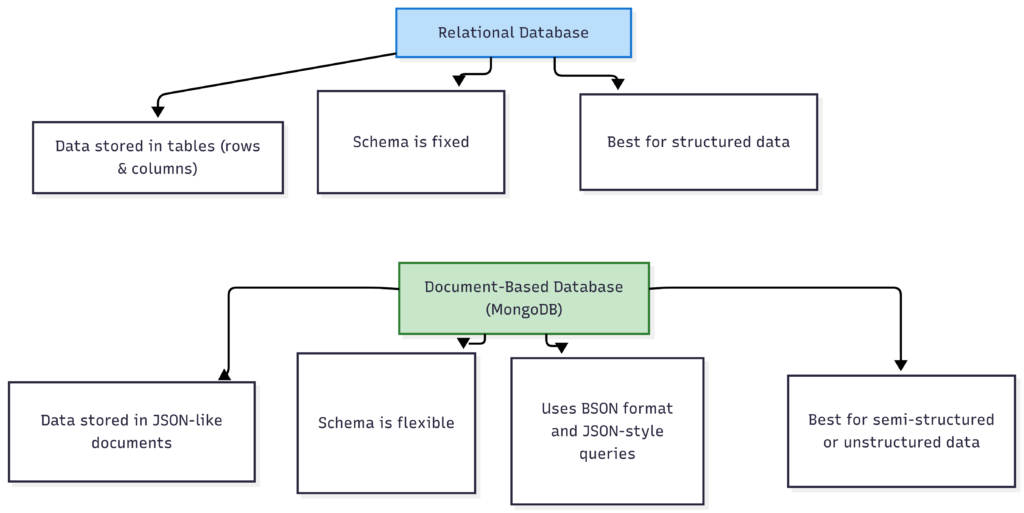
Fixed data-schema offer the best locking efficiency since all the data store in files. The files are under OS management. In addition, fixed-size datatypes offer the best precision to locate where is the data offset.
OS reads the file by using the OFFSET from the beginning of the files. To locking the editing data
- Lock the whole file (lock more than required, low performance)
- Lock a partition of the file by using OFFSET
The above sample code is for locking a partition of the files.
Different databases have different “rules of engagement” for locking:
- SQL (Relational – Postgres, MySQL): These are the “Strict Librarians.” They use Row-based locking. When you edit a row, it’s locked down tight. It’s heavy on ACID compliance, making it the gold standard for financial data.
- NoSQL (Document-based – MongoDB): These are the “Flexible Artists.” Locking usually happens at the Document level. If you update one field in a JSON doc, the whole doc might be locked. It’s built for scale, often favouring Eventual Consistency over immediate lockdown.
- Others column-based, time-series or eventually consistency database (Cassandra) might not provide the locking feature
3. Application vs. Database
Deciding where to put the lock is a classic architectural debate:
- Application-Level Lock: Using Java’s synchronized or a Redis Distributed Lock.
- Pros: Great for offloading work from the DB.
- Cons: If you run a Cluster (multiple server nodes), a local Java lock is useless. You need a centralized “manager” like Redis.
- Optimistic Locking is a strategy for Application layer locking by checking the version
- Database-Level Lock: Using native SQL commands like SELECT … FOR UPDATE.
- Pros: The “Last Line of Defence.” Since the DB is the ultimate source of truth, it’s the most reliable spot.
- Cons: Can become a bottleneck. If too many threads wait for a lock, your app slows down to a crawl.
- Database level lock is depending on the OS features
- It might offer better performance in new OS and hardware (SSD or HDD)
- OS locks the file by Shared lock and Exclusive Lock
4. Strategies: Pessimistic vs. Optimistic Locking
Pessimistic (in JPA or others ORM library)is not always Database lock. It is just a wrapper in Application Layer, the Database might or might not support the Locking.
Thus, please check the Database document for Transactional features.
A. Pessimistic Locking (The “Stop Everything” Approach)
- Philosophy: “I don’t trust anyone; lock it before I even look at it.”
- Mechanism: Prevents any other thread from reading or writing until the transaction is done.
- Best for: High-stakes data (Money, Inventory).
- The Headache: Can cause Deadlocks where two threads wait for each other forever, freezing the system.
- Note: check the Database documentation ( it might not work as the expected )
B. Optimistic Locking (The “Version Control” Approach)
- Philosophy: “Assume everything is fine; check for changes only at the very end.”
- Mechanism: Uses a version column. When updating, it checks: WHERE id = 1 AND version = 5. If someone else changed it to version 6 while you were working, your update fails.
- Best for: High-read, low-write systems (User Profiles, Blogs).
- The Headache: If many people edit at once, you’ll see lots of “Update Failed” errors, forcing users to retry.
5. Summary:
To keep your concurrency debugging easy, follow these rules:
- Money = Pessimistic: If it involves assets, lock it at the DB level.
- Profiles = Optimistic: If it’s mostly for viewing, use a version column.
- Keep Transactions Lean: Never trigger a slow API call (like sending an Email) inside a DB transaction. Lock, update, commit—then do the heavy lifting.
- Order Matters: Always lock resources in the same order (e.g., always lock Table A then Table B) to avoid the dreaded Deadlock.


You May Also Like

Gold continues to hit new highs. How to invest in gold in the crypto market?

SHIB Price Prediction: Critical $0.0000085 Target Emerges as Bears Challenge Bulls




