

ELK, Loki y Graylog eran excesivos, así que construí Log Bull
Durante unos cinco años, me he enfrentado a la tarea de recopilar logs, típicamente de bases de código pequeñas a medianas. Enviar logs desde el código no es un problema: Java y Go tienen bibliotecas para esto prácticamente listas para usar. Pero implementar algo para recopilarlos es un dolor de cabeza. Entiendo que es una tarea solucionable (incluso antes de ChatGPT, y ahora aún más). Sin embargo, todos los sistemas de logging están principalmente orientados hacia el mundo empresarial grande y sus requisitos, en lugar de equipos pequeños o desarrolladores individuales con pocos recursos, pegamento y un plazo de "ayer".
Lanzar ELK es un desafío para mí cada vez: un montón de configuraciones, una implementación no trivial, y cuando entro en la interfaz de usuario, mis ojos se vuelven locos con las pestañas. Con Loki y Graylog, es un poco más fácil, pero todavía hay muchas más características de las que necesito. Al mismo tiempo, separar logs entre proyectos y agregar otros usuarios al sistema para que no vean nada que no deberían, tampoco es el proceso más obvio.
Así que hace aproximadamente un año, decidí crear mi propio sistema de recopilación de logs. Uno que sea lo más fácil de usar y lanzar posible. Se implementaría en el servidor con un solo comando, sin ninguna configuración o pestañas innecesarias en la interfaz. Así es como surgió Log Bull, y ahora es de código abierto: un sistema de recopilación de logs para desarrolladores con proyectos de tamaño mediano.
Tabla de contenidos:
- Acerca del proyecto
- ¿Cómo implementar Log Bull?
- ¿Cómo enviar logs?
- ¿Cómo ver logs?
- Conclusión
Acerca del proyecto
Log Bull es un sistema de recopilación de logs con énfasis en la facilidad de uso (configuración mínima, características mínimas, configuración cero al inicio). El proyecto es completamente de código abierto bajo la licencia Apache 2.0. Mi prioridad principal fue crear una solución que permitiera a un desarrollador junior descubrir fácilmente cómo iniciar el sistema, cómo enviarle logs y cómo verlos en unos 15 minutos.

Características clave del proyecto:
- Implementado con un solo comando a través de un script .sh o un comando Docker.
- Puedes crear múltiples proyectos aislados para recopilar logs (y agregar usuarios a ellos).
- Interfaz extremadamente simple con configuración mínima, y sin configuración requerida al iniciar (configuración cero).
- Bibliotecas para Python, Java, Go, JavaScript (TS \ NodeJS), PHP, C#. Rust y Ruby están planificados.
- Gratuito, de código abierto y autoalojado.
- No es necesario conocer LogQL, Kibana DSL u otros lenguajes de consulta para buscar logs.
https://www.youtube.com/watch?v=8H8jF8nVzJE&embedable=true
El proyecto está desarrollado en Go y construido sobre OpenSearch.
Sitio web del proyecto - https://logbull.com
GitHub del proyecto - https://github.com/logbull/logbull
P.D. Si encuentras útil el proyecto y tienes una cuenta de GitHub, por favor dale una estrella ⭐️. Las primeras estrellas son difíciles de conseguir. ¡Estaría extremadamente agradecido por tu apoyo!
¿Cómo implementar Log Bull?
Hay tres formas de implementar un proyecto: a través de un script .sh (que recomiendo), a través de Docker y a través de Docker Compose.
Método 1: Instalación a través de script
El script instalará Docker, colocará el proyecto en la carpeta /opt/logbull y configurará el inicio automático cuando se reinicie el sistema. Comando de instalación:
sudo apt-get install -y curl && \ sudo curl -sSL https://raw.githubusercontent.com/logbull/logbull/main/install-logbull.sh \ | sudo bash Método 2: Lanzamiento a través de Docker Compose
Crea el archivo docker-compose.yml con el siguiente contenido:
services: logbull: container_name: logbull image: logbull/logbull:latest ports: - "4005:4005" volumes: - ./logbull-/logbull-data restart: unless-stopped healthcheck: test: ["CMD", "curl", "-f", "http://localhost:4005/api/v1/system/health"] interval: 5s timeout: 5s retries: 30 Y ejecuta el comando docker compose up -d. El sistema se iniciará en el puerto 4005.
Método 3: Lanzamiento a través del comando Docker
Ejecuta el siguiente comando en la terminal (el sistema también se iniciará en el puerto 4005):
docker run -d \ --name logbull \ -p 4005:4005 \ -v ./logbull-/logbull-data \ --restart unless-stopped \ --health-cmd="curl -f http://localhost:4005/api/v1/system/health || exit 1" \ --health-interval=5s \ --health-retries=30 \ logbull/logbull:latest ¿Cómo enviar logs?
Diseñé el proyecto pensando en la conveniencia, principalmente para desarrolladores. Por eso creé bibliotecas para la mayoría de los lenguajes de desarrollo populares. Lo hice con la idea de que Log Bull puede conectarse a cualquier biblioteca popular como procesador sin cambiar la base de código actual.
Recomiendo encarecidamente revisar los ejemplos en el sitio web, porque hay un panel interactivo para seleccionar un idioma:
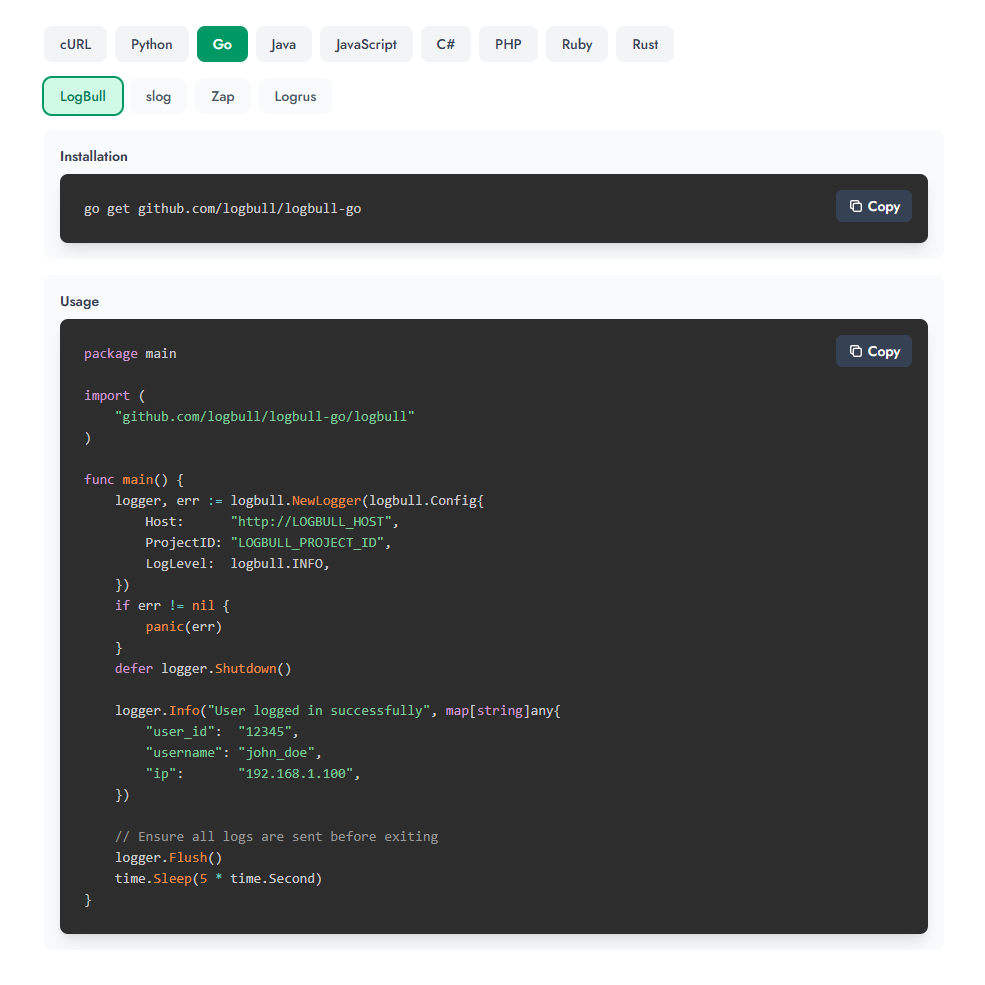
Tomemos Python como ejemplo. Primero, necesitas instalar la biblioteca (aunque también puedes enviarla a través de HTTP; hay ejemplos para cURL):
pip install logbull Luego envía desde el código:
import time from logbull import LogBullLogger # Initialize logger logger = LogBullLogger( host="http://LOGBULL_HOST", project_id="LOGBULL_PROJECT_ID", ) # Log messages (printed to console AND sent to LogBull) logger.info("User logged in successfully", fields={ "user_id": "12345", "username": "john_doe", "ip": "192.168.1.100" }) # With context session_logger = logger.with_context({ "session_id": "sess_abc123", "user_id": "user_456" }) session_logger.info("Processing request", fields={ "action": "purchase" }) # Ensure all logs are sent before exiting logger.flush() time.sleep(5) ¿Cómo ver logs?
Todos los logs se muestran inmediatamente en la pantalla principal. Puedes:
-
Reducir el tamaño de los mensajes (cortando la línea a ~50-100 caracteres).
-
Expandir la lista de campos enviados (user_id, order_id, etc.).
-
Hacer clic en un campo y agregarlo al filtro. Búsqueda de logs con condiciones:
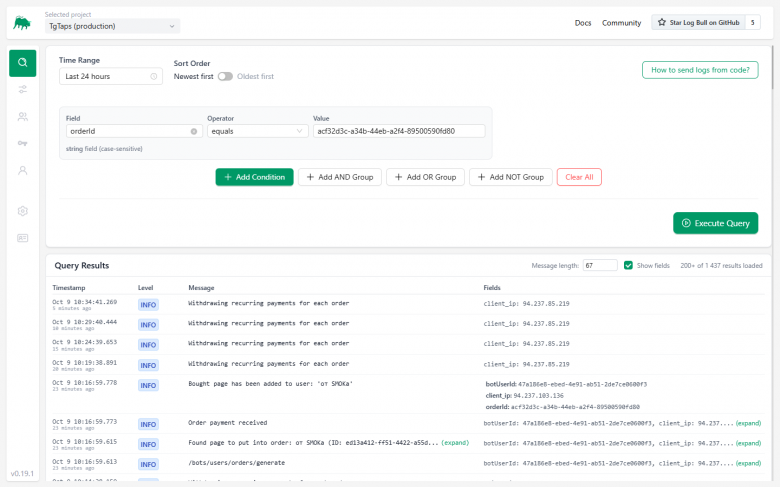
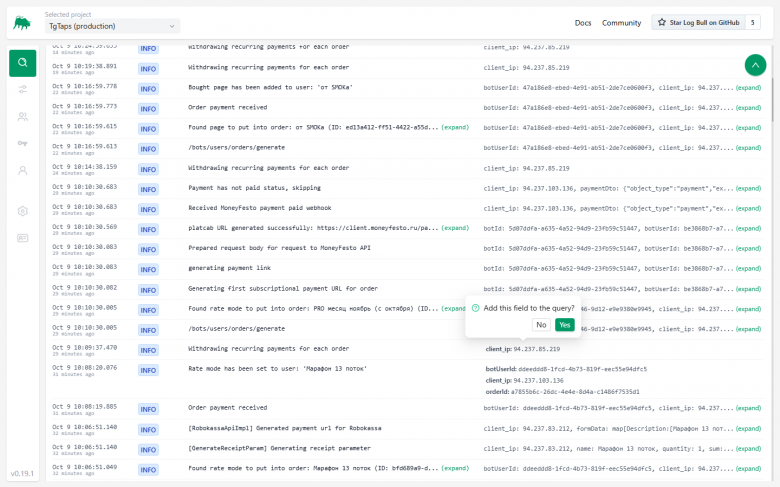
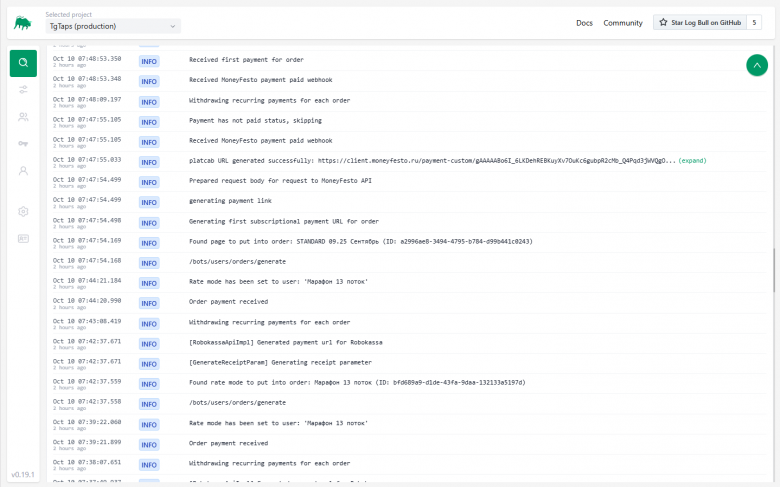
También puedes recopilar grupos de condiciones (por ejemplo, el mensaje incluye cierto texto, pero excluye una dirección IP de servidor específica).
Conclusión
Espero que mi sistema de recopilación de logs sea útil para aquellos desarrolladores que no quieren o no pueden (debido a recursos limitados del proyecto) implementar soluciones "pesadas" como ELK. Ya estoy usando Log Bull en proyectos de producción, y todo va bien. Agradezco comentarios, sugerencias de mejora y problemas en GitHub.


También te puede interesar

Kalshi Gana: El Tercer Circuito Otorga Victoria al Mercado de Predicción

MACD Gira al Alza, se Mantiene en $2.1K




