

Enseñando a la IA a Ver y Hablar: Dentro del Enfoque OW‑VISCap
Tabla de Enlaces
Resumen y 1. Introducción
-
Trabajo Relacionado
2.1 Segmentación de Instancias de Video de Mundo Abierto
2.2 Subtitulación Densa de Objetos en Video y 2.3 Pérdida Contrastiva para Consultas de Objetos
2.4 Comprensión Generalizada de Video y 2.5 Segmentación de Instancias de Video de Mundo Cerrado
-
Enfoque
3.1 Visión General
3.2 Consultas de Objetos de Mundo Abierto
3.3 Cabeza de Subtitulación
3.4 Pérdida Contrastiva Entre Consultas y 3.5 Entrenamiento
-
Experimentos y 4.1 Conjuntos de Datos y Métricas de Evaluación
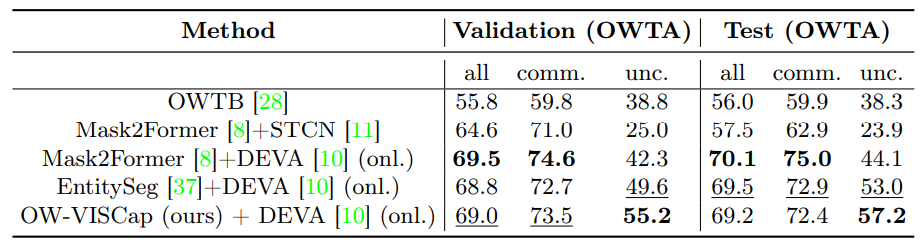
4.2 Resultados Principales
4.3 Estudios de Ablación y 4.4 Resultados Cualitativos
-
Conclusión, Agradecimientos y Referencias
\ Material Suplementario
A. Análisis Adicional
B. Detalles de Implementación
C. Limitaciones
3 Enfoque
Dado un video, nuestro objetivo es detectar, segmentar y subtitular conjuntamente las instancias de objetos presentes en el video. Es importante destacar que las categorías de instancias de objetos pueden no formar parte del conjunto de entrenamiento (por ejemplo, los paracaídas mostrados en la Fig. 3 (fila superior)), situando nuestro objetivo en un entorno de mundo abierto. Para lograr este objetivo, un video dado se divide primero en clips cortos, cada uno compuesto por T fotogramas. Cada clip se procesa utilizando nuestro enfoque OW-VISCap. Discutimos la fusión de los resultados de cada clip en la Sec. 4.
\ Proporcionamos una visión general de OW-VISCap para procesar cada clip en la Sec. 3.1. Luego discutimos nuestras contribuciones: (a) introducción de consultas de objetos de mundo abierto en la Sec. 3.2, (b) uso de atención enmascarada para subtitulación centrada en objetos en la Sec. 3.3, y (c) uso de pérdida contrastiva entre consultas para garantizar que las consultas de objetos sean diferentes entre sí en la Sec. 3.4. En la Sec. 3.5, discutimos el objetivo final de entrenamiento.
3.1 Visión General
\ Tanto las consultas de objetos de mundo abierto como de mundo cerrado son procesadas por nuestra cabeza de subtitulación específicamente diseñada que produce un subtítulo centrado en el objeto, una cabeza de clasificación que produce una etiqueta de categoría, y una cabeza de detección que produce ya sea una máscara de segmentación o un cuadro delimitador.
\ 
\ Introducimos una pérdida contrastiva entre consultas para garantizar que se fomente que las consultas de objetos difieran entre sí. Proporcionamos detalles en la Sec. 3.4. Para objetos de mundo cerrado, esta pérdida ayuda a eliminar falsos positivos altamente superpuestos. Para objetos de mundo abierto, ayuda en el descubrimiento de nuevos objetos.
\ Finalmente, proporcionamos el objetivo completo de entrenamiento en la Sec. 3.5.
\
3.2 Consultas de Objetos de Mundo Abierto
\ 
\ 
\ Primero emparejamos los objetos de verdad fundamental con las predicciones de mundo abierto minimizando un costo de emparejamiento utilizando el algoritmo húngaro [34]. El emparejamiento óptimo se utiliza luego para calcular la pérdida final de mundo abierto.
\ 
\
3.3 Cabeza de Subtitulación
\ 
\
3.4 Pérdida Contrastiva Entre Consultas
\ 
\
3.5 Entrenamiento
Nuestra pérdida total de entrenamiento es
\ 
\ ![Tabla 2: Resultados de subtitulación densa de objetos de video en el conjunto de datos VidSTG [57]. Off. indica métodos fuera de línea y onl. se refiere a métodos en línea.](https://cdn.hackernoon.com/images/null-0v3336a.png)
\
:::info Autores:
(1) Anwesa Choudhuri, Universidad de Illinois en Urbana-Champaign (anwesac2@illinois.edu);
(2) Girish Chowdhary, Universidad de Illinois en Urbana-Champaign (girishc@illinois.edu);
(3) Alexander G. Schwing, Universidad de Illinois en Urbana-Champaign (aschwing@illinois.edu).
:::
:::info Este artículo está disponible en arxiv bajo la licencia CC by 4.0 Deed (Atribución 4.0 Internacional).
:::
\





