

Solución a la escasez de datos: S-CycleGAN para la traducción de TC a ultrasonido
Tabla de enlaces
Abstracto y 1 Introducción
-
Trabajos relacionados
-
Configuración del problema
-
Metodología
4.1. Destilación consciente del límite de decisión
4.2. Consolidación del conocimiento
-
Resultados experimentales y 5.1. Configuración del experimento
5.2. Comparación con métodos SOTA
5.3. Estudio de ablación
-
Conclusión y trabajo futuro y Referencias
\
Material Suplementario
- Detalles del análisis teórico sobre el mecanismo KCEMA en IIL
- Visión general del algoritmo
- Detalles del conjunto de datos
- Detalles de implementación
- Visualización de imágenes de entrada con polvo
- Más resultados experimentales
Abstracto
El aprendizaje incremental de instancias (IIL) se centra en aprender continuamente con datos de las mismas clases. En comparación con el aprendizaje incremental de clases (CIL), el IIL es poco explorado porque sufre menos del olvido catastrófico (CF). Sin embargo, además de retener conocimiento, en escenarios de implementación del mundo real donde el espacio de clases siempre está predefinido, la promoción continua y rentable del modelo con la posible indisponibilidad de datos anteriores es una demanda más esencial. Por lo tanto, primero definimos una configuración IIL nueva y más práctica como promover el rendimiento del modelo además de resistir CF solo con nuevas observaciones. Dos problemas deben abordarse en la nueva configuración IIL: 1) el notorio olvido catastrófico debido a la falta de acceso a datos antiguos, y 2) ampliar el límite de decisión existente a nuevas observaciones debido a la deriva conceptual. Para abordar estos problemas, nuestra idea clave es ampliar moderadamente el límite de decisión para los casos fallidos mientras se mantiene el límite antiguo. Por lo tanto, proponemos un nuevo método de destilación consciente del límite de decisión con consolidación de conocimiento al maestro para facilitar que el estudiante aprenda nuevo conocimiento. También establecemos los puntos de referencia en conjuntos de datos existentes Cifar-100 e ImageNet. Notablemente, experimentos extensos demuestran que el modelo maestro puede ser un mejor aprendiz incremental que el modelo estudiante, lo que revierte los métodos anteriores basados en destilación de conocimiento que tratan al estudiante como el papel principal.
1. Introducción
En los últimos años, se han propuesto muchas excelentes redes basadas en aprendizaje profundo para una variedad de tareas, como clasificación de imágenes, segmentación y detección. Aunque estas redes funcionan bien con los datos de entrenamiento, inevitablemente fallan en algunos datos nuevos que no se entrenan en aplicaciones del mundo real. Promover continua y eficientemente el rendimiento de un modelo implementado en estos nuevos datos es una demanda esencial. La solución actual de reentrenar la red utilizando todos los datos acumulados tiene dos inconvenientes: 1) con el aumento del tamaño de los datos, el costo de entrenamiento se vuelve más alto cada vez, por ejemplo, más horas de GPU y mayor huella de carbono [20], y 2) en algunos casos, los datos antiguos ya no son accesibles debido a la política de privacidad o presupuesto limitado para almacenamiento de datos. En el caso donde solo hay disponible o se utiliza poco o ningún dato antiguo, reentrenar el modelo de aprendizaje profundo con datos nuevos siempre causa degradación del rendimiento en los datos antiguos, es decir, el problema de olvido catastrófico (CF). Para abordar el problema CF, se propone el aprendizaje incremental [4, 5, 22, 29], también conocido como aprendizaje continuo. El aprendizaje incremental promueve significativamente el valor práctico de los modelos de aprendizaje profundo y está atrayendo intensos intereses de investigación.
\ 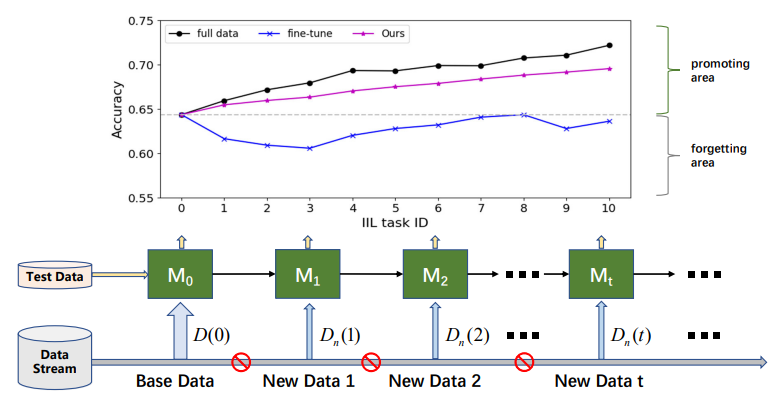
\ Según si los nuevos datos provienen de clases vistas, el aprendizaje incremental se puede dividir en tres escenarios [16, 17]: aprendizaje incremental de instancias (IIL) [3, 16] donde todos los nuevos datos pertenecen a las clases vistas, aprendizaje incremental de clases (CIL) [4, 12, 15, 22] donde los nuevos datos tienen diferentes etiquetas de clase, y aprendizaje incremental híbrido [6, 30] donde los nuevos datos consisten en nuevas observaciones de clases antiguas y nuevas. En comparación con CIL, IIL está relativamente inexplorado porque es menos susceptible al CF. Lomonaco y Maltoni [16] informaron que el ajuste fino de un modelo con parada temprana puede domar bien el problema CF en IIL. Sin embargo, esta conclusión no siempre se mantiene cuando no hay acceso a los datos de entrenamiento antiguos y los nuevos datos tienen un tamaño mucho menor que los datos antiguos, como se muestra en la Fig. 1. El ajuste fino a menudo resulta en un cambio en el límite de decisión en lugar de expandirlo para acomodar nuevas observaciones. Además de retener el conocimiento antiguo, la implementación real se preocupa más por la promoción eficiente del modelo en IIL. Por ejemplo, en la detección de defectos de productos industriales, las clases de defectos siempre están limitadas a categorías conocidas. Pero la morfología de esos defectos varía de vez en cuando. Los fallos en esos defectos no vistos deben corregirse de manera oportuna y eficiente para evitar que los productos defectuosos fluyan hacia el mercado. Desafortunadamente, la investigación existente se centra principalmente en retener el conocimiento sobre datos antiguos en lugar de enriquecer el conocimiento con nuevas observaciones.
\ En este artículo, para mejorar de manera rápida y rentable un modelo entrenado con nuevas observaciones de clases vistas, primero definimos una nueva configuración IIL como retener el conocimiento aprendido y promover el rendimiento del modelo en nuevas observaciones sin acceso a datos antiguos. En palabras simples, nuestro objetivo es promover el modelo existente aprovechando solo los nuevos datos y lograr un rendimiento comparable al modelo reentrenado con todos los datos acumulados. El nuevo IIL es desafiante debido a la deriva conceptual [6] causada por las nuevas observaciones, como la variación de color o forma en comparación con los datos antiguos. Por lo tanto, dos problemas deben abordarse en la nueva configuración IIL: 1) el notorio olvido catastrófico debido a la falta de acceso a datos antiguos, y 2) ampliar el límite de decisión existente a nuevas observaciones.
\ Para abordar los problemas anteriores en la nueva configuración IIL, proponemos un nuevo marco IIL basado en la estructura maestro-estudiante. El marco propuesto consiste en un proceso de destilación consciente del límite de decisión (DBD) y un proceso de consolidación de conocimiento (KC). El DBD permite que el modelo estudiante aprenda de nuevas observaciones con conciencia de los límites de decisión entre clases existentes, lo que permite al modelo determinar dónde fortalecer su conocimiento y dónde retenerlo. Sin embargo, el límite de decisión es imposible de rastrear cuando hay muestras insuficientes ubicadas alrededor del límite debido a la falta de acceso a los datos antiguos en IIL. Para superar esto, nos inspiramos en la práctica de espolvorear el suelo con harina para revelar huellas ocultas. De manera similar, introducimos ruido gaussiano aleatorio para contaminar el espacio de entrada y manifestar el límite de decisión aprendido para la destilación. Durante el entrenamiento del modelo estudiante con destilación de límites, el conocimiento actualizado se consolida aún más en el modelo maestro de manera intermitente y repetida con el mecanismo EMA [28]. Utilizar el modelo maestro como modelo objetivo es un intento pionero y su viabilidad se explica teóricamente.
\ De acuerdo con la nueva configuración IIL, reorganizamos el conjunto de entrenamiento de algunos conjuntos de datos existentes comúnmente utilizados en CIL, como Cifar-100 [11] e ImageNet [24] para establecer los puntos de referencia. El modelo se evalúa en los datos de prueba, así como en los datos base no disponibles en cada fase incremental. Nuestras principales contribuciones se pueden resumir de la siguiente manera: 1) Definimos una nueva configuración IIL para buscar una promoción rápida y rentable del modelo en nuevas observaciones y establecer puntos de referencia; 2) Proponemos un nuevo método de destilación consciente del límite de decisión para retener el conocimiento aprendido y enriquecerlo con nuevos datos; 3) Consolidamos creativamente el conocimiento aprendido del estudiante al modelo maestro para lograr un mejor rendimiento y generalización, y demostramos la viabilidad teóricamente; y 4) Experimentos extensos demuestran que el método propuesto acumula bien el conocimiento solo con nuevos datos, mientras que la mayoría de los métodos de aprendizaje incremental existentes fallaron.
\
:::info Este artículo está disponible en arxiv bajo la licencia CC BY-NC-ND 4.0 Deed (Atribución-NoComercial-SinDerivadas 4.0 Internacional).
:::
:::info Autores:
(1) Qiang Nie, Universidad de Ciencia y Tecnología de Hong Kong (Guangzhou);
(2) Weifu Fu, Tencent Youtu Lab;
(3) Yuhuan Lin, Tencent Youtu Lab;
(4) Jialin Li, Tencent Youtu Lab;
(5) Yifeng Zhou, Tencent Youtu Lab;
(6) Yong Liu, Tencent Youtu Lab;
(7) Qiang Nie, Universidad de Ciencia y Tecnología de Hong Kong (Guangzhou);
(8) Chengjie Wang, Tencent Youtu Lab.
:::
\





