

Síntesis de Imágenes Médicas: S-CycleGAN para RUSS y Segmentación
Tabla de Enlaces
Abstracto y 1 Introducción
-
Trabajos relacionados
-
Configuración del problema
-
Metodología
4.1. Destilación consciente del límite de decisión
4.2. Consolidación de conocimiento
-
Resultados experimentales y 5.1. Configuración del experimento
5.2. Comparación con métodos SOTA
5.3. Estudio de ablación
-
Conclusión y trabajo futuro y Referencias
\
Material Suplementario
- Detalles del análisis teórico sobre el mecanismo KCEMA en IIL
- Visión general del algoritmo
- Detalles del conjunto de datos
- Detalles de implementación
- Visualización de imágenes de entrada con polvo
- Más resultados experimentales
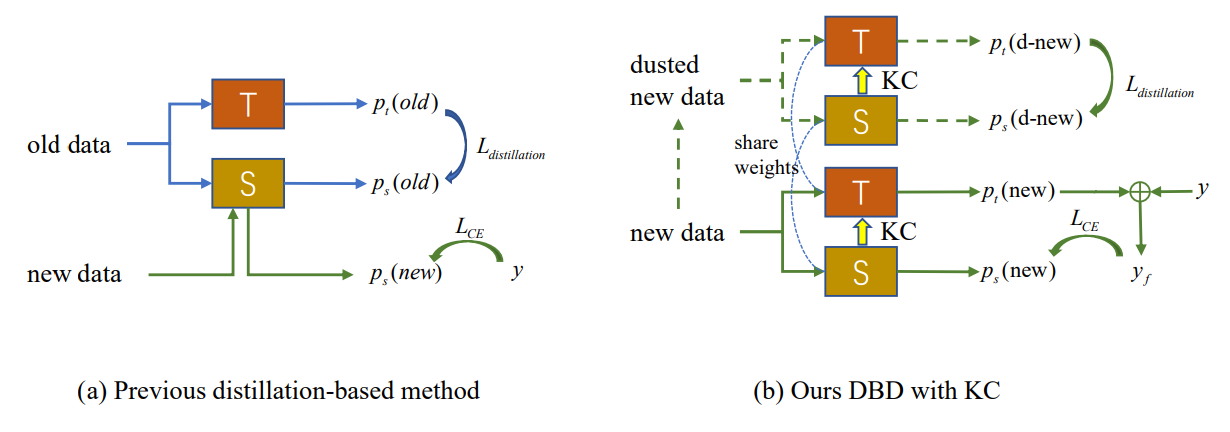
4. Metodología
Como se muestra en la Fig. 2 (a), la aparición de deriva conceptual en nuevas observaciones conduce a la emergencia de muestras externas en las que el modelo existente falla. El nuevo IIL tiene que ampliar el límite de decisión a estas muestras externas, así como evitar el olvido catastrófico (CF) en el límite antiguo. Los métodos convencionales basados en destilación de conocimiento dependen de algunos ejemplares preservados [22] o datos auxiliares [33, 34] para resistir el CF. Sin embargo, en la configuración IIL propuesta, no tenemos acceso a ningún dato antiguo aparte de las nuevas observaciones. La destilación basada en estas nuevas observaciones entra en conflicto con el aprendizaje de nuevo conocimiento si no se añaden nuevos parámetros al modelo. Para lograr un equilibrio entre aprender y no olvidar, proponemos un método de destilación consciente del límite de decisión que no requiere datos antiguos. Durante el aprendizaje, el nuevo conocimiento aprendido por el estudiante se consolida intermitentemente de vuelta al modelo del profesor, lo que proporciona una mejor generalización y es un intento pionero en esta área.
\ 
\
:::info Autores:
(1) Qiang Nie, Universidad de Ciencia y Tecnología de Hong Kong (Guangzhou);
(2) Weifu Fu, Tencent Youtu Lab;
(3) Yuhuan Lin, Tencent Youtu Lab;
(4) Jialin Li, Tencent Youtu Lab;
(5) Yifeng Zhou, Tencent Youtu Lab;
(6) Yong Liu, Tencent Youtu Lab;
(7) Qiang Nie, Universidad de Ciencia y Tecnología de Hong Kong (Guangzhou);
(8) Chengjie Wang, Tencent Youtu Lab.
:::
:::info Este artículo está disponible en arxiv bajo la licencia CC BY-NC-ND 4.0 Deed (Atribución-NoComercial-SinDerivadas 4.0 Internacional).
:::
\


También te puede interesar

Proveedor de Seguridad Web3 Certik Abre el Acceso a su Herramienta de Auditoría con IA para Desarrolladores Globales – Noticias de Tecnología Bitcoin

El portafolio de acciones impulsado por IA Claude acaba de realizar estas operaciones




