

Haga que sus canalizaciones de datos sean 5 veces más rápidas con el procesamiento adaptativo por lotes
¿Tiene llamadas masivas a LLM en su flujo de transformación de datos?
CocoIndex podría ayudarle. Está impulsado por un motor Rust de ultra rendimiento y ahora soporta procesamiento en lotes adaptativo de forma inmediata. Esto ha mejorado el rendimiento en ~5× (≈80% más rápido en tiempo de ejecución) para flujos de trabajo nativos de IA. Y lo mejor de todo, no necesita cambiar ningún código porque el procesamiento en lotes ocurre automáticamente, adaptándose a su tráfico y manteniendo las GPUs completamente utilizadas.
Esto es lo que aprendimos mientras construíamos soporte de procesamiento en lotes adaptativo en Cocoindex.
Pero primero, respondamos algunas preguntas que podrían estar en su mente.
¿Por qué el procesamiento en lotes acelera el procesamiento?
-
Sobrecarga fija por llamada: Esto consiste en todo el trabajo preparatorio y administrativo requerido antes de que el cálculo real pueda comenzar. Los ejemplos incluyen la configuración de lanzamiento del kernel de GPU, transiciones de Python a C/C++, programación de tareas, asignación y gestión de memoria, y el mantenimiento de registros realizado por el framework. Estas tareas de sobrecarga son en gran parte independientes del tamaño de entrada pero deben pagarse por completo para cada llamada.
\
-
Trabajo dependiente de datos: Esta porción del cálculo escala directamente con el tamaño y complejidad de la entrada. Incluye operaciones de punto flotante (FLOPs) realizadas por el modelo, movimiento de datos a través de jerarquías de memoria, procesamiento de tokens y otras operaciones específicas de entrada. A diferencia de la sobrecarga fija, este costo aumenta proporcionalmente con el volumen de datos que se procesan.
Cuando los elementos se procesan individualmente, la sobrecarga fija se incurre repetidamente para cada elemento, lo que puede dominar rápidamente el tiempo total de ejecución, especialmente cuando el cálculo por elemento es relativamente pequeño. En contraste, procesar múltiples elementos juntos en lotes reduce significativamente el impacto por elemento de esta sobrecarga. El procesamiento en lotes permite que los costos fijos se amorticen entre muchos elementos, mientras también habilita optimizaciones de hardware y software que mejoran la eficiencia del trabajo dependiente de datos. Estas optimizaciones incluyen una utilización más efectiva de los pipelines de GPU, mejor utilización de caché, y menos lanzamientos de kernel, todo lo cual contribuye a un mayor rendimiento y menor latencia general.
\
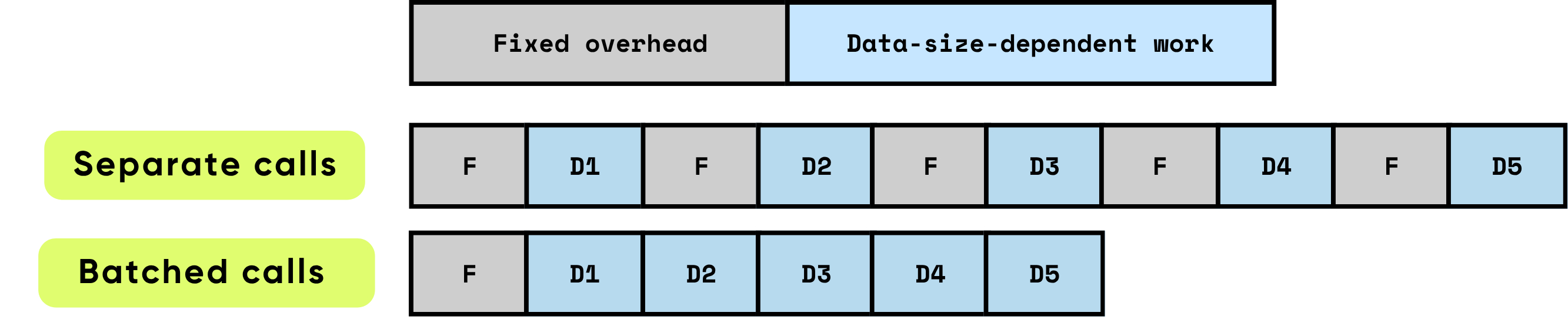
\ El procesamiento en lotes mejora significativamente el rendimiento al optimizar tanto la eficiencia computacional como la utilización de recursos. Proporciona múltiples beneficios compuestos:
\
-
Amortización de sobrecarga única: Cada función o llamada API conlleva una sobrecarga fija — lanzamientos de kernel GPU, transiciones de Python a C/C++, programación de tareas, gestión de memoria y mantenimiento de registros del framework. Al procesar elementos en lotes, esta sobrecarga se distribuye entre muchas entradas, reduciendo dramáticamente el costo por elemento y eliminando trabajo de configuración repetido.
\
-
Maximizando la eficiencia de GPU: Lotes más grandes permiten a la GPU ejecutar operaciones como multiplicaciones de matrices densas y altamente paralelas, comúnmente implementadas como Multiplicación de Matriz-Matriz General (GEMM). Este mapeo asegura que el hardware funcione con mayor utilización, aprovechando completamente las unidades de cómputo paralelas, minimizando ciclos inactivos y logrando un rendimiento máximo. Las operaciones pequeñas y sin procesar en lotes dejan gran parte de la GPU subutilizada, desperdiciando capacidad computacional costosa.
\
-
Reduciendo la sobrecarga de transferencia de datos: El procesamiento en lotes minimiza la frecuencia de transferencias de memoria entre CPU (host) y GPU (dispositivo). Menos operaciones Host-a-Dispositivo (H2D) y Dispositivo-a-Host (D2H) significan menos tiempo dedicado a mover datos y más tiempo dedicado al cálculo real. Esto es crítico para sistemas de alto rendimiento, donde el ancho de banda de memoria a menudo se convierte en el factor limitante en lugar de la potencia de cómputo bruta.
En combinación, estos efectos conducen a mejoras de órdenes de magnitud en el rendimiento. El procesamiento en lotes transforma muchos cálculos pequeños e ineficientes en operaciones grandes y altamente optimizadas que explotan completamente las capacidades del hardware moderno. Para cargas de trabajo de IA — incluyendo modelos de lenguaje grandes, visión por computadora y procesamiento de datos en tiempo real — el procesamiento en lotes no es solo una optimización; es esencial para lograr un rendimiento escalable de nivel de producción.
\
Cómo se ve el procesamiento en lotes para código Python normal
Código sin procesamiento en lotes – simple pero menos eficiente
La forma más natural de organizar un pipeline es procesar datos pieza por pieza. Por ejemplo, un bucle de dos capas como este:
for file in os.listdir(directory): content = file.read() chunks = split_into_chunks(content) for chunk in chunks: vector = model.encode([chunk.text]) # one item at a time index.upsert(file_id=file.name, chunk_offset=chunk.offset, vector=vector)
Esto es fácil de leer y razonar: cada fragmento fluye directamente a través de múltiples pasos.
Procesamiento en lotes manual – más eficiente pero complicado
Puede acelerarlo mediante el procesamiento en lotes, pero incluso la versión más simple de "procesar todo en lotes de una vez" hace que el código sea significativamente más complicado:
\
# 1) Collect payloads and remember where each came from batch_texts = [] metadata = [] # (file_id, chunk_id) for file in os.listdir(directory): content = file.read() chunks = split_into_chunks(content) for chunk in chunks: batch_texts.append(chunk.text) metadata.append((file.name, chunk.offset)) # 2) One batched call (library will still mini-batch internally) vectors = model.encode(batch_texts) # 3) Zip results back to their sources for (file_name, chunk_offset), vector in zip(metadata, vectors): index.upsert(file_id=file.name, chunk_offset=chunk.offset, vector=vector)
Además, procesar todo en lotes a la vez generalmente no es ideal porque los siguientes pasos solo pueden comenzar después de que este paso se complete para todos los datos.
Soporte de procesamiento en lotes de CocoIndex
CocoIndex cierra la brecha y le permite obtener lo mejor de ambos mundos – mantener la simplicidad de su código siguiendo el flujo natural, mientras obtiene la eficiencia del procesamiento en lotes proporcionado por el tiempo de ejecución de CocoIndex.
Ya habilitamos soporte de procesamiento en lotes para las siguientes funciones incorporadas:
- EmbedText
- SentenceTransformerEmbed
- ColPaliEmbedImage
- ColPaliEmbedQuery
No cambia la API. Su código existente funcionará sin ningún cambio – siguiendo aún el flujo natural, mientras disfruta de la eficiencia del procesamiento en lotes.
Para funciones personalizadas, habilitar el procesamiento en lotes es tan simple como:
- Establecer
batching=Trueen el decorador de función personalizada. - Cambiar los argumentos y el tipo de retorno a
list.
Por ejemplo, si desea crear una función personalizada que llame a una API para construir miniaturas para imágenes.
@cocoindex.op.function(batching=True) def make_image_thumbnail(self, args: list[bytes]) -> list[bytes]: ...
:::tip Vea la documentación de procesamiento en lotes para más detalles.
:::
Cómo CocoIndex procesa en lotes
Enfoques comunes
El procesamiento en lotes funciona recolectando solicitudes entrantes en una cola y decidiendo el momento adecuado para vaciarlas como un solo lote. Ese tiempo es crucial — si lo hace bien, equilibra el rendimiento, la latencia y el uso de recursos a la vez.
Dos políticas de procesamiento en lotes ampliamente utilizadas dominan el panorama:
- Procesamiento en lotes basado en tiempo (vaciar cada W milisegundos): En este enfoque, el sistema vacía todas las solicitudes que llegaron dentro de una ventana fija de W milisegundos.
-
Ventajas: El tiempo máximo de espera para cualquier solicitud es predecible, y la implementación es sencilla. Asegura que incluso durante tráfico bajo, las solicitudes no permanecerán en la cola indefinidamente.
-
Desventajas: Durante períodos de tráfico escaso, las solicitudes inactivas se acumulan lentamente, añadiendo latencia para las llegadas tempranas. Además, la ventana óptima W a menudo varía con las características de la carga de trabajo, requiriendo un ajuste cuidadoso para lograr el equilibrio adecuado entre latencia y rendimiento.
\
- Procesamiento en lotes basado en tamaño (vaciar cuando K elementos están en cola): Aquí, un lote se activa una vez que la cola alcanza un número predefinido de elementos, K.
- Ventajas: El tamaño del lote es predecible, lo que simplifica la gestión de memoria y el diseño del sistema. Es fácil razonar sobre los recursos que cada lote consumirá.
- Desventajas: Cuando el tráfico es ligero, las solicitudes pueden permanecer en la cola por un período extendido, aumentando la latencia para los primeros elementos que llegan. Al igual que el procesamiento en lotes basado en tiempo, el K óptimo depende de los patrones de carga de trabajo, requiriendo ajuste empírico.
Muchos sistemas de alto rendimiento adoptan un enfoque híbrido: vacían un lote cuando la ventana de tiempo W expira o la cola alcanza el tamaño K — lo que ocurra primero. Esta estrategia captura los beneficios de ambos métodos, mejorando la capacidad de respuesta durante tráfico escaso mientras mantiene tamaños de lote eficientes durante carga máxima.
A pesar de esto, el procesamiento en lotes siempre involucra parámetros ajustables y compensaciones. Los patrones de tráfico, características de carga de trabajo y restricciones del sistema influyen en la configuración ideal. Lograr un rendimiento óptimo a menudo requiere monitoreo, perfilado y ajuste dinámico de estos parámetros para alinearse con las condiciones en tiempo real.
Enfoque de CocoIndex
Nivel de framework: adaptativo, sin ajustes
CocoIndex implementa un mecanismo de procesamiento en lotes simple y natural que se adapta automáticamente a la carga de solicitudes entrantes. El proceso funciona de la siguiente manera:
\
- Cola continua: Mientras el lote actual está siendo procesado en el dispositivo (por ejemplo, GPU), cualquier nueva solicitud entrante no se procesa inmediatamente. En su lugar, se ponen en cola. Esto permite que el sistema acumule trabajo sin interrumpir el cálculo en curso.
- Ventana de lote automática: Cuando el lote actual se completa, CocoIndex toma inmediatamente todas las solicitudes que se han acumulado en la cola y las trata como el siguiente lote. Este conjunto de solicitudes forma la nueva ventana de lote. El sistema luego comienza a procesar este lote de inmediato.
- Procesamiento en lotes adaptativo: No hay temporizadores, tamaños de lote fijos ni umbrales preconfigurados. El tamaño de cada lote se adapta naturalmente al tráfico que llegó durante el tiempo de servicio del lote anterior. Los períodos de alto tráfico producen automáticamente lotes más grandes, maximizando la utilización de la GPU. Los períodos de bajo tráfico producen lotes más pequeños, minimizando la latencia para las solicitudes tempranas.
En esencia, el mecanismo de procesamiento en lotes de CocoIndex es autoajustable. Procesa continuamente solicitudes en lotes mientras permite que el tamaño del lote refleje la demanda en tiempo real, logrando un alto rendimiento sin requerir ajuste manual o heurísticas complejas.



También te puede interesar

Opciones de cripto valoradas en $2.2B expiran mientras BTC mejora y las señales de ETH se fortalecen

El gobierno de EE. UU. transfiere $177K en Bitcoin incautado a Coinbase Prime




