

L'importance de la Désimbrication : SAGE Surpasse les Références VQ-VAE Unifiées dans le Mouvement du Corps Entier
Table des liens
Abstrait et 1. Introduction
-
Travaux connexes
2.1. Reconstruction de mouvement à partir d'entrées éparses
2.2. Génération de mouvement humain
-
SAGE: Génération d'avatar stratifiée et 3.1. Énoncé du problème et notation
3.2. Représentation de mouvement désenchevêtrée
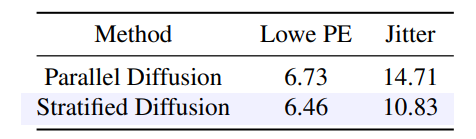
3.3. Diffusion de mouvement stratifiée
3.4. Détails d'implémentation
-
Expériences et métriques d'évaluation
4.1. Ensemble de données et métriques d'évaluation
4.2. Résultats quantitatifs et qualitatifs
4.3. Étude d'ablation
-
Conclusion et références
\ Matériel supplémentaire
A. Études d'ablation supplémentaires
B. Détails d'implémentation
4.3. Étude d'ablation
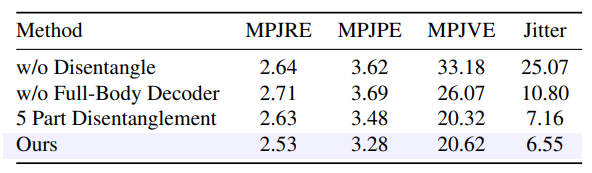
Nous effectuons une étude d'ablation sous S1 pour justifier le choix de conception de chaque composant dans notre SAGE Net.
\ 
\ 
\ 
\ Codebook désenchevêtré : Nous établissons une référence en utilisant une représentation de mouvement unifiée pour évaluer la stratégie de désenchevêtrement. Plus précisément, nous avons développé un modèle VQ-VAE pour le corps entier qui encode le mouvement du corps entier dans un seul codebook discret unifié. Les autres composants sont identiques au modèle original. Les résultats présentés dans la première et la dernière ligne du Tableau 5 démontrent que notre approche utilisant des latents désenchevêtrés surpasse significativement la référence sur toutes les métriques d'évaluation. Cela démontre que le désenchevêtrement peut simplifier le processus d'apprentissage en permettant au modèle de se concentrer sur un ensemble plus limité de mouvements et d'interactions. De plus, la Fig. 5 montre la comparaison visuelle entre notre modèle et le modèle de référence, vérifiant que le désenchevêtrement peut améliorer significativement les résultats de reconstruction pour les mouvements inférieurs les plus difficiles.
\ 
\ Stratégie de désenchevêtrement : Pour étudier la stratégie de désenchevêtrement optimale, nous explorons une configuration de désenchevêtrement extrême en suivant le chemin depuis la racine
\ 
\ (Pelvis) vers chaque nœud feuille le long de l'arbre cinématique. Plus précisément, nous décomposons le corps en cinq segments : les chemins de la racine vers la main gauche (a), la main droite (b), la tête (c), le pied gauche (d) et le pied droit (e). Comme rapporté dans les deux dernières lignes du Tab. 5, les interconnexions articulaires naturelles au sein du corps supérieur (ou inférieur) ont été perturbées lors d'un désenchevêtrement plus poussé du corps humain, entraînant des baisses de performance et compliquant la conception du modèle.
\ 
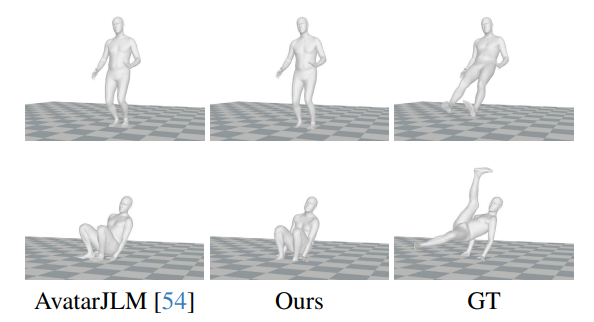
\ Limitation : Dans la Fig. 6, tant la méthode précédente de l'état de l'art que notre modèle rencontrent des difficultés dans deux situations principales : (1) Mouvements induits par des forces externes (rangée supérieure). (2) Poses non conventionnelles (rangée inférieure). L'ajout d'échantillons plus variés à l'ensemble de données d'entraînement peut potentiellement améliorer les performances du modèle dans ces domaines.
\
:::info Auteurs :
(1) Han Feng, contributions égales, classés par ordre alphabétique de l'Université de Wuhan ;
(2) Wenchao Ma, contributions égales, classés par ordre alphabétique de l'Université d'État de Pennsylvanie ;
(3) Quankai Gao, Université de Californie du Sud ;
(4) Xianwei Zheng, Université de Wuhan ;
(5) Nan Xue, Groupe Ant (xuenan@ieee.org) ;
(6) Huijuan Xu, Université d'État de Pennsylvanie.
:::
:::info Cet article est disponible sur arxiv sous licence CC BY 4.0 DEED.
:::
\


Vous aimerez peut-être aussi

United Health Products obtient l'approbation de la FDA pour un nouveau plan d'étude clinique afin de répondre à la lettre d'avertissement

Analyste : La liquidité quasi nulle du XRP sur Binance pourrait déclencher un mouvement brusque




