

ओपन-सेट सिमेंटिक एक्सट्रैक्शन: ग्राउंडेड-SAM, CLIP, और DINOv2 पाइपलाइन
लिंक्स की तालिका
सार और 1 परिचय
-
संबंधित कार्य
2.1. विज़न-एंड-लैंग्वेज नेविगेशन
2.2. सिमेंटिक सीन अंडरस्टैंडिंग और इंस्टेंस सेगमेंटेशन
2.3. 3D सीन रिकंस्ट्रक्शन
-
कार्यप्रणाली
3.1. डेटा संग्रह
3.2. छवियों से ओपन-सेट सिमेंटिक जानकारी
3.3. ओपन-सेट 3D प्रतिनिधित्व बनाना
3.4. भाषा-निर्देशित नेविगेशन
-
प्रयोग
4.1. मात्रात्मक मूल्यांकन
4.2. गुणात्मक परिणाम
-
निष्कर्ष और भविष्य का कार्य, प्रकटीकरण विवरण, और संदर्भ
3.2. छवियों से ओपन-सेट सिमेंटिक जानकारी
\ 3.2.1. ओपन-सेट सिमेंटिक और इंस्टेंस मास्क डिटेक्शन
\ हाल ही में जारी किया गया सेगमेंट एनीथिंग मॉडल (SAM) [21] अपनी अत्याधुनिक सेगमेंटेशन क्षमताओं के कारण शोधकर्ताओं और औद्योगिक प्रैक्टिशनर्स के बीच महत्वपूर्ण लोकप्रियता प्राप्त कर रहा है। हालांकि, SAM एक ही वस्तु के लिए अत्यधिक संख्या में सेगमेंटेशन मास्क उत्पन्न करता है। इस समस्या का समाधान करने के लिए हम अपनी कार्यप्रणाली में ग्राउंडेड-SAM [32] मॉडल को अपनाते हैं। यह प्रक्रिया तीन चरणों में मास्क का एक सेट उत्पन्न करने में शामिल है, जैसा कि चित्र 2 में दर्शाया गया है। प्रारंभ में, रिकग्नाइजिंग एनीथिंग मॉडल (RAM) [33] का उपयोग करके टेक्स्ट लेबल का एक सेट बनाया जाता है। इसके बाद, ग्राउंडिंग DINO मॉडल [25] का उपयोग करके इन लेबल के अनुरूप बाउंडिंग बॉक्स बनाए जाते हैं। छवि और बाउंडिंग बॉक्स को फिर SAM में इनपुट किया जाता है ताकि छवि में दिखाई देने वाली वस्तुओं के लिए क्लास-अज्ञेय सेगमेंटेशन मास्क उत्पन्न किए जा सकें। हम नीचे इस दृष्टिकोण का विस्तृत स्पष्टीकरण प्रदान करते हैं, जो RAM और ग्राउंडिंग-DINO से सिमेंटिक अंतर्दृष्टि को शामिल करके ओवर-सेगमेंटेशन की समस्या को प्रभावी ढंग से कम करता है।
\ RAM मॉडल [33] इनपुट RGB छवि को प्रोसेस करके छवि में पहचानी गई वस्तु का सिमेंटिक लेबलिंग उत्पन्न करता है। यह छवि टैगिंग के लिए एक मजबूत आधारभूत मॉडल है, जो विभिन्न सामान्य श्रेणियों को सटीक रूप से पहचानने में उल्लेखनीय जीरो-शॉट क्षमता प्रदर्शित करता है। इस मॉडल का आउटपुट प्रत्येक इनपुट छवि को लेबल के एक सेट के साथ जोड़ता है जो छवि में वस्तु श्रेणियों का वर्णन करते हैं। प्रक्रिया इनपुट छवि तक पहुंचने और उसे RGB कलर स्पेस में परिवर्तित करने से शुरू होती है, फिर मॉडल की इनपुट आवश्यकताओं के अनुरूप आकार बदला जाता है, और अंत में इसे एक टेंसर में परिवर्तित किया जाता है, जिससे यह मॉडल द्वारा विश्लेषण के लिए संगत हो जाता है। इसके बाद, RAM मॉडल लेबल या टैग उत्पन्न करता है, जो छवि के भीतर मौजूद विभिन्न वस्तुओं या विशेषताओं का वर्णन करते हैं। उत्पन्न लेबल को परिष्कृत करने के लिए एक फिल्ट्रेशन प्रक्रिया का उपयोग किया जाता है, जिसमें इन लेबल से अवांछित वर्गों को हटाना शामिल है। विशेष रूप से, "दीवार", "फर्श", "छत", और "कार्यालय" जैसे अप्रासंगिक टैग को त्याग दिया जाता है, साथ ही अध्ययन के संदर्भ के लिए अनावश्यक माने जाने वाले अन्य पूर्वनिर्धारित वर्गों को भी। इसके अतिरिक्त, यह चरण लेबल सेट को किसी भी आवश्यक वर्ग के साथ बढ़ाने की अनुमति देता है जो शुरू में RAM मॉडल द्वारा पता नहीं लगाया गया था। अंत में, सभी प्रासंगिक जानकारी को एक संरचित प्रारूप में एकत्रित किया जाता है। विशेष रूप से, प्रत्येक छवि को img_dict डिक्शनरी के भीतर सूचीबद्ध किया जाता है, जो छवि के पथ के साथ-साथ उत्पन्न लेबल के सेट को रिकॉर्ड करता है, इस प्रकार बाद के विश्लेषण के लिए डेटा का एक सुलभ भंडार सुनिश्चित करता है।
\ उत्पन्न लेबल के साथ इनपुट छवि के टैगिंग के बाद, वर्कफ़्लो ग्राउंडिंग DINO मॉडल [25] को आमंत्रित करके आगे बढ़ता है। यह मॉडल टेक्स्टुअल वाक्यांशों को छवि के भीतर विशिष्ट क्षेत्रों से जोड़ने में विशेषज्ञता रखता है, प्रभावी ढंग से बाउंडिंग बॉक्स के साथ लक्षित वस्तुओं को चिह्नित करता है। यह प्रक्रिया छवि के भीतर वस्तुओं की पहचान और स्थानिक रूप से स्थानीयकरण करती है, जिससे अधिक विस्तृत विश्लेषण के लिए आधार तैयार होता है। बाउंडिंग बॉक्स के माध्यम से वस्तुओं की पहचान और स्थानीयकरण के बाद, सेगमेंट एनीथिंग मॉडल (SAM) [21] का उपयोग किया जाता है। SAM मॉडल का प्राथमिक कार्य इन बाउंडिंग बॉक्स के भीतर वस्तुओं के लिए सेगमेंटेशन मास्क उत्पन्न करना है। ऐसा करके, SAM व्यक्तिगत वस्तुओं को अलग करता है, जिससे छवि के भीतर वस्तुओं को उनकी पृष्ठभूमि और एक-दूसरे से प्रभावी ढंग से अलग करके अधिक विस्तृत और वस्तु-विशिष्ट विश्लेषण संभव होता है।
\ इस बिंदु पर, वस्तुओं के उदाहरणों की पहचान, स्थानीयकरण और अलगाव किया गया है। प्रत्येक वस्तु को विभिन्न विवरणों के साथ पहचाना जाता है, जिसमें बाउंडिंग बॉक्स निर्देशांक, वस्तु के लिए एक वर्णनात्मक शब्द, लॉजिट्स में व्यक्त वस्तु के अस्तित्व का संभावना या विश्वास स्कोर, और सेगमेंटेशन मास्क शामिल हैं। इसके अलावा, प्रत्येक वस्तु CLIP और DINOv2 एम्बेडिंग फीचर्स से जुड़ी होती है, जिसका विवरण निम्नलिखित उपखंड में विस्तार से दिया गया है।
\ 3.2.2. सिमेंटिक एम्बेडिंग एक्सट्रैक्शन
\ हमारी छवियों के भीतर सेगमेंट और मास्क किए गए वस्तु उदाहरणों के सिमेंटिक पहलुओं की हमारी समझ को बेहतर बनाने के लिए, हम दो मॉडल, CLIP [9] और DINOv2 [10] का उपयोग करते हैं, ताकि प्रत्येक वस्तु की क्रॉप्ड छवियों से फीचर प्रतिनिधित्व प्राप्त किया जा सके। विशेष रूप से CLIP के साथ प्रशिक्षित एक मॉडल छवियों की एक मजबूत सिमेंटिक समझ प्राप्त करता है लेकिन उन छवियों के भीतर गहराई और जटिल विवरणों को नहीं समझ सकता। दूसरी ओर, DINOv2 गहराई धारणा में बेहतर प्रदर्शन दिखाता है और छवियों में सूक्ष्म पिक्सेल-स्तरीय संबंधों की पहचान में उत्कृष्ट है। एक स्व-पर्यवेक्षित विज़न ट्रांसफॉर्मर के रूप में, DINOv2 एनोटेटेड डेटा पर निर्भर किए बिना सूक्ष्म फीचर विवरण निकाल सकता है, जिससे यह विशेष रूप से छवियों के भीतर स्थानिक संबंधों और पदानुक्रमों की पहचान करने में प्रभावी होता है। उदाहरण के लिए, जबकि CLIP मॉडल दो अलग-अलग रंगों की कुर्सियों, जैसे लाल और हरे, के बीच अंतर करने में संघर्ष कर सकता है, DINOv2 की क्षमताएं ऐसे अंतरों को स्पष्ट रूप से करने की अनुमति देती हैं। निष्कर्ष के रूप में, ये मॉडल वस्तुओं के सिमेंटिक और दृश्य विशेषताओं दोनों को कैप्चर करते हैं, जिनका उपयोग बाद में 3D स्पेस में समानता तुलना के लिए किया जाता है।
\ 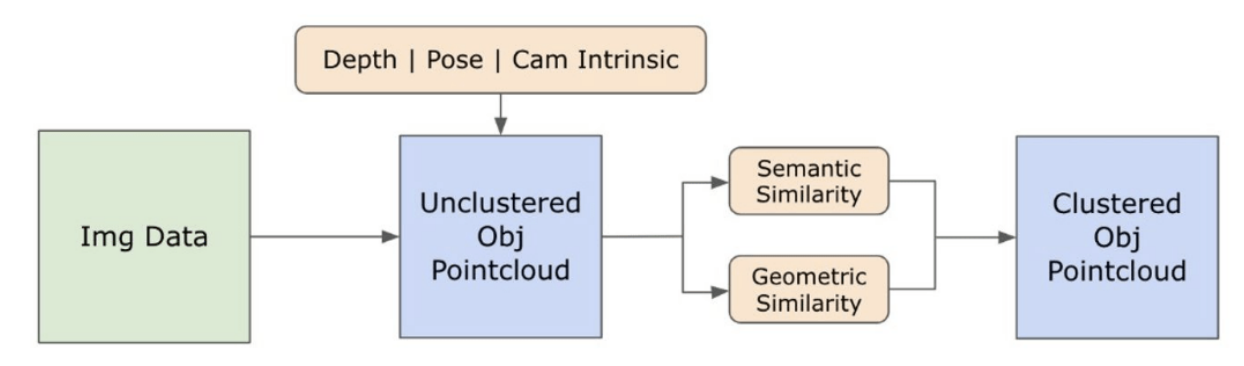
\ DINOv2 मॉडल के साथ छवियों को प्रोसेस करने के लिए पूर्व-प्रसंस्करण चरणों का एक सेट लागू किया जाता है। इनमें आकार बदलना, केंद्र क्रॉपिंग, छवि को एक टेंसर में परिवर्तित करना, और बाउंडिंग बॉक्स द्वारा चिह्नित क्रॉप्ड छवियों को सामान्यीकृत करना शामिल है। प्रसंस्करित छवि को फिर DINOv2 एम्बेडिंग फीचर्स उत्पन्न करने के लिए RAM मॉडल द्वारा पहचाने गए लेबल के साथ DINOv2 मॉडल में फीड किया जाता है। दूसरी ओर, CLIP मॉडल के साथ काम करते समय, पूर्व-प्रसंस्करण चरण में क्रॉप्ड छवि को CLIP के साथ संगत टेंसर प्रारूप में परिवर्तित करना शामिल है, उसके बाद एम्बेडिंग फीचर्स की गणना की जाती है। ये एम्बेडिंग महत्वपूर्ण हैं क्योंकि वे वस्तुओं के दृश्य और सिमेंटिक गुणों को कैप्चर करते हैं, जो दृश्य में वस्तुओं की व्यापक समझ के लिए महत्वपूर्ण हैं। ये एम्बेडिंग अपने L2 नॉर्म के आधार पर सामान्यीकरण से गुजरते हैं, जो फीचर वेक्टर को एक मानकीकृत इकाई लंबाई में समायोजित करता है। यह सामान्यीकरण चरण विभिन्न छवियों में सुसंगत और निष्पक्ष तुलना को सक्षम बनाता है।
\ इस चरण के कार्यान्वयन चरण में, हम अपने डेटा के भीतर प्रत्येक छवि पर पुनरावृत्ति करते हैं और निम्नलिखित प्रक्रियाओं को निष्पादित करते हैं:
\ (1) ग्राउंडिंग DINO मॉडल द्वारा प्रदान किए गए बाउंडिंग बॉक्स निर्देशांकों का उपयोग करके छवि को रुचि के क्षेत्र तक क्रॉप किया जाता है, जिससे विस्तृत विश्लेषण के लिए वस्तु को अलग किया जाता है।
\ (2) क्रॉप्ड छवि के लिए DINOv2 और CLIP एम्बेडिंग उत्पन्न करें।
\ (3) अंत में, एम्बेडिंग को पिछले अनुभाग से मास्क के साथ वापस स्टोर किया जाता है।
\ इन चरणों को पूरा करने के साथ, अब हमारे पास प्रत्येक वस्तु के लिए विस्तृत फीचर प्रतिनिधित्व है, जो आगे के विश्लेषण और अनुप्रयोग के लिए हमारे डेटासेट को समृद्ध बनाता है।
\
:::info लेखक:
(1) लक्ष नानवानी, इंटरनेशनल इंस्टीट्यूट ऑफ इनफॉर्मेशन टेक्नोलॉजी, हैदराबाद, भारत; इस लेखक ने इस कार्य में समान योगदान दिया;
(2) कुमारादित्य गुप्ता, इंटरनेशनल इंस्टीट्यूट ऑफ इनफॉर्मेशन टेक्नोलॉजी, हैदराबाद, भारत;
(3) आदित्य माथुर, इंटरनेशनल इंस्टीट्यूट ऑफ इनफॉर्मेशन टेक्नोलॉजी, हैदराबाद, भारत; इस लेखक ने इस कार्य में समान योगदान दिया;
(4) स्वयं अग्रवाल, इंटरनेशनल इंस्टीट्यूट ऑफ इनफॉर्मेशन टेक्नोलॉजी, हैदराबाद, भारत;
(5) ए.एच. अब्दुल हाफेज, हसन कल्योनकु यूनिवर्सिटी, साहिनबे, गज़ियांतेप, तुर्की;
(6) के. माधव कृष्णा, इंटरनेशनल इंस्टीट्यूट ऑफ इनफॉर्मेशन टेक्नोलॉजी, हैदराबाद, भारत।
:::
:::info यह पेपर CC by-SA 4.0 डीड (एट्रिब्यूशन-शेयरअलाइक 4.0 इंटरनेशनल) लाइसेंस के तहत arxiv पर उपलब्ध है।
:::
\


आपको यह भी पसंद आ सकता है

DeFi | लिक्विड रीस्टेकिंग प्रोटोकॉल, Kelp DAO, से समझौता होकर ~$300 मिलियन का नुकसान

TRON DAO क्रॉस-चेन निष्पादन के लिए deBridge को एकीकृत करता है




