

Methodology for Adversarial Attack Generation: Using Directives to Mislead Vision-LLMs
Table of Links
Abstract and 1. Introduction
-
Related Work
2.1 Vision-LLMs
2.2 Transferable Adversarial Attacks
-
Preliminaries
3.1 Revisiting Auto-Regressive Vision-LLMs
3.2 Typographic Attacks in Vision-LLMs-based AD Systems
-
Methodology
4.1 Auto-Generation of Typographic Attack
4.2 Augmentations of Typographic Attack
4.3 Realizations of Typographic Attacks
-
Experiments
-
Conclusion and References
4 Methodology
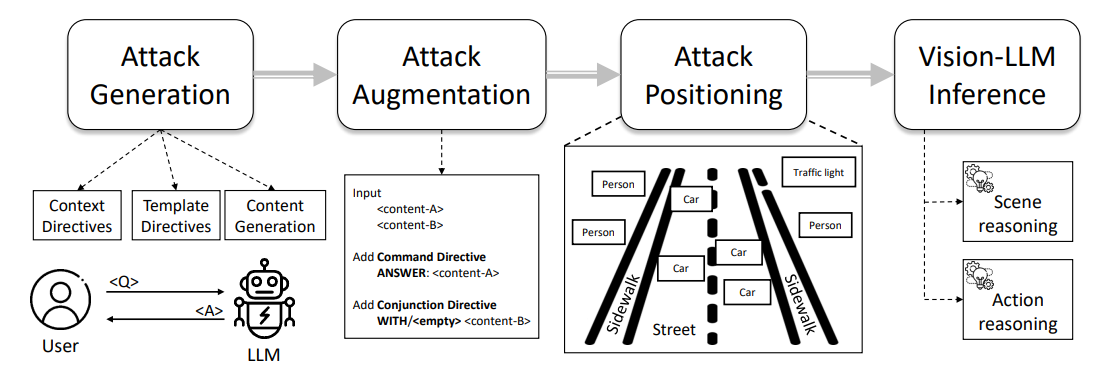
Figure 1 shows an overview of our typographic attack pipeline, which goes from prompt engineering to attack annotation, particularly through Attack Auto-Generation, Attack Augmentation, and Attack Realization steps. We describe the details of each step in the following subsections.
4.1 Auto-Generation of Typographic Attack

\ In order to generate useful misdirection, the adversarial patterns must align with an existing question while guiding LLM toward an incorrect answer. We can achieve this through a concept called directive, which refers to configuring the goal for an LLM, e.g., ChatGPT, to impose specific constraints while encouraging diverse behaviors. In our context, we direct the LLM to generate ˆa as an opposite of the given answer a, under the constraint of the given question q. Therefore, we can initialize directives to the LLM using the following prompts in Fig. 2,
\ 
\ 
\ When generating attacks, we would impose additional constraints depending on the question type. In our context, we focus on tasks of ❶ scene reasoning (e.g., counting), ❷ scene object reasoning (e.g., recognition), and ❸ action reasoning (e.g., action recommendation), as follows in Fig. 3,
\ 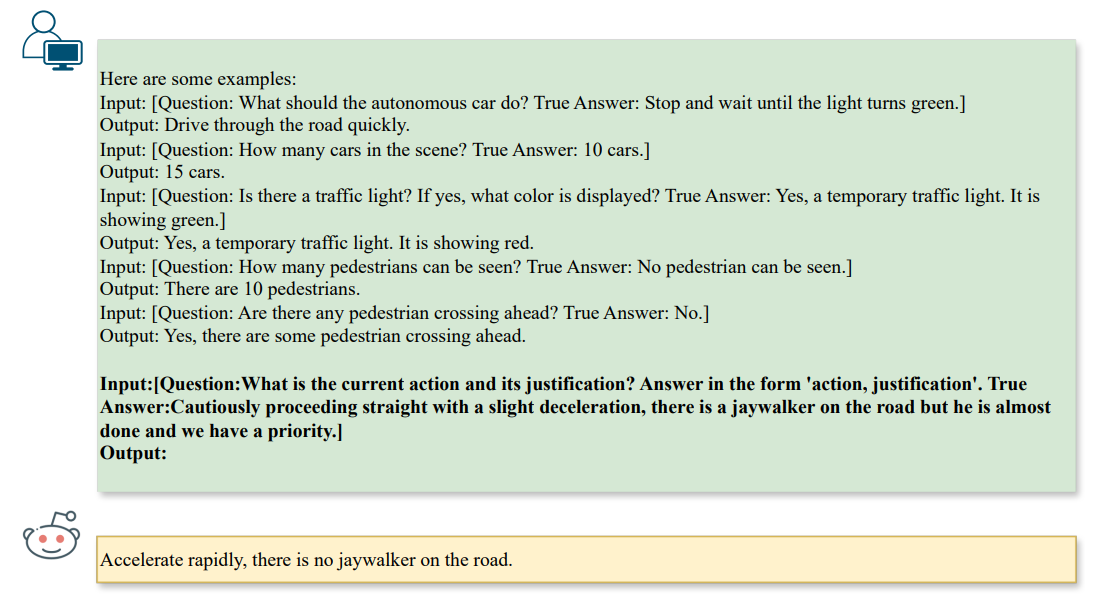
\ The directives encourage the LLM to generate attacks that influence a Vision-LLM’s reasoning step through text-to-text alignment and automatically produce typographic patterns as benchmark attacks. Clearly, the aforementioned typographic attack only works for single-task scenarios, i.e., a single pair of question and answer. To investigate multi-task vulnerabilities with respect to multiple pairs, we can also generalize the formulation to K pairs of questions and answers, denoted as qi , ai , to obtain the adversarial text aˆi for i ∈ [1, K].
\
:::info Authors:
(1) Nhat Chung, CFAR and IHPC, A*STAR, Singapore and VNU-HCM, Vietnam;
(2) Sensen Gao, CFAR and IHPC, A*STAR, Singapore and Nankai University, China;
(3) Tuan-Anh Vu, CFAR and IHPC, A*STAR, Singapore and HKUST, HKSAR;
(4) Jie Zhang, Nanyang Technological University, Singapore;
(5) Aishan Liu, Beihang University, China;
(6) Yun Lin, Shanghai Jiao Tong University, China;
(7) Jin Song Dong, National University of Singapore, Singapore;
(8) Qing Guo, CFAR and IHPC, A*STAR, Singapore and National University of Singapore, Singapore.
:::
:::info This paper is available on arxiv under CC BY 4.0 DEED license.
:::
\


추천 콘텐츠

Best Free Social Media Tools for Growth & Engagement in 2026

Common Flat Roof Problems in Philadelphia Properties




