

Accurate Forest Mapping Using TreeLearn and Lidar-Based Point Clouds
Table of Links
Abstract and 1 Introduction
- Materials and Methods
- Results and Discussion
- Conclusion and References
2 MATERIALS AND METHODS
2.1 LABELED FOREST DATA
The TreeLearn method can be trained on complete labeled forest point clouds that have a sufficiently high scanning resolution for all parts of a tree. The existing literature was searched for data that fulfils this criterion. First, there is the recently published FOR-instance dataset (Puliti et al., 2023b) in which tree labels and fine-grained semantic labels were manually added to point clouds from existing works. These point clouds have been captured via UAV-laser scanning and consist of diverse forest plots located in Norway (NIBIO), Czech Republic (CULS), Austria (TU WIEN), New Zealand (SCION) and Australia (RMIT). In another recent work, tree labels for a forest plot located in Germany (L1W) were obtained using the Lidar360 software (GreenValley International, 2022) and then manually corrected. A summary of the characteristics of each dataset can be found in Table 1. More precise information can be found in the respective publications.
\ Apart from these point clouds, two published datasets were identified that consist of high-quality segmented trees obtained by an automatic segmentation algorithm that were either manually checked (WYTHAM, Calders et al., 2022) or corrected (LAUTx, Tockner et al., 2022) for quality assurance. The respective authors were contacted to obtain the complete unlabeled point clouds. These point clouds additionally contain non-tree points, i.e. belonging to the understory or ground, and non-annotated points, i.e. points that belong to trees but have not been annotated in the published datasets. For example, some parts of the tree crown that are hard to clearly assign to a specific tree might not have been annotated.
\ To obtain labels for the complete point clouds, the tree labels from the published datasets have to be propagated and the remaining points must be assigned to the classes “non-tree” or “non-annotated”. This was done as follows:
\
-
For each point in the unlabeled forest point cloud, the most common tree label within a 0.1 m radius was assigned.
\
-
Among the remaining unlabeled points, non-tree points were identified using proximity-based clustering: All points that were within a 0.3 m distance to each other were linked and the largest connected component was labeled as non-tree points. The large grouping radius together with the high resolution of the point clouds ensured that all understory and ground points were added to the non-tree class.
\
-
The points that were still unlabeled at this stage represent tree points that have not been annotated and were assigned to the non-annotated class. This information can be used to disregard these points during training.
\
-
Finally, we visually inspected the point clouds to ensure that they were adequately divided into trees, non-tree points and non-annotated points. Remaining errors were manually corrected within a feasible scope. Specifically, one large tree was not segmented in the original labeled data of Calders et al. (2022) which was added, and the tree bases of Tockner et al. (2022) were corrected since they were only roughly segmented in the original labeled data.
\ For the given datasets, high-quality segmentation labels are only ensured when considering trees larger than 10 m, while assigning the rest as non-trees. In WYTHAM, smaller trees are inconsistently labeled, i.e. sometimes as a tree and sometimes as non-tree. In LAUTX, smaller trees have severe quality limitations. A correction of these mistakes was beyond the scope of this work. Therefore, only trees larger than 10 m were considered here.
2.2 SEGMENTATION METHOD
The model framework used in this study is TreeLearn (Henrich et al., 2023). It employs the widelyused grouping-based paradigm (Qi et al., 2019) for instance segmentation: The point cloud is processed using a 3D-UNet followed by pointwise semantic and offset prediction. The semantic prediction is used to classify points as tree or non-tree. The offset prediction aims to shift each point towards the respective tree base a point belongs to. After applying the predicted offset to each point, tree instances can be identified using density-based clustering. To account for memory limitations, the authors proposed a sliding window approach with subsequent merging of the results.
2.3 EXPERIMENTS
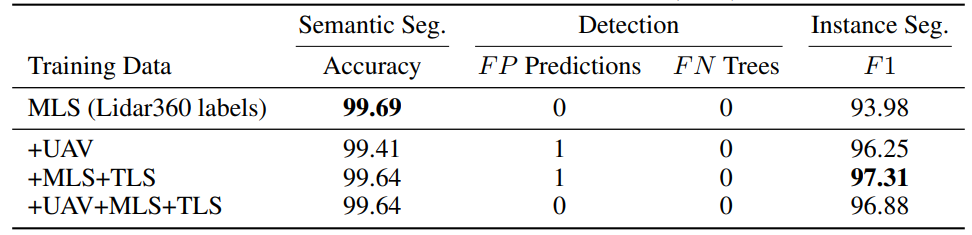
Using the labeled data presented in Section 2.1, TreeLearn was trained in three conditions: (i) In the first condition, only UAV-data was used (NIBIO, CULS, TU WIEN, SCION). Most of these point clouds come from coniferous dominated forests. (ii) In the second condition, only TLS and MLS data (LAUTX, WYTHAM) were used, which come from mixed or deciduous forests. (iii) Lastly, all data was used for model training. In all three conditions, an area covering roughly 400 trees from WYTHAM was employed as the validation set. The number of trees in the training data in condition (i) and (ii) is roughly equal (765 vs. 762). Test performance was evaluated using L1W, a beech-dominated deciduous forest. Condition (i) assesses the effect of using out-of-domain data during training since the laser scanning characteristics and tree composition are substantially different from L1W. Condition (ii) represents in-domain data. In addition to quantitative test results on L1W, qualitative test results on a low-resolution UAV point cloud (RMIT) are presented.
\ 
\ 
\ The performance on the L1W-dataset is evaluated based on the evaluation protocol detailed in Henrich et al. (2023). First, the tree detection performance is measured by the number of false positive and false negative predictions. To assess the semantic segmentation into tree and non-tree points, the accuracy is calculated. Instance segmentation performance is evaluated using the F1-score. It is calculated for each tree separately based on the number of true positive, false positive and false negative points and then averaged across all trees.
\
:::info Authors:
(1) Jonathan Henrich, Chairs of Statistics and Econometrics, Faculty of Economics, University of Gottingen, Germany (jonathan.henrich@uni-goettingen.de)
(2) Jan van Delden, Institute of Computer Science, University of Gottingen Germany (jan.vandelden@uni-goettingen.de).
:::
:::info This paper is available on arxiv under CC by-SA 4.0 Deed (Attribution-Sharealike 4.0 International) license.
:::
\


추천 콘텐츠

Pakistan mediates US-Iran ceasefire talks as deadline looms April 22, 2026

Trump's frantic late-night rant claims victory while Iran war falls apart




