

SAGE: Stratified Avatar Generation for Full-Body 3D Reconstruction from Sparse HMD Data
Table of Links
Abstract and 1. Introduction
-
Related Work
2.1. Motion Reconstruction from Sparse Input
2.2. Human Motion Generation
-
SAGE: Stratified Avatar Generation and 3.1. Problem Statement and Notation
3.2. Disentangled Motion Representation
3.3. Stratified Motion Diffusion
3.4. Implementation Details
-
Experiments and Evaluation Metrics
4.1. Dataset and Evaluation Metrics
4.2. Quantitative and Qualitative Results
4.3. Ablation Study
-
Conclusion and References
\ Supplementary Material
A. Extra Ablation Studies
B. Implementation Details
\ 
Abstract
Estimating 3D full-body avatars from AR/VR devices is essential for creating immersive experiences in AR/VR applications. This task is challenging due to the limited input from Head Mounted Devices, which capture only sparse observations from the head and hands. Predicting the full-body avatars, particularly the lower body, from these sparse observations presents significant difficulties. In this paper, we are inspired by the inherent property of the kinematic tree defined in the Skinned Multi-Person Linear (SMPL) model, where the upper body and lower body share only one common ancestor node, bringing the potential of decoupled reconstruction. We propose a stratified approach to decouple the conventional full-body avatar reconstruction pipeline into two stages, with the reconstruction of the upper body first and a subsequent reconstruction of the lower body conditioned on the previous stage. To implement this straightforward idea, we leverage the latent diffusion model as a powerful probabilistic generator, and train it to follow the latent distribution of decoupled motions explored by a VQ-VAE encoder-decoder model. Extensive experiments on AMASS mocap dataset demonstrate our state-of-the-art performance in the reconstruction of full-body motions.
1. Introduction
Generating 3D full-body avatars from observations of Head Mounted Devices (HMDs) is crucial for enhancing immersive AR/VR experiences. HMDs primarily track the head and hands, while leaving the rest of the body unmonitored. This limited motion tracking poses a challenging scenario for accurately reconstructing full-body 3D avatars, particularly in representing the lower body. The high degree of freedom in body movements compounds this difficulty, making the task of reasoning human motion from such sparse observations significantly complex.
\ Tremendous efforts have been made to obtain more tracking signals by adding sensors at Pelvis [5, 10, 34] or both Pelvis and Legs [16, 19, 46, 50, 51]. While these approaches provide more data points for avatar construction, they can diminish the user’s experience. Wearing extra devices can be cumbersome, potentially interfering with the user’s comfort and immersion in the virtual environment. This trade-off highlights the need for innovative solutions that can deliver detailed body tracking without compromising the user’s comfort and immersion in AR/VR settings. Accordingly, we are interested in the problem of generating 3D full-body avatars from sparse observations of HMDs that track the motion of the head and two hands, by developing a neural solution that learns the distribution of full-body poses given the sparse observations as the input condition.
\ Recent studies have attempted to address the challenge of sparse observations in HMD-based full-body avatar generation by employing regression-based techniques, as seen in [18, 54], or by adopting generation-based approaches like [7, 11]. These methods typically use deep neural networks to predict human motion within a single, expansive motion space. However, due to the limited data provided by sparse observations, these networks often struggle to fully capture the complexities of human kinematics across such a broad and unified motion space. This limitation frequently results in reconstructions that are unrealistic and lack physical plausibility.
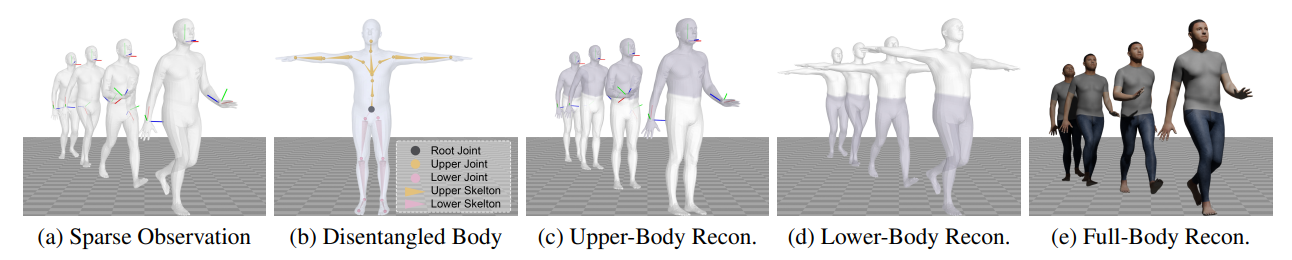
\ We introduce a new method for reconstructing full-body human motions from sparse observations, called Stratified Avatar Generation (SAGE). Instead of the upper-body motion prediction that has tracking signals of certain upper joints from sparse observations, predicting lower-body motion is not straightforward as no direct tracking signals about any lower-body joint is given. It is noteworthy that SMPL model [22] connects the upper and lower half-body by a single root joint, as shown in Fig. 1 (b), which motivates us to split the full-body motions into upper and lower half-body parts. The benefits are two-fold: 1) the smaller search space achieved by disentanglement facilitates learning and prediction; 2) our stratified design makes the modeling and inferring for lower-body motions more accurate and visually appealing by explicitly modeling the correlation and constraint between two half-body motions. To this end, we use VQ-VAE [44] to encode and reconstruct upper and lower body motions separately.
\ With the disentangled latent representation of the upper and lower body motions, we aim to recover the accurate full-body motions from sparse observations with a body-customized latent diffusion model (LDM) [36] in a stratified manner. Specifically, as shown in Fig. 1 (c), Fig. 1(d), and Fig. 1(e), we first find the latent of upper-body motion condition on the sparse observations (i.e., tracking signals of the head and hands in Fig. 1(a)). Then, the latent of lower-body motion is inferred condition on both the predicted upper-body latent and sparse observations. Finally, a full-body decoder takes the two half-body latents as input and outputs the full-body motion.
\ In the experiments, we comprehensively justified our intuitive design of disentangling the upper and lower body motion in a stratified manner. On the large-scale motion capture benchmark AMASS [25], our proposed SAGE is exhibiting superior performance in different evaluation settings and particularly performs well in terms of the evaluation metrics for lower-body motion estimation compared to previous state-of-the-art methods.
\
:::info This paper is available on arxiv under CC BY 4.0 DEED license.
:::
:::info Authors:
(1) Han Feng, equal contributions, ordered by alphabet from Wuhan University;
(2) Wenchao Ma, equal contributions, ordered by alphabet from Pennsylvania State University;
(3) Quankai Gao, University of Southern California;
(4) Xianwei Zheng, Wuhan University;
(5) Nan Xue, Ant Group (xuenan@ieee.org);
(6) Huijuan Xu, Pennsylvania State University.
:::
\


추천 콘텐츠
![[OPINION] US Pax Silica initiative: Good or bad?](https://www.rappler.com/tachyon/2024/10/tech-stocks-october-31-2024.jpg?resize=75%2C75&crop=408px%2C0px%2C1080px%2C1080px)
[OPINION] US Pax Silica initiative: Good or bad?

The real story behind Operation Epic Failure




