

Gensyn testnet is online. How to make AI training more efficient and decentralized?
Author: Zen, PANews
AI is the most popular segment in the crypto industry today. Gensyn, a distributed AI computing network led by a16z with a total financing scale of US$50 million, is undoubtedly a competitive project. Recently, Gensyn officially launched its test network. Although it is more than a year later than originally planned, it has finally entered a new stage with the launch of the test network.
As a customized Ethereum Rollup built specifically for machine learning, the Gensyn testnet integrates off-chain execution, verification, and communication frameworks, aiming to provide decentralized AI systems with key functions such as persistent identity, participation tracking, attribution maintenance, payment, remote execution coordination, trustless verification, training process recording, and crowdfunding for large-scale training tasks.
The first phase of the testnet focuses on tracking participation within RL Swarm, an application for collaborative reinforcement learning post-training where nodes can be bound to on-chain identities, ensuring that the contribution of each participating node is accurately recorded.
RL Swarm: Core Functionality and Collaborative Training
In the Gensyn testnet, RL Swarm, as a core application, is a model collaborative training system built on a decentralized network. Unlike traditional single model independent training, RL Swarm allows multiple models to communicate, criticize and improve each other in the network, thereby jointly improving overall performance. Its core concept lies in "group wisdom", that is, through collaboration and feedback between node models, more efficient training results can be achieved.
It can be simply understood that when models such as DeepSeek-R1 are performing inference training, they can iteratively improve their inference performance through self-criticism, while RL Swarm extends this mechanism to groups of multiple models, achieving the effect of "many hands make light work".
Based on the RL Swarm system, the model not only relies on its own feedback, but also identifies its own shortcomings and optimizes them by observing and evaluating the performance of other models. Each model node that joins Swarm is participating in a three-stage process: first, it independently completes the problem and outputs ideas and answers, then checks the answers of other nodes and provides feedback, and finally the model votes for the best solution and corrects its output accordingly. This collaborative mechanism not only improves the performance of each model, but also promotes the evolution of the entire group model. Models that join Swarm can still retain the improved local weights after leaving and obtain actual benefits.
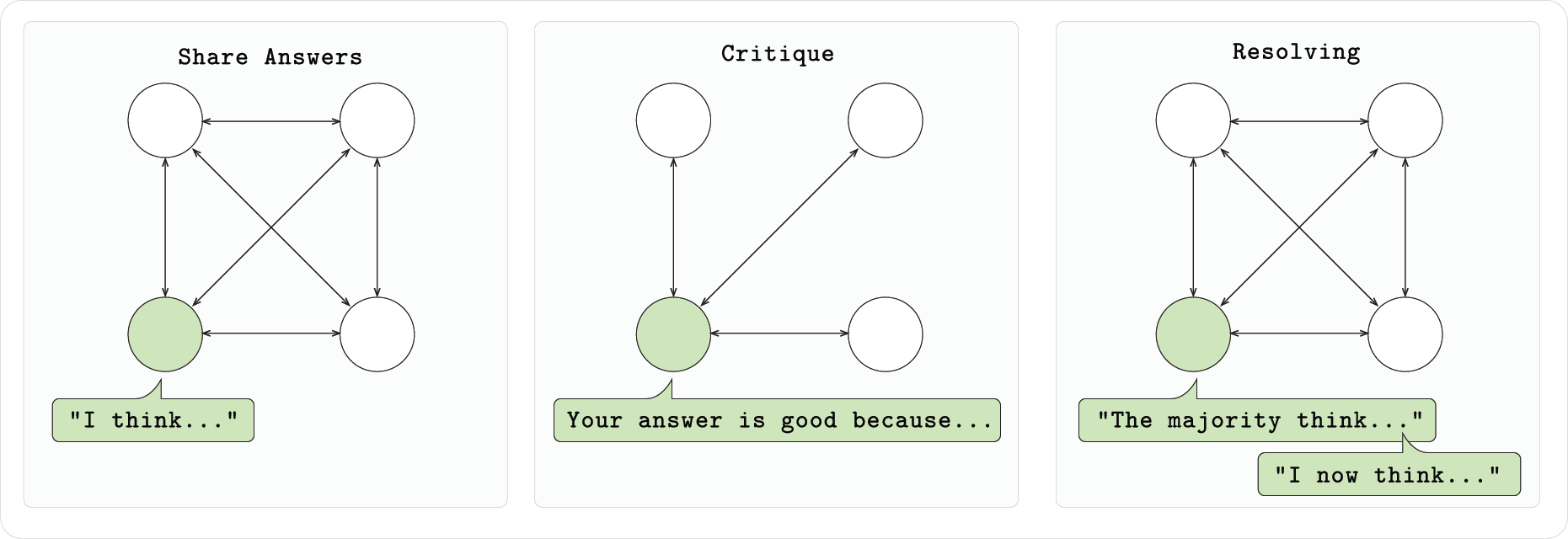
In addition, Gensyn has open-sourced the code for RL Swarm, so anyone can run a node, start or join an existing Swarm without permission. Swarm's underlying communication uses the gossip protocol provided by Hivemind, which supports decentralized messaging and learning signal sharing between models. Whether it's a home laptop or a cloud GPU, you can participate in collaborative training by joining an RL Swarm node.
The three pillars of infrastructure : execution, communication, and verification
Currently, RL Swarm is still just an experimental demonstration, which shows a large-scale, scalable machine learning method, rather than the final product form. In the past four years, the core work of Gensyn has actually been to build the underlying infrastructure. After the release of the test network, it entered the v0.1 stage and can be actually run. According to the official introduction, the overall architecture of Gensyn is divided into three parts: execution, communication, and verification.
Execution: Consistency and Distributed Computing
Gensyn believes that future machine learning is no longer limited to traditional single models, but consists of fragmented parameters distributed across devices around the world. To achieve this goal, the Gensyn team has developed an underlying execution architecture that ensures consistency across devices. The key technologies include:
- Distributed parameter storage and training: By splitting large-scale models into multiple parameter blocks and distributing them on different devices, Gensyn achieves fragmented deployment of models and reduces the memory requirements of a single node.
- RL Post-Training: Research shows that when models are trained collaboratively in groups, communicate with each other, and critique each other’s answers, overall learning efficiency is significantly improved. Gensyn demonstrated this concept using RL Swarm, allowing models to quickly improve in group discussions, further validating the effectiveness of distributed execution.
- Reproducible Operators (RepOps): To ensure that different hardware (such as Nvidia A100 and H100) can produce exactly the same calculation results, Gensyn developed the RepOps library, which achieves cross-platform bit-by-bit reproduction by fixing the execution order of floating-point operations.
Communication: Efficient information exchange
In large-scale distributed training scenarios, efficient communication between nodes is crucial. Although traditional data parallel methods can reduce communication overhead to a certain extent, their scalability is limited by memory because each node is required to store the complete model. To this end, Gensyn proposed a new solution:
- SkipPipe – Dynamically skip pipeline parallelism: SkipPipe technology skips some stages in the traditional pipeline by dynamically selecting the computing layer that microbatches pass through, thereby reducing unnecessary waiting time. Its innovative scheduling algorithm can evaluate the availability of each path in real time, which not only reduces node idle time, but also significantly shortens the overall training time. According to test data, in a decentralized environment, SkipPipe can reduce training time by about 55%, and in the case of partial node failure, the model performance is only reduced by about 7%.
- Communication standards and cross-node collaboration Gensyn has built a set of communication protocols similar to TCP/IP, which enables participants around the world to efficiently and seamlessly transmit data and exchange information regardless of the device they use. This open standard provides a solid network foundation for distributed collaborative training.
Verification: Ensuring Trust and Security
In a trustless distributed network, how to confirm that the calculation results submitted by each participant are authentic and valid is a major challenge. Gensyn has introduced a special verification protocol to ensure that all computing power providers provide correct work results through a low-cost and efficient mechanism:
- Verde Verification Protocol: Verde is the first verification system designed specifically for modern machine learning. At its core, it uses a lightweight dispute resolution mechanism to quickly locate the step in the training process where the model and the verifier disagree. Unlike traditional verification methods that require rerunning the entire task, Verde only needs to recalculate the disputed operation, greatly reducing verification overhead.
- Refereed delegation: With this method, if there is a problem with a supplier’s output, the validator can convince the neutral arbitrator through an efficient dispute resolution game to ensure that the correctness of the entire calculation result is guaranteed when there is at least one honest node.
- Storing and hashing intermediate states: To support the above verification process, participants only need to store and hash some intermediate training checkpoints instead of the full data, which not only reduces resource usage but also improves the scalability and real-time performance of the system.


추천 콘텐츠

Ethereum Price Today: ETH At $2,138

$4 Trillion Tokenized Assets by 2028 Could Ignite DeFi Boom, Standard Chartered Says




