

Data Diversity Matters More Than Data Quantity in AI
Table of Links
Abstract and 1 Introduction
-
Related Work
-
Our Proposed DiverGen
3.1. Analysis of Data Distribution
3.2. Generative Data Diversity Enhancement
3.3. Generative Pipeline
-
Experiments
4.1. Settings
4.2. Main Results
4.3. Ablation Studies
-
Conclusions, Acknowledgments, and References
\ Appendix
A. Implementation Details
B. Visualization
4.1. Settings
Datasets. We choose LVIS [8] for our experiments. LVIS is a large-scale instance segmentation dataset, containing 164k images with approximately two million high-quality annotations of instance segmentation and object detection. LVIS dataset uses images from COCO 2017 [15] dataset, but redefines the train/val/test splits, with around 100k images in the training set and around 20k images in the validation set. The annotations in LVIS cover 1,203 categories, with a typical long-tailed distribution of categories, so LVIS further divides the categories into frequent, common, and rare based on the frequency of each category in the dataset. We use the official LVIS training split and the validation split.
\ 
\
4.2. Main Results
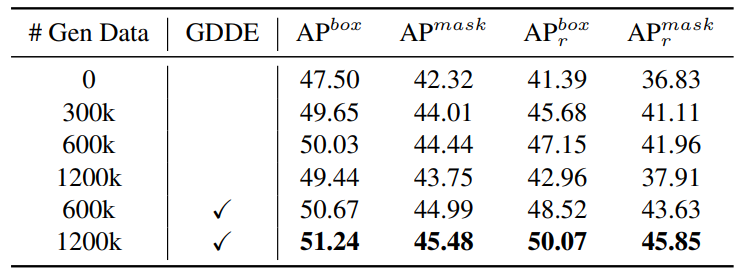
Data diversity is more important than quantity. To investigate the impact of different scales of generative data, we use generative data of varying scales as paste data sources. We construct three datasets using only DeepFloyd-IF [24] with manually designed prompts, all containing original LVIS 1,203 categories, but with per-category quantities of 0.25k, 0.5k, and 1k, resulting in total dataset scales of 300k, 600k, and 1,200k. As shown in Table 3, we find that using generative data improves model performance compared to the baseline. However, as the dataset scale increases, the model performance initially improves but then declines. The model performance using 1,200k data is lower than that using 600k data. Due to the limited number of manually designed prompts, the generative model produces similar data, as shown in Figure 4a. Consequently, the model can not gain benefits from more data. However, when using our proposed Generative Data Diversity Enhancement (GDDE), due to the increased data diversity, the model trained with 1,200k images achieves better results than using 600k images, with an improvement of 1.21 box AP and 1.04 mask AP. Moreover, when using the same data scale of 600k, the mask AP increased by 0.64 AP and the box AP increased by 0.55 AP when using GDDE compared to not using it. The results demonstrate that data diversity is more important than quantity. When the scale of data is small, increasing the quantity of data can improve model performance, which we consider is an indirect way of increasing data diversity. However, this simplistic approach of solely increasing quantity to increase diversity has an upper limit. When it reaches this limit, explicit data diversity enhancement strategies become necessary to maintain the trend of model performance improvement.
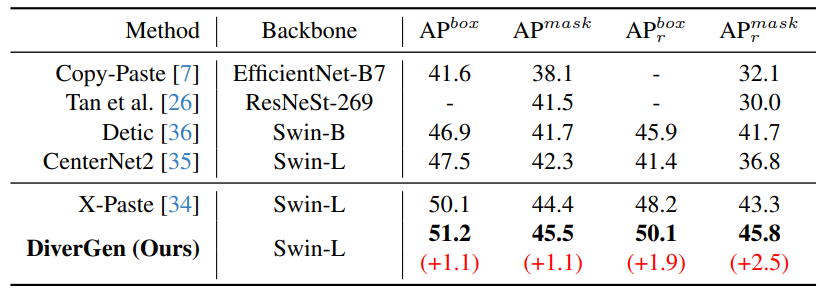
\ Comparison with previous methods. We compare DiverGen with previous data-augmentation related methods in Table 4. Compared to the baseline CenterNet2 [35], our method significantly improves, increasing box AP by +3.7 and mask AP by +3.2. Regarding rare categories, our method surpasses the baseline with +8.7 in box AP and +9.0 in mask AP. Compared to the previous strong model X-Paste [34], we outperform it with +1.1 in box AP and +1.1 in mask AP of all categories, and +1.9 in box AP and +2.5 in mask AP of rare categories. It is worth mentioning that, X-Paste utilizes both generative data and web-retrieved data as paste data sources during training, while our method exclusively uses generative data as the paste data source. We achieve this by designing diversity enhancement strategies, further unlocking the potential of generative models.
\ 
\ 
\ 
\
:::info Authors:
(1) Chengxiang Fan, with equal contribution from Zhejiang University, China;
(2) Muzhi Zhu, with equal contribution from Zhejiang University, China;
(3) Hao Chen, Zhejiang University, China (haochen.cad@zju.edu.cn);
(4) Yang Liu, Zhejiang University, China;
(5) Weijia Wu, Zhejiang University, China;
(6) Huaqi Zhang, vivo Mobile Communication Co..
(7) Chunhua Shen, Zhejiang University, China (chunhuashen@zju.edu.cn).
:::
:::info This paper is available on arxiv under CC BY-NC-ND 4.0 Deed (Attribution-Noncommercial-Noderivs 4.0 International) license.
:::
\


추천 콘텐츠
Floki Price Prediction: Pepeto Binance Listing is Days Away After CoinMarketCap Confirmation

Bitcoin Price Prediction Turns Bullish as Strategy Adds 22,048 BTC and Pepeto Nears Listing




