

MaGGIe Architecture Deep Dive: Mask Guidance and Sparse Refinement
Table of Links
Abstract and 1. Introduction
-
Related Works
-
MaGGIe
3.1. Efficient Masked Guided Instance Matting
3.2. Feature-Matte Temporal Consistency
-
Instance Matting Datasets
4.1. Image Instance Matting and 4.2. Video Instance Matting
-
Experiments
5.1. Pre-training on image data
5.2. Training on video data
-
Discussion and References
\ Supplementary Material
-
Architecture details
-
Image matting
8.1. Dataset generation and preparation
8.2. Training details
8.3. Quantitative details
8.4. More qualitative results on natural images
-
Video matting
9.1. Dataset generation
9.2. Training details
9.3. Quantitative details
9.4. More qualitative results
7. Architecture details
This section delves into the architectural nuances of our framework, providing a more detailed exposition of components briefly mentioned in the main paper. These insights are crucial for a comprehensive understanding of the underlying mechanisms of our approach.
7.1. Mask guidance identity embedding
7.2. Feature extractor
\ 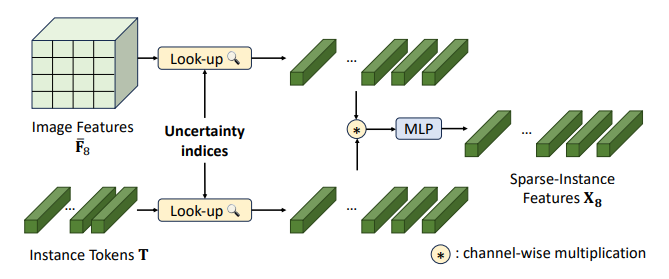
7.3. Dense-image to sparse-instance features
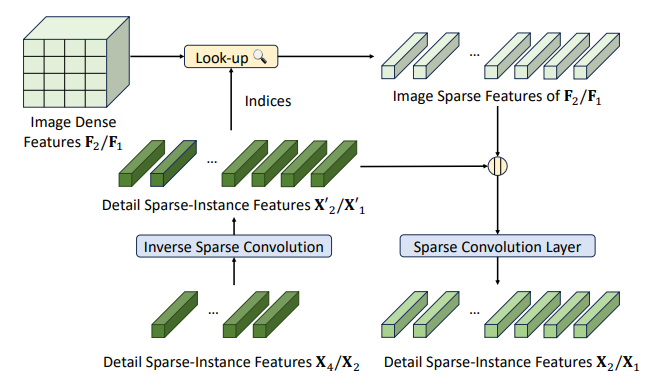
7.4. Detail aggregation
This process, akin to a U-net decoder, aggregates features from different scales, as detailed in Fig. 8. It involves upscaling sparse features and merging them with corresponding higher-scale features. However, this requires precomputed downscale indices from dummy sparse convolutions on the full input image.
7.5. Sparse matte head
Our matte head design, inspired by MGM [56], comprises two sparse convolutions with intermediate normalization and activation (Leaky ReLU) layers. The final output undergoes sigmoid activation for the final prediction. Non-refined locations in the dense prediction are assigned a value of zero.
7.6. Sparse progressive refinement
The PRM module progressively refines A8 → A4 → A1 to have A. We assume that all predictions are rescaled to the largest size and perform refinement between intermediate predictions and uncertainty indices U:
\ 
7.7. Attention loss and loss weight
\ 
\ 
7.8. Temporal sparsity prediction
A key aspect of our approach is the prediction of temporal sparsity to maintain consistency between frames. This module contrasts the feature maps of consecutive frames to predict their absolute differences. Comprising three convolution layers with batch normalization and ReLU activation, this module processes the concatenated feature maps from two adjacent frames and predicts the binary differences between them.
\ Unlike SparseMat [50], which relies on manual threshold selection for frame differences, our method offers a more robust and domain-independent approach to determining frame sparsity. This is particularly effective in handling variations in movement, resolution, and domain between frames, as demonstrated in Fig. 9
7.9. Forward and backward matte fusion
\ This fusion enhances temporal consistency and minimizes error propagation.
\
:::info Authors:
(1) Chuong Huynh, University of Maryland, College Park (chuonghm@cs.umd.edu);
(2) Seoung Wug Oh, Adobe Research (seoh,jolee@adobe.com);
(3) Abhinav Shrivastava, University of Maryland, College Park (abhinav@cs.umd.edu);
(4) Joon-Young Lee, Adobe Research (jolee@adobe.com).
:::
:::info This paper is available on arxiv under CC by 4.0 Deed (Attribution 4.0 International) license.
:::
\


추천 콘텐츠

Bitcoin Price Is Only Halfway To The Bottom And Will Crash Below $40,000, Here’s Why

Space and Time Targets Institutional Lending With the Launch of Virtual Vaults




