

Reducing TPC-H Workload Runtime by 40% with IA2 Deep Reinforcement Learning
Table of Links
Abstract and 1. Introduction
-
Related Works
2.1 Traditional Index Selection Approaches
2.2 RL-based Index Selection Approaches
-
Index Selection Problem
-
Methodology
4.1 Formulation of the DRL Problem
4.2 Instance-Aware Deep Reinforcement Learning for Efficient Index Selection
-
System Framework of IA2
5.1 Preprocessing Phase
5.2 RL Training and Application Phase
-
Experiments
6.1 Experimental Setting
6.2 Experimental Results
6.3 End-to-End Performance Comparison
6.4 Key Insights
-
Conclusion and Future Work, and References
Abstract
This study introduces the Instance-Aware Index Advisor (IA2), a novel deep reinforcement learning (DRL)-based approach for optimizing index selection in databases facing large action spaces of potential candidates. IA2 introduces the Twin Delayed Deep Deterministic Policy Gradient - Temporal Difference State-Wise Action Refinery (TD3-TD-SWAR) model, enabling efficient index selection by understanding workload-index dependencies and employing adaptive action masking. This method includes a comprehensive workload model, enhancing its ability to adapt to unseen workloads and ensuring robust performance across diverse database environments. Evaluation on benchmarks such as TPCH reveals IA2’s suggested indexes’ performance in enhancing runtime, securing a 40% reduction in runtime for complex TPC-H workloads compared to scenarios without indexes, and delivering a 20% improvement over existing state-of-theart DRL-based index advisors.
1 Introduction
For more than five decades, the pursuit of optimal index selection has been a key focus in database research, leading to significant advancements in index selection methodologies [8]. However, despite these developments, current strategies frequently struggle to provide both high-quality solutions and efficient selection processes [5].
\ The Index Selection Problem (ISP), detailed in Section 3, involves choosing the best subset of index candidates, considering multi-attribute indexes, from a specific workload, dataset, and under given constraints, such as storage capacity or a maximum number of indexes. This task, aimed at enhancing workload performance, is recognized as NP-hard, highlighting the complexities, especially when dealing with multi-attribute indexes, in achieving optimal index configurations [7].
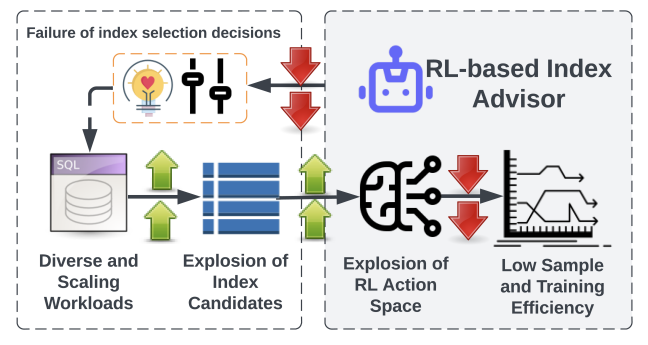
\ Reinforcement Learning (RL) offers a promising solution for navigating the complex decision spaces involved in index selection [6, 7, 10]. Yet, the broad spectrum of index options and the complexity of workload structures complicate the process, leading to prolonged training periods and challenges in achieving optimal configurations. This situation highlights the critical need for advanced solutions adept at efficiently managing the complexities of multi-attribute index selection [6]. Figure 1 illustrates the difficulties encountered with RL in index selection, stemming from the combinatorial complexity and vast action spaces. Our approach improves DRL agent efficiency via adaptive action selection, significantly refining the learning process. This enables rapid identification of advantageous indexes across varied database schemas and workloads, thereby addressing the intricate challenges of database optimization more effectively.
\ Our contributions are threefold: (i) modeling index selection as a reinforcement learning problem, characterized by a thorough system designed to support comprehensive workload representation and implement state-wise action pruning methods, distinguishing our approach from existing literature. (ii) employing TD3-TD-SWAR for efficient training and adaptive action space navigation; (iii) outperforming stateof-the-art methods in selecting optimal index configurations for diverse and even unseen workloads. Evaluated on the TPC-H Benchmark, IA2 demonstrates significant training efficiency, runtime improvements, and adaptability, marking a significant advancement in database optimization for diverse workloads.
\ 
\
:::info This paper is available on arxiv under CC BY-NC-SA 4.0 Deed (Attribution-Noncommercial-Sharelike 4.0 International) license.
:::
\


추천 콘텐츠

Bitcoin 28% Haircut: Moody’s Sets Forced-Selling Trigger

Crypto, tech, and software stocks rose as the S&P 500 and Nasdaq closed at record highs
