

Embedding Similarity Scoring for Smarter Image Retrieval Systems

Table of Links
Abstract and 1. Introduction
-
Materials and Methods
2.1 Vector Database and Indexing
2.2 Feature Extractors
2.3 Dataset and Pre-processing
2.4 Search and Retrieval
2.5 Re-ranking retrieval and evaluation
-
Evaluation and 3.1 Search and Retrieval
3.2 Re-ranking
-
Discussion
4.1 Dataset and 4.2 Re-ranking
4.3 Embeddings
4.4 Volume-based, Region-based and Localized Retrieval and 4.5 Localization-ratio
-
Conclusion, Acknowledgement, and References
2.5 Re-ranking retrieval and evaluation
Re-ranking in information retrieval involves the process of re-ordering the initially retrieved results to better align with the user’s information needs. This can be achieved through different methods such as relevance feedback, learning to rank algorithms, or incorporating contextual information [Ai et al., 2018, Guo et al., 2020, MacAvaney et al., 2019]. Relevance feedback allows users to provide input on the initial results, which is then used to adjust the ranking [Ai et al., 2018]. Learning to rank algorithms utilizes machine learning techniques to re-rank results based on relevant features [Guo et al., 2020]. Additionally, re-ranking methods may also consider contextual information such as user behavior, temporal relevance, or other relevant factors to better reflect the user’s current information needs, ultimately enhancing the overall quality of retrieved results [MacAvaney et al., 2019]. A method based on contextualized information proposed in Khattab and Zaharia [2020] called ColBERT (Contextualized Late Interaction over BERT). ColBERT operates by generating contextualized representations of the query and the documents using BERT [Devlin et al., 2018]. In this method, queries and documents are encoded into more detailed multi-vector representations, and relevance is gauged through comprehensive yet scalable interactions between these sets of vectors. ColBERT creates an embedding
\ 
\ for each token in the query and document, and it measures relevance as the total of maximum similarities between each query vector and all vectors within the document [Santhanam et al., 2021]. This late interaction approach allows for a more refined and contextually aware retrieval process, thereby enhancing the quality of information retrieval.
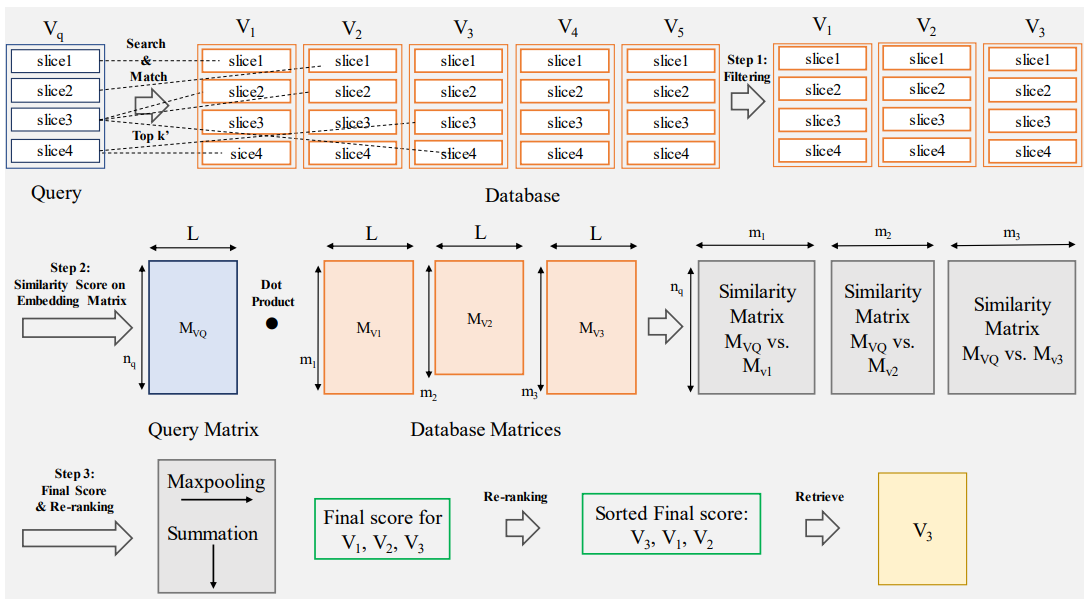
\ Inspired by ColBERT we introduce a two-stage method in which filtering of the search space is performed and the total similarity of the entire target volume is considered to re-rank and score the retrieved volumes. To create an analogy to the ColBERT method each word can be considered as one slice and each passage of the database or each question of the query can be considered as one volume. Instead of the BERT encoder for the image retrieval task, the pre-trained vision models can be used to create the embeddings as discussed in Section 2.2.
\ An overview of the proposed method is shown in Figure 5. The method consists of the following steps:
\ 2.5.1 Step 1: Filtering
\ 
\ 2.5.2 Step 2: Similarity Score on Embedding Matrix
\ 
\ 2.5.3 Step 3: Final Score and Re-ranking
\ 
\ 2.5.4 Localization with Re-ranking
\ In section 2.4.3 we proposed a measure for assessing the capabilities of the search system to localize anatomical regions of interest. This localization measure relied on the hit slices that were finally retrieved by count-based aggregation. As described above, re-ranking may select a volume with a lower total hit count as the final search result based on a more fine-grained similarity measure. We propose to utilize this similarity information to identify slices of maximal similarity with the query data in order to localize the anatomical region of interest.
\ In detail, after having obtained the most relevant search result via re-ranking, we need to identify the most relevant slices that could contain the anatomical region of interest r. To this end, we consider the slices that highly contribute to the final RS score (5). Since the full similarity matrices (4) for all candidates from the first search stage are available, we can utilize these to identify the locations of maximum similarity between the query and candidate slices.
\ 
\
:::info Authors:
(1) Farnaz Khun Jush, Bayer AG, Berlin, Germany (farnaz.khunjush@bayer.com);
(2) Steffen Vogler, Bayer AG, Berlin, Germany (steffen.vogler@bayer.com);
(3) Tuan Truong, Bayer AG, Berlin, Germany (tuan.truong@bayer.com);
(4) Matthias Lenga, Bayer AG, Berlin, Germany (matthias.lenga@bayer.com).
:::
:::info This paper is available on arxiv under CC BY 4.0 DEED license.
:::
\


추천 콘텐츠

Will XRP price fall below $1.30 support

Republican Clay Fuller wins runoff to succeed Marjorie Taylor Greene in Congress




