

Detalhes técnicos: Treino BSGAL, Backbone Swin-L e Estratégia de Limiar Dinâmico
Tabela de Links
Resumo e 1 Introdução
-
Trabalhos relacionados
2.1. Aumento de Dados Generativos
2.2. Aprendizagem Ativa e Análise de Dados
-
Preliminar
-
Nosso método
4.1. Estimativa de Contribuição no Cenário Ideal
4.2. Aprendizagem Ativa Generativa em Streaming em Lotes
-
Experiências e 5.1. Configuração Offline
5.2. Configuração Online
-
Conclusão, Impacto Mais Amplo e Referências
\
A. Detalhes de Implementação
B. Mais ablações
C. Discussão
D. Visualização
A. Detalhes de Implementação
A.1. Conjunto de Dados
Escolhemos LVIS (Gupta et al., 2019) como o conjunto de dados para as nossas experiências. LVIS é um conjunto de dados de segmentação de instâncias em grande escala, compreendendo aproximadamente 160.000 imagens com mais de 2 milhões de anotações de segmentação de instâncias de alta qualidade em 1203 categorias do mundo real. O conjunto de dados é ainda dividido em três categorias: rara, comum e frequente, com base na sua ocorrência nas imagens. Instâncias marcadas como 'raras' aparecem em 1-10 imagens, instâncias 'comuns' aparecem em 11-100 imagens, enquanto instâncias 'frequentes' aparecem em mais de 100 imagens. O conjunto de dados geral exibe uma distribuição de cauda longa, assemelhando-se de perto à distribuição de dados no mundo real, e é amplamente aplicado em múltiplas configurações, incluindo segmentação few-shot (Liu et al., 2023) e segmentação de mundo aberto (Wang et al., 2022; Zhu et al., 2023). Portanto, acreditamos que selecionar LVIS permite uma melhor reflexão do desempenho do modelo em cenários do mundo real. Usamos as divisões oficiais do conjunto de dados LVIS, com cerca de 100.000 imagens no conjunto de treino e 20.000 imagens no conjunto de validação.
A.2. Geração de Dados
O nosso processo de geração e anotação de dados é consistente com Zhao et al. (2023), e apresentamo-lo brevemente aqui. Primeiro, usamos o StableDiffusion V1.5 (Rombach et al., 2022a) (SD) como modelo generativo. Para as 1203 categorias em LVIS (Gupta et al., 2019), geramos 1000 imagens por categoria, com resolução de imagem de 512 × 512. O modelo de prompt para geração é "a photo of a single {CATEGORY NAME}". Usamos U2Net (Qin et al., 2020), SelfReformer (Yun and Lin, 2022), UFO (Su et al., 2023) e CLIPseg (Luddecke e Ecker, 2022) respetivamente para anotar as imagens generativas brutas, e selecionamos a máscara com a pontuação CLIP mais alta como anotação final. Para garantir a qualidade dos dados, imagens com pontuações CLIP abaixo de 0,21 são filtradas como imagens de baixa qualidade. Durante o treino, também empregamos a estratégia de colagem de instâncias fornecida por Zhao et al. (2023) para aumento de dados. Para cada instância, redimensionamos aleatoriamente para corresponder à distribuição da sua categoria no conjunto de treino. O número máximo de instâncias coladas por imagem é definido como 20.
\ Além disso, para expandir ainda mais a diversidade dos dados gerados e tornar a nossa pesquisa mais universal, também usamos outros modelos generativos, incluindo DeepFloyd-IF (Shonenkov et al., 2023) (IF) e Perfusion (Tewel et al., 2023) (PER), com 500 imagens por categoria por modelo. Para IF, usamos o modelo pré-treinado fornecido pelo autor, e as imagens geradas são a saída do Estágio II, com uma resolução de 256×256. Para PER, o modelo base que usamos é o StableDiffusion V1.5. Para cada categoria, ajustamos o modelo usando as imagens recortadas do conjunto de treino, com 400 etapas de ajuste fino. Usamos o modelo ajustado para gerar imagens.
\ 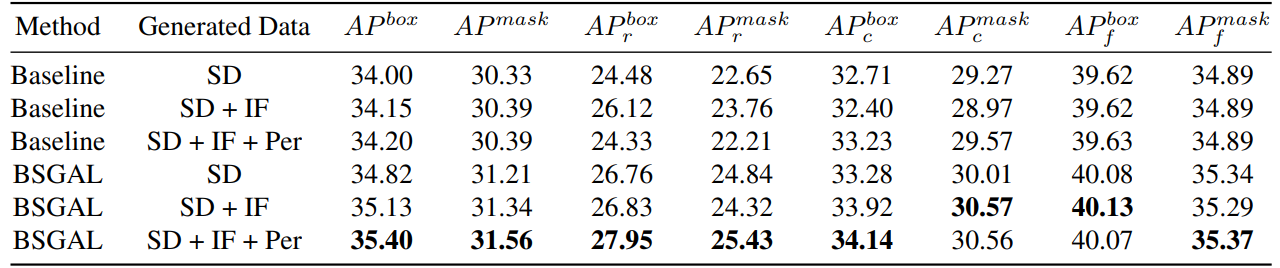
\ Também exploramos o efeito de usar diferentes dados gerados no desempenho do modelo (ver Tabela 7). Podemos ver que, com base no StableDiffusion V1.5 original, usar outros modelos generativos pode trazer alguma melhoria de desempenho, mas essa melhoria não é óbvia. Especificamente, para categorias de frequência específica, descobrimos que IF tem uma melhoria mais significativa para categorias raras, enquanto PER tem uma melhoria mais significativa para categorias comuns. Isso provavelmente ocorre porque os dados IF são mais diversos, enquanto os dados PER são mais consistentes com a distribuição do conjunto de treino. Considerando que o desempenho geral foi melhorado até certo ponto, finalmente adotamos os dados gerados de SD + IF + PER para experiências subsequentes.
A.3. Treino do Modelo
Seguindo Zhao et al. (2023), usamos CenterNet2 (Zhou et al., 2021) como nosso modelo de segmentação, com ResNet-50 (He et al., 2016) ou Swin-L (Liu et al., 2022) como backbone. Para ResNet-50, a iteração máxima de treino é definida como 90.000 e o modelo é inicializado com pesos primeiro pré-treinados no ImageNet-22k e depois ajustados no LVIS (Gupta et al., 2019), como Zhao
\ 
\ et al. (2023) fizeram. E usamos 4 GPUs Nvidia 4090 com um tamanho de lote de 16 durante o treino. Quanto ao Swin-L, a iteração máxima de treino é definida como 180.000 e o modelo é inicializado com pesos pré-treinados no ImageNet-22k, uma vez que as nossas experiências iniciais mostram que esta inicialização pode trazer uma ligeira melhoria em comparação com os pesos treinados com LVIS. E usamos 4 GPUs Nvidia A100 com um tamanho de lote de 16 para treino. Além disso, devido ao grande número de parâmetros do Swin-L, a memória adicional ocupada por salvar o gradiente é grande, por isso na verdade usamos o algoritmo no Algoritmo 2.
\ Os outros parâmetros não especificados também seguem as mesmas configurações que X-Paste (Zhao et al., 2023), como o otimizador AdamW (Loshchilov e Hutter, 2017) com uma taxa de aprendizagem inicial de 1e−4.
A.4. Quantidade de Dados
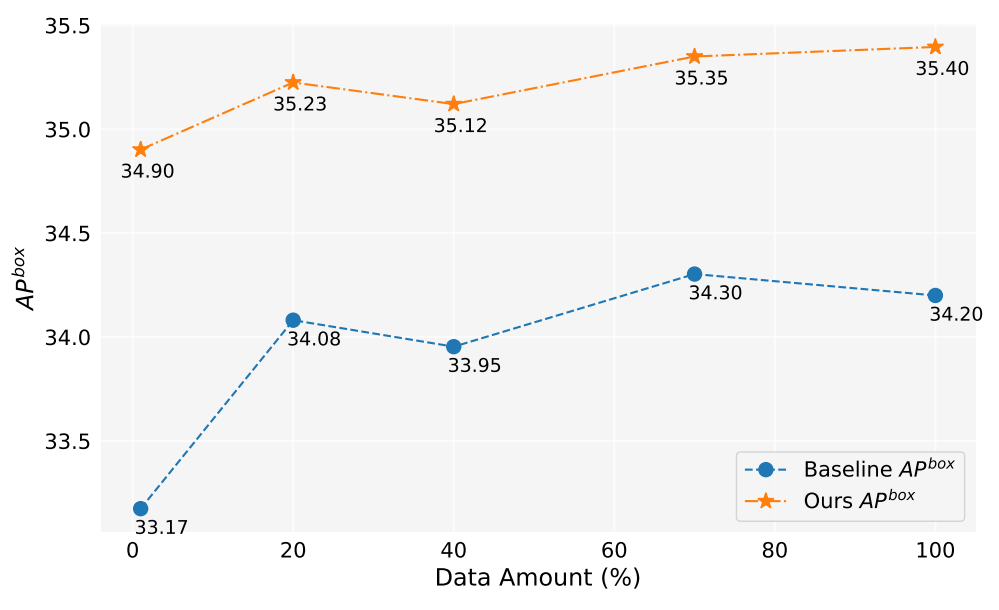
Neste trabalho, geramos mais de 2 milhões de imagens. A Figura 5 mostra os desempenhos do modelo ao usar diferentes quantidades de dados gerados (1%, 10%, 40%, 70%, 100%). No geral, à medida que a quantidade de dados gerados aumenta, o desempenho do modelo também melhora, mas também há alguma flutuação. O nosso método é sempre melhor que a linha de base, o que prova a eficácia e robustez do nosso método.
A.5. Estimativa de Contribuição
\ Assim, essencialmente calculamos a similaridade do cosseno. Em seguida, realizamos uma comparação experimental, como mostrado na Tabela 8,
\ 
\ 
\ podemos ver que se normalizarmos o gradiente, o nosso método terá uma certa melhoria. Além disso, uma vez que precisamos manter dois limiares diferentes, é difícil garantir a consistência da taxa de aceitação. Por isso, adotamos uma estratégia de limiar dinâmico, pré-definimos uma taxa de aceitação, mantemos uma fila para guardar a contribuição da iteração anterior e, em seguida, ajustamos dinamicamente o limiar de acordo com a fila, para que a taxa de aceitação permaneça na taxa de aceitação pré-definida.
A.6. Experiência de Brinquedo
A seguir estão as configurações experimentais específicas implementadas no CIFAR-10: Empregamos um simples ResNet18 como modelo de base e realizamos treino ao longo de 200 épocas, e a precisão após o treino no conjunto de treino original é de 93,02%. A taxa de aprendizagem é definida em 0,1, utilizando o otimizador SGD. Um momentum de 0,9 está em vigor, com um decaimento de peso de 5e-4. Usamos um programador de taxa de aprendizagem de recozimento de cosseno. As imagens ruidosas construídas são representadas na Figura 6. Observa-se um declínio na qualidade da imagem à medida que o nível de ruído aumenta. Notavelmente, quando o nível de ruído atinge 200, as imagens tornam-se significativamente desafiadoras de identificar. Para a Tabela 1, usamos Split1 como R, enquanto G consiste em 'Split2 + Noise40', 'Split3 + Noise100', 'Split4 + Noise200',
A.7. Uma Simplificação Apenas Avançar Uma Vez
\
:::info Autores:
(1) Muzhi Zhu, com contribuição igual da Universidade de Zhejiang, China;
(2) Chengxiang Fan, com contribuição igual da Universidade de Zhejiang, China;
(3) Hao Chen, Universidade de Zhejiang, China (haochen.cad@zju.edu.cn);
(4) Yang Liu, Universidade de Zhejiang, China;
(5) Weian Mao, Universidade de Zhejiang, China e Universidade de Adelaide, Austrália;
(6) Xiaogang Xu, Universidade de Zhejiang, China;
(7) Chunhua Shen, Universidade de Zhejiang, China (chunhuashen@zju.edu.cn).
:::
:::info Este artigo está disponível no arxiv sob a licença CC BY-NC-ND 4.0 Deed (Atribuição-NãoComercial-SemDerivações 4.0 Internacional).
:::
\


Você também pode gostar

Một địa chỉ trên Tron chứa khoảng 131 triệu USDT đã bị đóng băng
Funding Bitcoin xuống đáy 2023, BTC đối mặt thử thách 80.000 USD




