

O Guia do Geek para Experimentação em ML

Tabela de Links
Abstrato e 1. Introdução
1.1 Explicação Post Hoc
1.2 O Problema da Discordância
1.3 Incentivando o Consenso de Explicação
-
Trabalhos Relacionados
-
Pear: Regularizador de Concordância de Explicador Post HOC
-
A Eficácia do Treinamento de Consenso
4.1 Métricas de Concordância
4.2 Melhorando as Métricas de Consenso
[4.3 Consistência a Que Custo?]()
4.4 As Explicações Ainda São Valiosas?
4.5 Consenso e Linearidade
4.6 Dois Termos de Perda
-
Discussão
5.1 Trabalhos Futuros
5.2 Conclusão, Agradecimentos e Referências
Apêndice
A APÊNDICE
A.1 Conjuntos de Dados
Nos nossos experimentos, utilizamos conjuntos de dados tabulares originalmente do OpenML e compilados num conjunto de conjuntos de dados de referência da equipa Inria-Soda no HuggingFace [11]. Fornecemos alguns detalhes sobre cada conjunto de dados:
\ Bank Marketing Este é um conjunto de dados de classificação binária com seis características de entrada e é aproximadamente equilibrado em termos de classe. Treinamos com 7.933 amostras de treino e testamos nas restantes 2.645 amostras.
\ California Housing Este é um conjunto de dados de classificação binária com sete características de entrada e é aproximadamente equilibrado em termos de classe. Treinamos com 15.475 amostras de treino e testamos nas restantes 5.159 amostras.
\ Electricity Este é um conjunto de dados de classificação binária com sete características de entrada e é aproximadamente equilibrado em termos de classe. Treinamos com 28.855 amostras de treino e testamos nas restantes 9.619 amostras.
A.2 Hiperparâmetros
Muitos dos nossos hiperparâmetros são constantes em todas as nossas experiências. Por exemplo, todos os MLPs são treinados com um tamanho de lote de 64 e uma taxa de aprendizagem inicial de 0,0005. Além disso, todos os MLPs que estudamos têm 3 camadas ocultas de 100 neurónios cada. Utilizamos sempre o otimizador AdamW [19]. O número de épocas varia de caso para caso. Para os três conjuntos de dados, treinamos durante 30 épocas quando 𝜆 ∈ {0,0, 0,25} e 50 épocas nos outros casos. Ao treinar modelos lineares, utilizamos 10 épocas e uma taxa de aprendizagem inicial de 0,1.
A.3 Métricas de Discordância
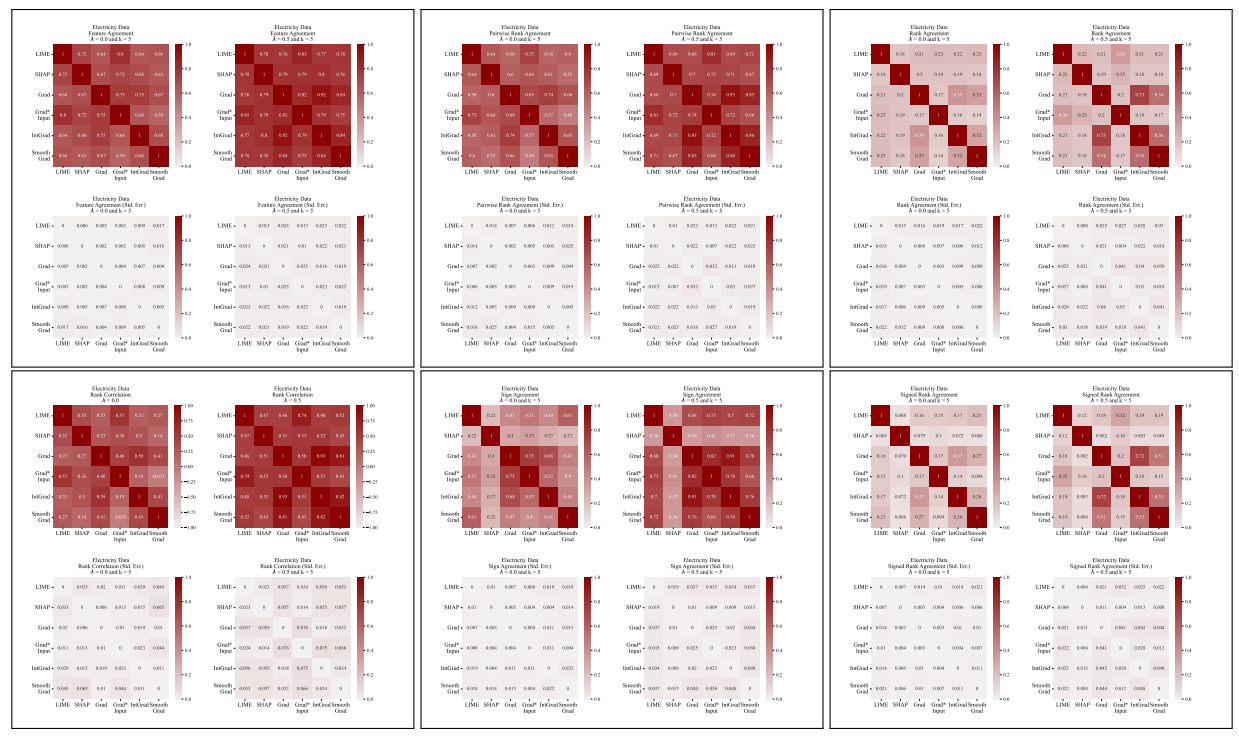
Definimos aqui cada uma das seis métricas de concordância utilizadas no nosso trabalho.
\ As primeiras quatro métricas dependem das características mais importantes top-𝑘 em cada explicação. Seja 𝑡𝑜𝑝_𝑓 𝑒𝑎𝑡𝑢𝑟𝑒𝑠(𝐸, 𝑘) representando as características mais importantes top-𝑘 numa explicação 𝐸, seja 𝑟𝑎𝑛𝑘 (𝐸, 𝑠) a classificação de importância da característica 𝑠 dentro da explicação 𝐸, e seja 𝑠𝑖𝑔𝑛(𝐸, 𝑠) o sinal (positivo, negativo ou zero) da pontuação de importância da característica 𝑠 na explicação 𝐸.
\ 
\ As próximas duas métricas de concordância dependem de todas as características dentro de cada explicação, não apenas do top-𝑘. Seja 𝑅 uma função que calcula a classificação das características dentro de uma explicação por importância.
\ 
\ (Nota: Krishna et al. [15] especificam no seu artigo que 𝐹 deve ser um conjunto de características especificado por um utilizador final, mas nas nossas experiências utilizamos todas as características com esta métrica).
A.4 Resultados da Experiência com Características Inúteis
Quando adicionamos características aleatórias para a experiência na Secção 4.4, duplicamos o número de características. Fazemos isto para verificar se a nossa perda de consenso prejudica a qualidade da explicação, colocando características irrelevantes no top-𝐾 com mais frequência do que modelos treinados naturalmente. Na Tabela 1, relatamos a percentagem de vezes que cada explicador incluiu uma das características aleatórias nas 5 características mais importantes. Observamos que, em geral, não vemos um aumento sistemático dessas percentagens entre 𝜆 = 0,0 (um MLP de referência sem a nossa perda de consenso) e 𝜆 = 0,5 (um MLP treinado com a nossa perda de consenso)
\ 
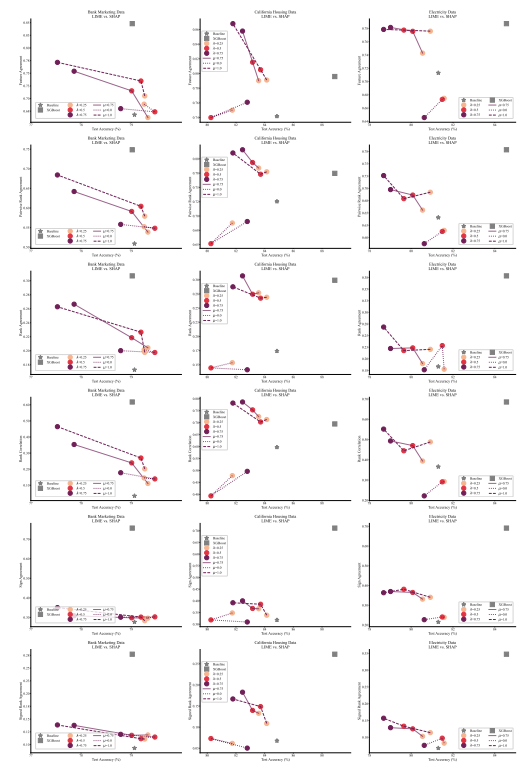
A.5 Mais Matrizes de Discordância
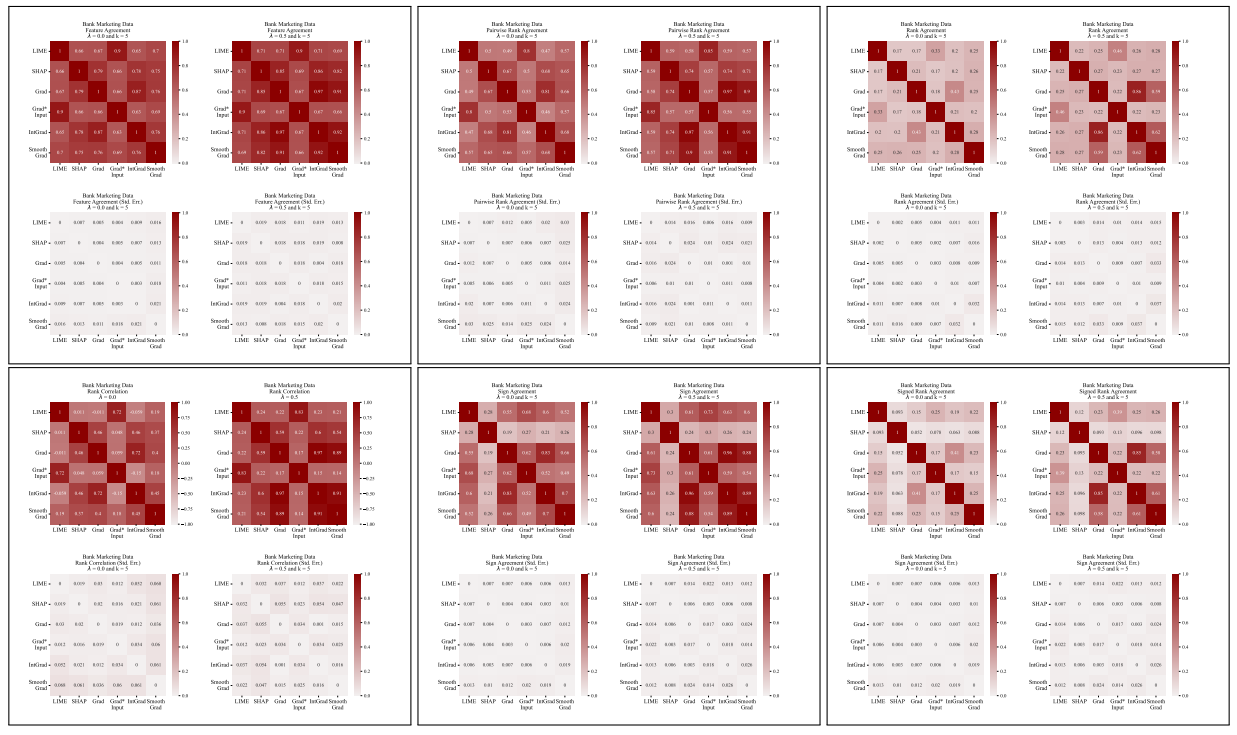
\ 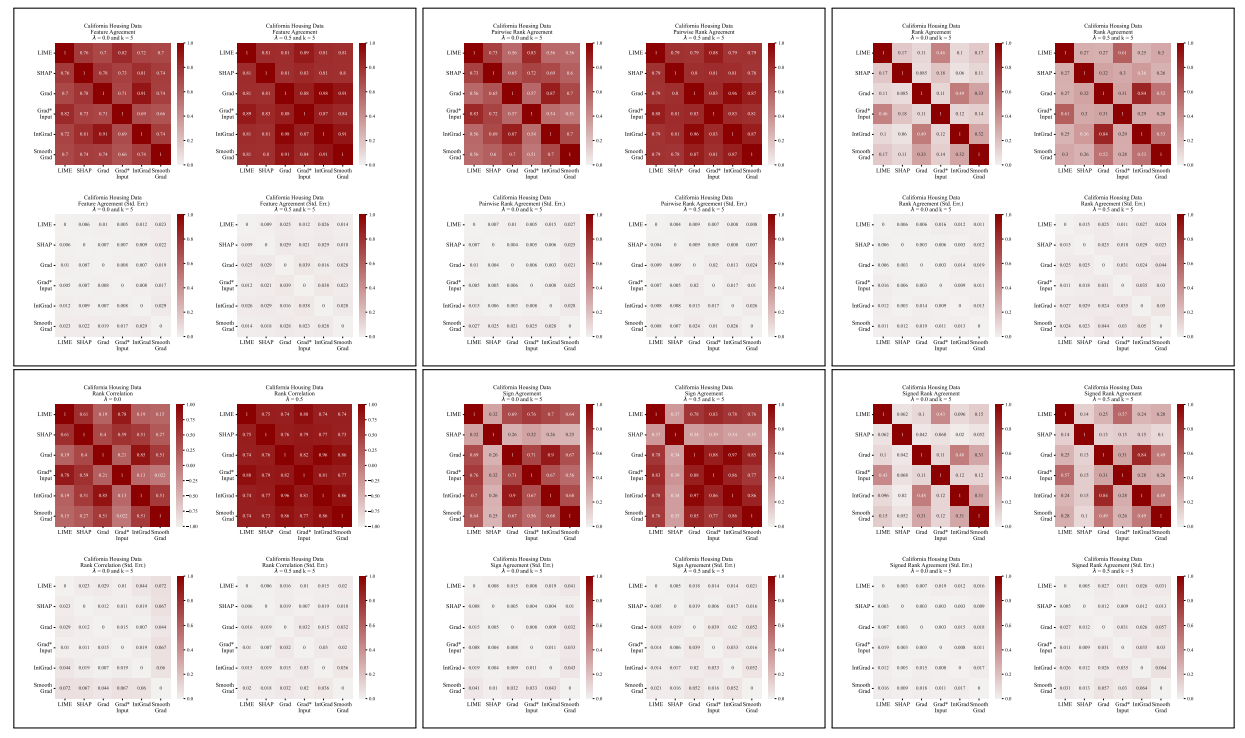
\ 
A.6 Resultados Estendidos
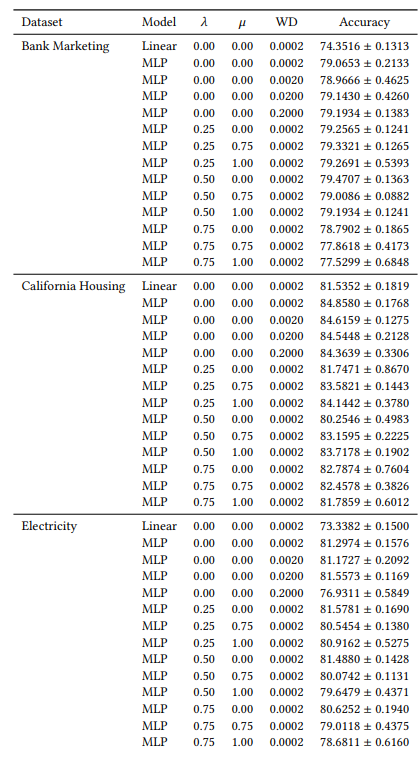
A.7 Gráficos Adicionais
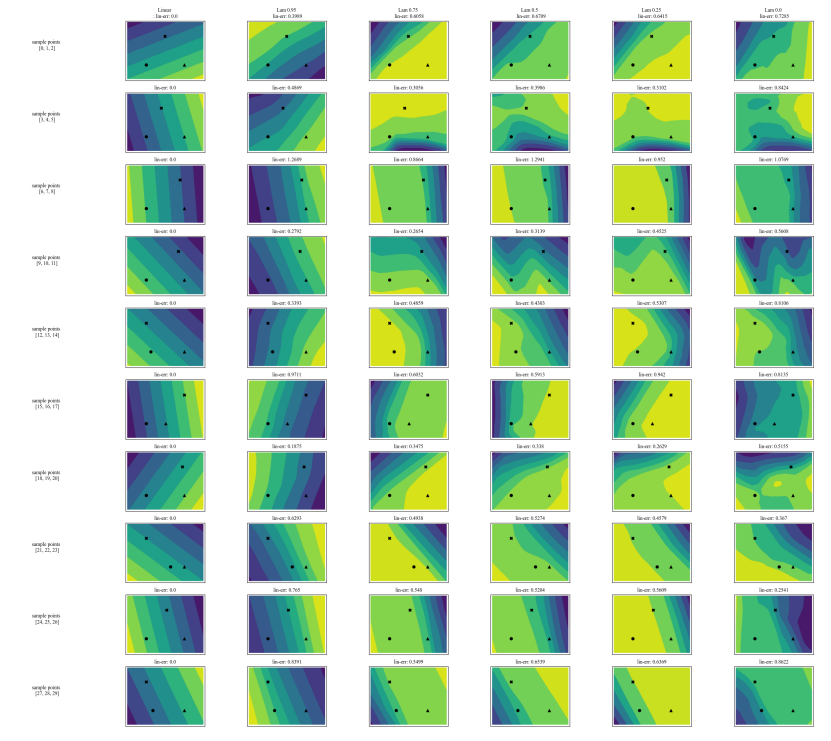
\ 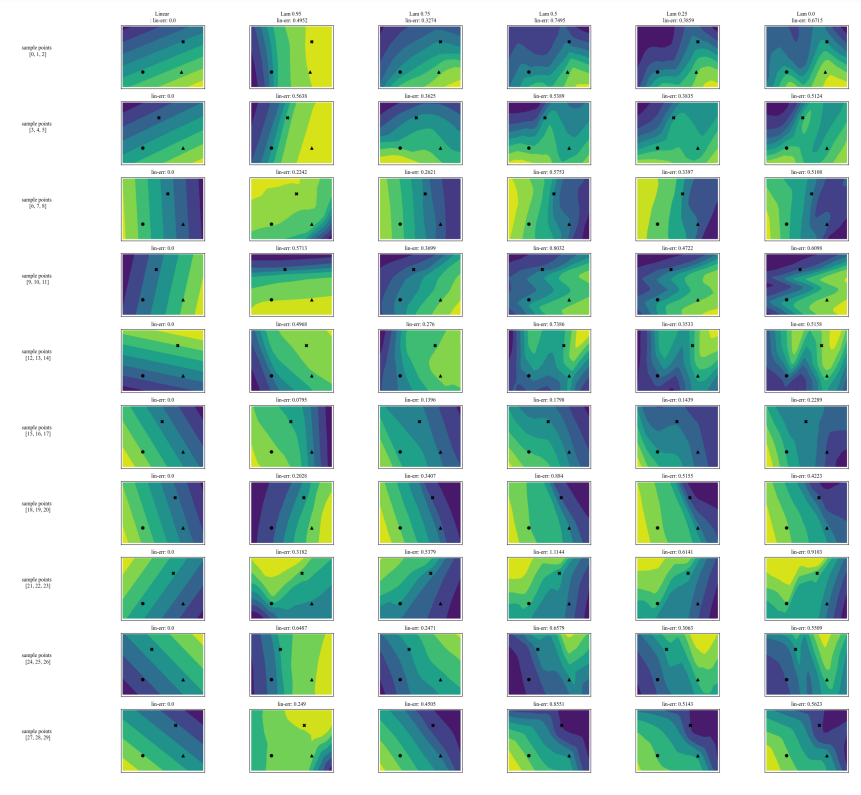
\ 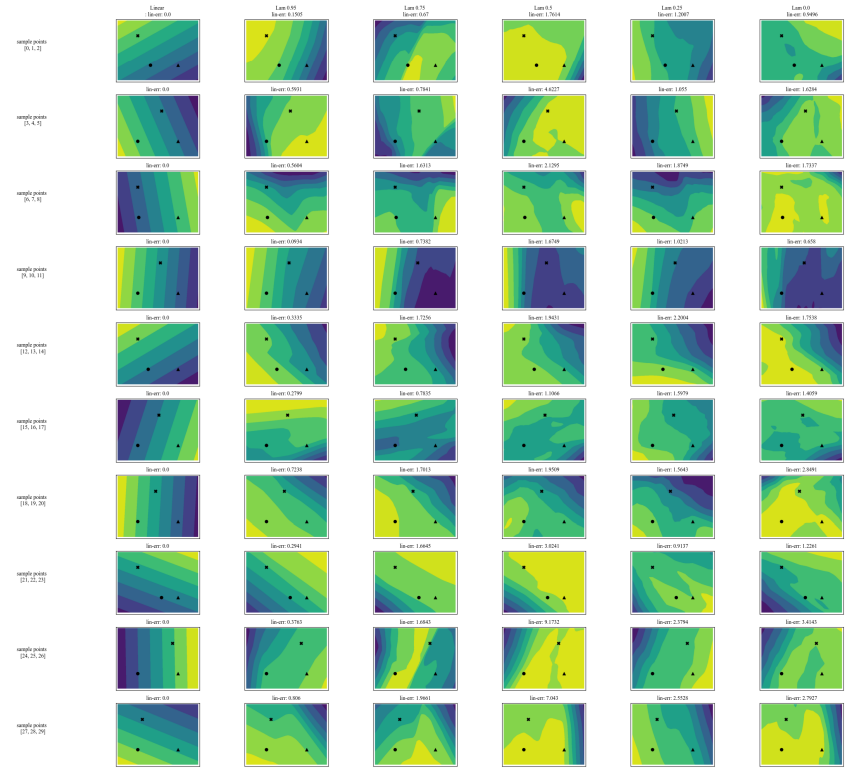
\ 
\
:::info Autores:
(1) Avi Schwarzschild, Universidade de Maryland, College Park, Maryland, EUA e Trabalho concluído enquanto trabalhava na Arthur (avi1umd.edu);
(2) Max Cembalest, Arthur, Nova Iorque, Nova Iorque, EUA;
(3) Karthik Rao, Arthur, Nova Iorque, Nova Iorque, EUA;
(4) Keegan Hines, Arthur, Nova Iorque, Nova Iorque, EUA;
(5) John Dickerson†, Arthur, Nova Iorque, Nova Iorque, EUA (john@arthur.ai).
:::
:::info Este artigo está disponível no arxiv sob licença CC BY 4.0 DEED.
:::
\


Você também pode gostar

Previsão do Preço do Ouro: Navegando a Volatilidade de Curto Prazo Antes de uma Recuperação Crítica em 2026

Aave đối mặt phép thử đầu tiên với mô hình rủi ro 42 tỷ USD sau Chaos Labs rời đi




