

Como a Mistura de Adaptações Torna o Ajuste Fino de Modelos de Linguagem Mais Barato e Inteligente
Tabela de Links
Resumo e 1. Introdução
-
Contexto
2.1 Mistura de Especialistas
2.2 Adaptadores
-
Mistura de Adaptações
3.1 Política de Roteamento
3.2 Regularização de consistência
3.3 Fusão do módulo de adaptação e 3.4 Compartilhamento do módulo de adaptação
3.5 Conexão com Redes Neurais Bayesianas e Ensemble de Modelos
-
Experiências
4.1 Configuração Experimental
4.2 Resultados Principais
4.3 Estudo de Ablação
-
Trabalhos Relacionados
-
Conclusões
-
Limitações
-
Agradecimentos e Referências
Apêndice
A. Conjuntos de Dados NLU de Poucos Exemplos B. Estudo de Ablação C. Resultados Detalhados em Tarefas NLU D. Hiperparâmetro
3 Mistura de Adaptações

\
3.1 Política de Roteamento
Trabalhos recentes como THOR (Zuo et al., 2021) demonstraram que políticas de roteamento estocástico como roteamento aleatório funcionam tão bem quanto mecanismos de roteamento clássicos como Switch routing (Fedus et al., 2021) com os seguintes benefícios. Como os exemplos de entrada são roteados aleatoriamente para diferentes especialistas, não há necessidade de balanceamento de carga adicional, pois cada especialista tem igual oportunidade de ser ativado, simplificando a estrutura. Além disso, não há parâmetros adicionais e, portanto, nenhum cálculo adicional na camada Switch para seleção de especialistas. Este último é particularmente importante em nossa configuração para ajuste fino eficiente em parâmetros, mantendo os parâmetros e FLOPs iguais aos de um único módulo de adaptação. Para analisar o funcionamento do AdaMix, demonstramos conexões com roteamento estocástico e média de peso do modelo para Redes Neurais Bayesianas e ensemble de modelos na Seção 3.5.
\ \ 
\ \ Esse roteamento estocástico permite que os módulos de adaptação aprendam diferentes transformações durante o treinamento e obtenham múltiplas visões da tarefa. No entanto, isso também cria um desafio sobre quais módulos usar durante a inferência devido ao protocolo de roteamento aleatório durante o treinamento. Abordamos esse desafio com as duas técnicas a seguir que nos permitem colapsar módulos de adaptação e obter o mesmo custo computacional (FLOPs, parâmetros de adaptação ajustáveis) que o de um único módulo.
3.2 Regularização de consistência
\ 
\ \ \ 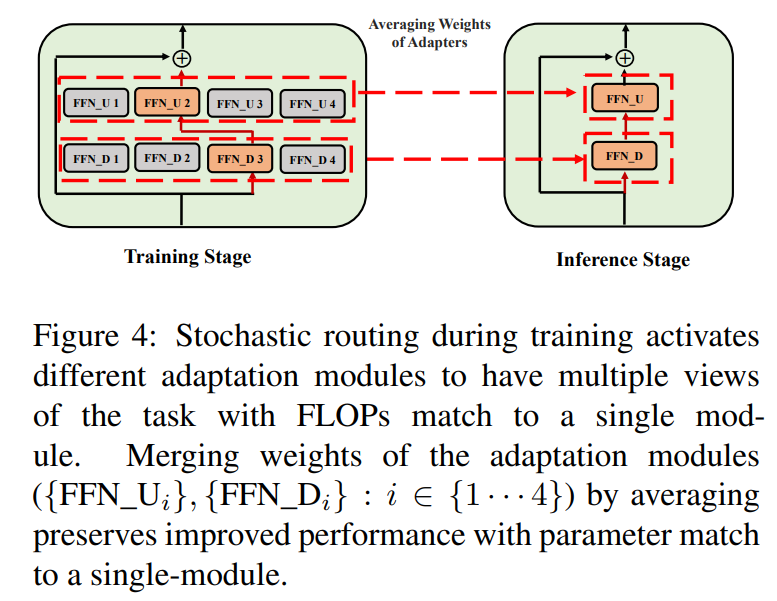
3.3 Fusão do módulo de adaptação
Embora a regularização acima mitigue a inconsistência na seleção aleatória de módulos durante a inferência, ainda resulta em aumento do custo de serviço para hospedar vários módulos de adaptação. Trabalhos anteriores no ajuste fino de modelos de linguagem para tarefas downstream mostraram desempenho aprimorado ao calcular a média dos pesos de diferentes modelos ajustados com diferentes sementes aleatórias, superando um único modelo ajustado. Trabalhos recentes (Wortsman et al., 2022) também mostraram que modelos ajustados de forma diferente a partir da mesma inicialização estão na mesma bacia de erro, motivando o uso de agregação de peso para resumo robusto de tarefas. Adotamos e estendemos técnicas anteriores para ajuste fino de modelos de linguagem para nosso treinamento eficiente em parâmetros de módulos de adaptação multi-visão
\ \ 
\
3.4 Compartilhamento do módulo de adaptação
\ 
3.5 Conexão com Redes Neurais Bayesianas e Ensemble de Modelos
\ 
\ \ Isso requer calcular a média sobre todos os pesos de modelo possíveis, o que é intratável na prática. Portanto, vários métodos de aproximação foram desenvolvidos com base em métodos de inferência variacional e técnicas de regularização estocástica usando dropouts. Neste trabalho, aproveitamos outra regularização estocástica na forma de roteamento aleatório. Aqui, o objetivo é encontrar uma distribuição substituta qθ(w) em uma família tratável de distribuições que possa substituir o posterior do modelo verdadeiro que é difícil de calcular. O substituto ideal é identificado minimizando a divergência Kullback-Leibler (KL) entre o candidato e o posterior verdadeiro.
\ \ 
\ \ \ 
\ \ \ 
\ \ \ \
:::info Autores:
(1) Yaqing Wang, Purdue University (wang5075@purdue.edu);
(2) Sahaj Agarwal, Microsoft (sahagar@microsoft.com);
(3) Subhabrata Mukherjee, Microsoft Research (submukhe@microsoft.com);
(4) Xiaodong Liu, Microsoft Research (xiaodl@microsoft.com);
(5) Jing Gao, Purdue University (jinggao@purdue.edu);
(6) Ahmed Hassan Awadallah, Microsoft Research (hassanam@microsoft.com);
(7) Jianfeng Gao, Microsoft Research (jfgao@microsoft.com).
:::
:::info Este artigo está disponível no arxiv sob licença CC BY 4.0 DEED.
:::
\


Você também pode gostar

Lighter mua lại 10 triệu LIT từ TGE, bằng 4% nguồn lưu hành

Binance.US Visa o Renascimento: Novos Empreendimentos e Reconstrução da Confiança em Foco




