

Como o Toto reinventa a Atenção Multi-Cabeça para Previsão Multivariada

Tabela de Links
- Background
- Declaração do problema
- Arquitetura do modelo
- Dados de treino
- Resultados
- Conclusões
- Declaração de impacto
- Direções futuras
- Contribuições
- Agradecimentos e Referências
Apêndice
3 Arquitetura do modelo
Toto é um modelo de previsão apenas com decodificador. Este modelo emprega muitas das técnicas mais recentes da literatura e introduz um método inovador para adaptar a atenção multi-cabeça a dados de séries temporais multivariadas (Fig. 1).
\ 3.1 Design do Transformer
\ Os modelos Transformer para previsão de séries temporais têm utilizado várias arquiteturas: codificador-decodificador [12, 13, 21], apenas codificador [14, 15, 17] e apenas decodificador [19, 23]. Para o Toto, empregamos uma arquitetura apenas com decodificador. As arquiteturas de decodificador demonstraram escalar bem [25, 26] e permitem horizontes de previsão arbitrários. A tarefa causal de previsão do próximo patch também simplifica o processo de pré-treino.
\ Utilizamos técnicas de algumas das mais recentes arquiteturas de modelos de linguagem grandes (LLM), incluindo pré-normalização [27], RMSNorm [28] e camadas feed-forward SwiGLU [29].
\ 3.2 Incorporação de entrada
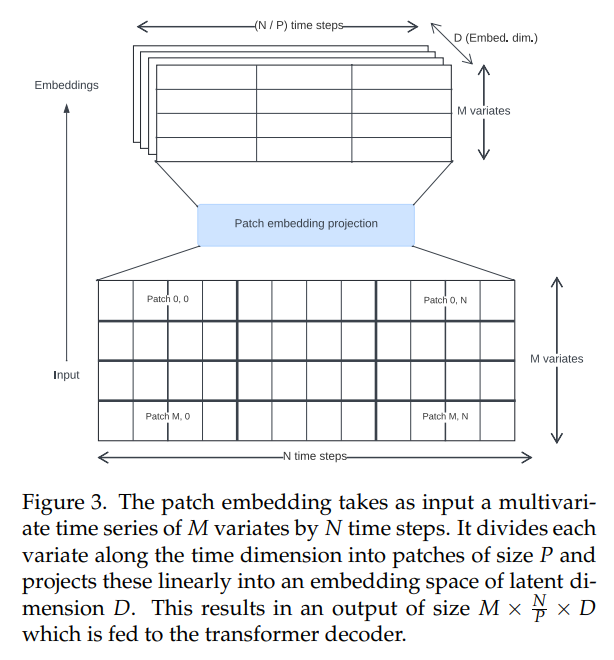
\ Os transformers de séries temporais na literatura têm utilizado várias abordagens para criar incorporações de entrada. Utilizamos projeções de patches não sobrepostos (Fig. 3), introduzidas pela primeira vez para Vision Transformers [30, 31] e popularizadas no contexto de séries temporais pelo PatchTST [14]. O Toto foi treinado usando um tamanho fixo de patch de 32.
\ 
\ 3.3 Mecanismo de atenção
\ As métricas de observabilidade são frequentemente séries temporais multivariadas de alta cardinalidade. Portanto, um modelo ideal lidará nativamente com previsões multivariadas. Deve ser capaz de analisar relações tanto na dimensão temporal (o que chamamos de interações "time-wise") quanto na dimensão do canal (o que chamamos de interações "space-wise", seguindo a convenção na plataforma Datadog de descrever diferentes grupos ou conjuntos de tags de uma métrica como a dimensão "espaço").
\ Para modelar interações tanto espaciais quanto temporais, precisamos adaptar a arquitetura tradicional de atenção multi-cabeça [11] de uma para duas dimensões. Várias abordagens foram propostas na literatura para fazer isso, incluindo:
\ • Assumir independência de canal e calcular a atenção apenas na dimensão temporal [14]. Isso é eficiente, mas descarta todas as informações sobre interações espaciais.
\ • Calcular a atenção apenas na dimensão espacial e usar uma rede feed-forward na dimensão temporal [17, 18].
\ • Concatenar variáveis ao longo da dimensão temporal e calcular atenção cruzada completa entre cada localização espaço/tempo [15]. Isso pode capturar todas as possíveis interações de espaço e tempo, mas é computacionalmente custoso.
\ • Calcular "atenção fatorizada", onde cada bloco transformer contém um cálculo de atenção separado para espaço e tempo [16, 32, 33]. Isso permite a mistura de espaço e tempo, e é mais eficiente que a atenção cruzada completa. No entanto, duplica a profundidade efetiva da rede.
\ Para projetar nosso mecanismo de atenção, seguimos a intuição de que para muitas séries temporais, as relações temporais são mais importantes ou preditivas do que as relações espaciais. Como evidência, observamos que mesmo modelos que ignoram completamente as relações espaciais (como PatchTST [14] e TimesFM [19]) ainda podem alcançar desempenho competitivo em conjuntos de dados multivariados. No entanto, outros estudos (por exemplo, Moirai [15]) demonstraram através de ablações que há algum benefício claro em incluir relações espaciais.
\ Portanto, propomos uma nova variante de atenção fatorizada, que chamamos de "Atenção Espaço-Temporal Fatorizada Proporcional". Utilizamos uma mistura de blocos de atenção espacial e temporal alternados. Como um hiperparâmetro configurável, podemos alterar a proporção de blocos temporais para espaciais, permitindo-nos dedicar mais ou menos orçamento computacional a cada tipo de atenção. Para nosso modelo base, selecionamos uma configuração com um bloco de atenção espacial para cada dois blocos temporais.
\ Nos blocos de atenção temporal, usamos mascaramento causal e incorporações posicionais rotativas [34] com XPOS [35] para modelar autoregressivamente características dependentes do tempo. Nos blocos espaciais, em contraste, usamos atenção bidirecional completa para preservar a invariância de permutação das covariáveis, com uma máscara de ID em bloco diagonal para garantir que apenas variáveis relacionadas prestem atenção umas às outras. Este mascaramento nos permite empacotar múltiplas séries temporais multivariadas independentes no mesmo lote, a fim de melhorar a eficiência do treino e reduzir a quantidade de preenchimento.
\ 3.4 Cabeça de previsão probabilística
\ Para ser útil em aplicações de previsão, um modelo deve produzir previsões probabilísticas. Uma prática comum em modelos de séries temporais é usar uma camada de saída onde o modelo regride os parâmetros de uma distribuição de probabilidade. Isso permite que intervalos de previsão sejam calculados usando amostragem de Monte Carlo [7].
\ Escolhas comuns para uma camada de saída são Normal [7] e Student-T [23, 36], que podem melhorar a robustez a outliers. Moirai [15] permite distribuições residuais mais flexíveis ao propor um novo modelo de mistura incorporando uma combinação ponderada de saídas Gaussianas, Student-T, Log-Normal e Binomial Negativa.
\ No entanto, séries temporais do mundo real frequentemente têm distribuições complexas que são desafiadoras de ajustar, com outliers, caudas pesadas, assimetria extrema e multimodalidade. Para acomodar esses cenários, introduzimos uma verossimilhança de saída ainda mais flexível. Para isso, empregamos um método baseado em modelos de mistura Gaussiana (GMMs), que podem aproximar qualquer função de densidade ([37]). Para evitar instabilidade de treino na presença de outliers, usamos um modelo de mistura Student-T (SMM), uma generalização robusta dos GMMs [38] que anteriormente mostrou promessa para modelar séries temporais financeiras de cauda pesada [39, 40]. O modelo prevê k distribuições Student-T (onde k é um hiperparâmetro) para cada passo de tempo, bem como uma ponderação aprendida.
\ 
\ Quando realizamos inferência, extraímos amostras da distribuição de mistura em cada timestamp, depois alimentamos cada amostra de volta ao decodificador para a próxima previsão. Isso nos permite produzir intervalos de previsão em qualquer quantil, limitados apenas pelo número de amostras; para caudas mais precisas, podemos optar por gastar mais computação na amostragem (Fig. 2).
\ 3.5 Escalonamento de entrada/saída
\ Como em outros modelos de séries temporais, realizamos normalização de instância nos dados de entrada antes de passá-los pela incorporação de patch, a fim de fazer o modelo generalizar melhor para entradas de diferentes escalas [41]. Escalonamos as entradas para terem média zero e desvio padrão unitário. As previsões de saída são então reescalonadas de volta para as unidades originais.
\ 3.6 Objetivo de treino
\ Como um modelo apenas com decodificador, o Toto é pré-treinado na tarefa de previsão do próximo patch. Minimizamos a log-verossimilhança negativa do próximo patch previsto em relação à saída de distribuição do modelo. Treinamos o modelo usando o otimizador AdamW [42].
\ 3.7 Hiperparâmetros
\ Os hiperparâmetros usados para o Toto estão detalhados na Tabela A.1, com um total de 103 milhões de parâmetros.
\
:::info Autores:
(1) Ben Cohen (ben.cohen@datadoghq.com);
(2) Emaad Khwaja (emaad@datadoghq.com);
(3) Kan Wang (kan.wang@datadoghq.com);
(4) Charles Masson (charles.masson@datadoghq.com);
(5) Elise Rame (elise.rame@datadoghq.com);
(6) Youssef Doubli (youssef.doubli@datadoghq.com);
(7) Othmane Abou-Amal (othmane@datadoghq.com).
:::
:::info Este artigo está disponível no arxiv sob licença CC BY 4.0.
:::
\


Você também pode gostar
Ethena tăng 11,4%: Tín hiệu này đảo chiều, ENA sắp bứt phá?

Bộ Tài chính Mỹ và Fed họp khẩn về rủi ro AI Anthropic




