

Como os Modelos de IA Híbridos Equilibram Memória e Eficiência
Tabela de Links
Resumo e 1. Introdução
-
Metodologia
-
Experiências e Resultados
3.1 Modelagem de Linguagem em Dados de vQuality
3.2 Exploração em Atenção e Recorrência Linear
3.3 Extrapolação Eficiente de Comprimento
3.4 Compreensão de Contexto Longo
-
Análise
-
Conclusão, Agradecimentos e Referências
A. Detalhes de Implementação
B. Resultados Adicionais de Experiências
C. Detalhes da Medição de Entropia
D. Limitações
\
A Detalhes de Implementação
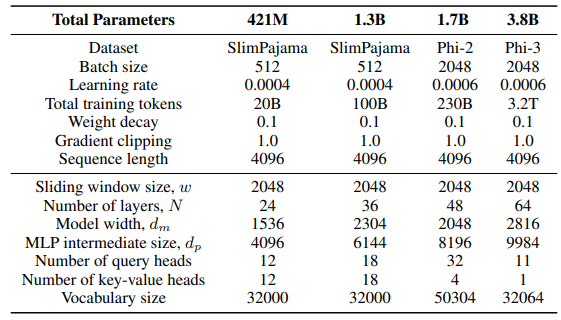
\ Para a camada GLA na arquitetura Sliding GLA, utilizamos o número de cabeças dm/384, uma proporção de expansão de chave de 0,5 e uma proporção de expansão de valor de 1. Para a camada RetNet, utilizamos um número de cabeças que é metade do número de cabeças de consulta de atenção, proporção de expansão de chave de 1 e proporção de expansão de valor de 2. As implementações de GLA e RetNet são do repositório Flash Linear Attention[3] [YZ24]. Utilizamos a implementação baseada em FlashAttention para extrapolação Self-Extend[4]. O modelo Mamba 432M tem uma largura de modelo de 1024 e o modelo Mamba 1.3B tem uma largura de modelo de 2048. Todos os modelos treinados no SlimPajama têm as mesmas configurações de treino e o tamanho intermediário MLP como o Samba, a menos que especificado de outra forma. A infraestrutura de treino no SlimPajama é baseada numa versão modificada do código base TinyLlama[5].
\ 
\ Nas configurações de geração para as tarefas downstream, utilizamos decodificação greedy para GSM8K e Nucleus Sampling [HBD+19] com uma temperatura de τ = 0,2 e top-p = 0,95 para HumanEval. Para MBPP e SQuAD, definimos τ = 0,01 e top-p = 0,95.
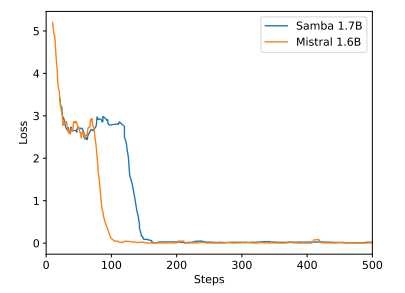
B Resultados Adicionais de Experiências
\ 
\ 
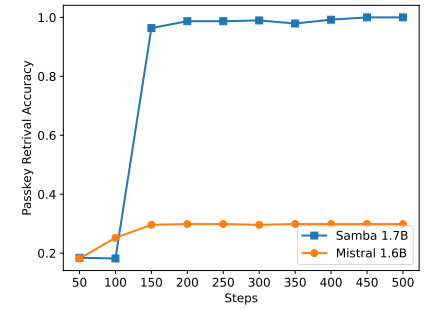
\ 
\
C Detalhes da Medição de Entropia
\ 
\
D Limitações
Embora o Samba demonstre um desempenho promissor de recuperação de memória através do ajuste de instrução, o seu modelo base pré-treinado tem um desempenho de recuperação semelhante ao do modelo baseado em SWA, como mostrado na Figura 7. Isto abre uma direção futura para melhorar ainda mais a capacidade de recuperação do Samba sem comprometer a sua eficiência e capacidade de extrapolação. Além disso, a estratégia de hibridização do Samba não é consistentemente melhor do que outras alternativas em todas as tarefas. Como mostrado na Tabela 2, MambaSWA-MLP mostra desempenho melhorado em tarefas como WinoGrande, SIQA e GSM8K. Isto dá-nos o potencial para investir numa abordagem mais sofisticada para realizar combinações dinâmicas dependentes de entrada de modelos baseados em SWA e baseados em SSM.
\
:::info Autores:
(1) Liliang Ren, Microsoft e University of Illinois at Urbana-Champaign (liliangren@microsoft.com);
(2) Yang Liu†, Microsoft (yaliu10@microsoft.com);
(3) Yadong Lu†, Microsoft (yadonglu@microsoft.com);
(4) Yelong Shen, Microsoft (yelong.shen@microsoft.com);
(5) Chen Liang, Microsoft (chenliang1@microsoft.com);
(6) Weizhu Chen, Microsoft (wzchen@microsoft.com).
:::
:::info Este artigo está disponível no arxiv sob licença CC BY 4.0.
:::
[3] https://github.com/sustcsonglin/flash-linear-attention
\ [4] https://github.com/datamllab/LongLM/blob/master/selfextendpatch/Llama.py
\ [5] https://github.com/jzhang38/TinyLlama
Você também pode gostar

Comissão de Valores Mobiliários dos Estados Unidos emite guia de custódia de cripto para investidores de retalho

SEC emite guia para investidores sobre carteiras cripto e riscos de custódia
