Estudo de ablação confirma necessidade de taxas dinâmicas para o desempenho do RECKONING
Tabela de Links
Resumo e 1. Introdução
-
Antecedentes
-
Método
-
Experiências
4.1 Desempenho de Raciocínio Multi-hop
4.2 Raciocínio com Distratores
4.3 Generalização para Conhecimento do Mundo Real
4.4 Análise de Tempo de Execução
4.5 Memorização de Conhecimento
-
Trabalhos Relacionados
-
Conclusão, Agradecimentos e Referências
\ A. Conjunto de Dados
B. Raciocínio em Contexto com Distratores
C. Detalhes de Implementação
D. Taxa de Aprendizagem Adaptativa
E. Experiências com Modelos de Linguagem Grandes
D Taxa de Aprendizagem Adaptativa
Trabalhos anteriores [3, 4] mostram que uma taxa de aprendizagem fixa compartilhada entre etapas e parâmetros não beneficia o desempenho de generalização do sistema. Em vez disso, [3] recomenda aprender uma taxa de aprendizagem para
\ 
\ 
\ cada camada de rede e cada etapa de adaptação no loop interno. Os parâmetros da camada podem aprender a ajustar as taxas de aprendizagem dinamicamente em cada etapa. Para controlar a taxa de aprendizagem α no loop interno de forma adaptativa, definimos α como um conjunto de variáveis ajustáveis: α = {α0, α1, …αL}, onde L é o número de camadas e para cada l = 0, …, L, αl é um vetor com N elementos dado um número de etapas de loop interno pré-definido N. A equação de atualização do loop interno torna-se então
\ 
\ 
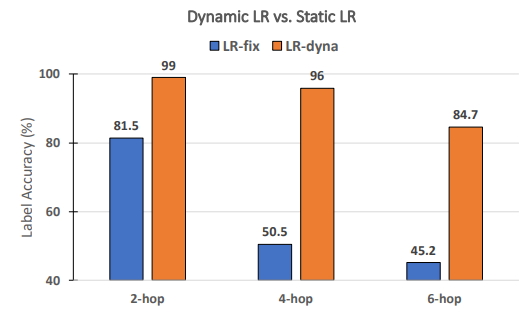
\ As taxas de aprendizagem dinâmicas são necessárias para o desempenho do RECKONING? Seguindo trabalhos anteriores sobre meta-aprendizagem [3, 4], aprendemos dinamicamente um conjunto de taxas de aprendizagem por etapa e por camada para o RECKONING. Neste estudo de ablação, analisamos se as taxas de aprendizagem dinâmicas para o loop interno melhoram efetivamente o desempenho de raciocínio do loop externo. Da mesma forma, fixamos outras configurações experimentais e definimos o número de etapas do loop interno para 4. Como mostra a Figura 8, ao usar uma taxa de aprendizagem estática (ou seja, todas as camadas e etapas do loop interno compartilham uma taxa de aprendizagem constante), o desempenho cai por uma grande margem (queda média de 34,2%). A queda de desempenho torna-se mais significativa em questões que requerem mais saltos de raciocínio (queda de 45,5% para 4 saltos e 39,5% para 6 saltos), demonstrando a importância de usar uma taxa de aprendizagem dinâmica no loop interno do nosso framework.
\ 
\
:::info Autores:
(1) Zeming Chen, EPFL (zeming.chen@epfl.ch);
(2) Gail Weiss, EPFL (antoine.bosselut@epfl.ch);
(3) Eric Mitchell, Stanford University (eric.mitchell@cs.stanford.edu)';
(4) Asli Celikyilmaz, Meta AI Research (aslic@meta.com);
(5) Antoine Bosselut, EPFL (antoine.bosselut@epfl.ch).
:::
:::info Este artigo está disponível no arxiv sob licença CC BY 4.0 DEED.
:::
\


Você também pode gostar

Nhà đầu tư dự báo SIREN tăng thêm 150% sau cú rally 300%?

OKX đầu tư vào CAEX giúp sàn crypto của VPBank đạt yêu cầu vốn điều lệ 10.000 tỷ đồng