

Eis o Motivo Pelo Qual os Investigadores de IA Estão a Falar Sobre o Treino Espectral Esparso

Tabela de Links
Abstrato e 1. Introdução
-
Trabalhos Relacionados
-
Adaptação de Baixo Rank
3.1 LoRA e 3.2 Limitação do LoRA
3.3 ReLoRA*
-
Treino Espectral Esparso
4.1 Preliminares e 4.2 Atualização de Gradiente de U, VT com Σ
4.3 Por que a Inicialização SVD é Importante
4.4 SST Equilibra Exploração e Exploração
4.5 Implementação Eficiente em Memória para SST e 4.6 Esparsidade do SST
-
Experiências
5.1 Tradução Automática
5.2 Geração de Linguagem Natural
5.3 Redes Neurais Hiperbólicas de Grafos
-
Conclusão e Discussão
-
Impactos Mais Amplos e Referências
Informação Suplementar
A. Algoritmo de Treino Espectral Esparso
B. Prova do Gradiente da Camada Espectral Esparsa
C. Prova da Decomposição do Gradiente do Peso
D. Prova da Vantagem do Gradiente Melhorado sobre o Gradiente Padrão
E. Prova de Distorção Zero com Inicialização SVD
F. Detalhes da Experiência
G. Poda de Valor Singular
H. Avaliando SST e GaLore: Abordagens Complementares para Eficiência de Memória
I. Estudo de Ablação
A Algoritmo de Treino Espectral Esparso
B Prova do Gradiente da Camada Espectral Esparsa
Podemos expressar o diferencial de W como a soma de diferenciais:
\ \ 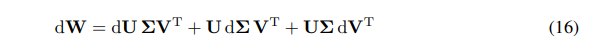
\ \ Temos a regra da cadeia para o gradiente de W:
\ \ 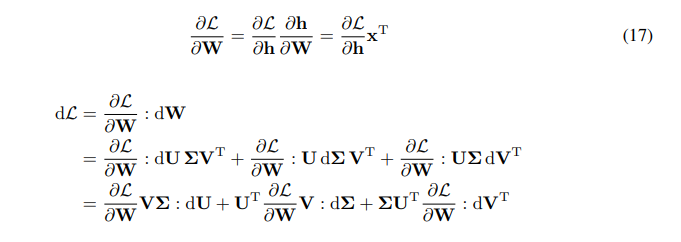
\ \ \ 
\
C Prova da Decomposição do Gradiente do Peso
\ 
\
D Prova da Vantagem do Gradiente Melhorado sobre o Gradiente Padrão
\ 
\ \ \ 
\ \ \ 
\ \ Como apenas a direção da atualização importa, a escala da atualização pode ser ajustada alterando a taxa de aprendizagem. Medimos a similaridade usando a norma de Frobenius das diferenças entre as atualizações SST e 3 vezes a atualização de rank completo.
\ \ 
\
E Prova de Distorção Zero com Inicialização SVD
\ 
F Detalhes da Experiência
F.1 Detalhes de Implementação para SST
\ 
\ \ \ 
\
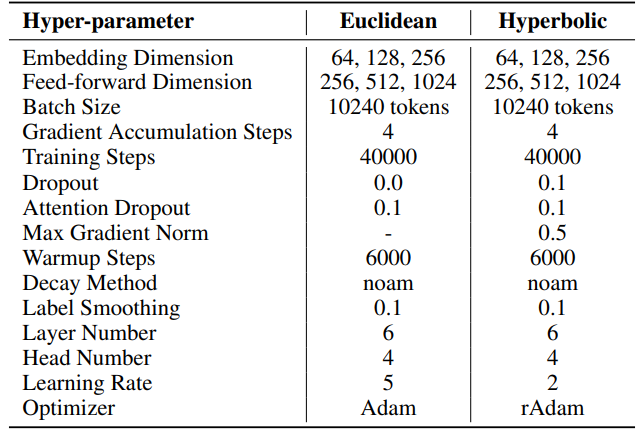
F.2 Hiperparâmetros da Tradução Automática
IWSLT'14. Os hiperparâmetros podem ser encontrados na Tabela 6. Empregamos a mesma base de código e hiperparâmetros utilizados no HyboNet [12], derivado do OpenNMT-py [54]. O checkpoint final do modelo é utilizado para avaliação. A pesquisa em feixe, com um tamanho de feixe de 2, é empregada para otimizar o processo de avaliação. As experiências foram realizadas numa GPU A100.
\ Para SST, o número de passos por iteração (T3) é definido como 200. Cada iteração começa com uma fase de aquecimento que dura 20 passos. O número de iterações por ronda (T2) é determinado pela fórmula T2 = d/r, onde d representa a dimensão de incorporação e r denota o rank usado no SST.
\ \ 
\ \ \ 
\ \ Para SST, o número de passos por iteração (T3) é definido como 200 para Multi30K e 400 para IWSLT'17. Cada iteração começa com uma fase de aquecimento que dura 20 passos. O número de iterações por ronda (T2) é determinado pela fórmula T2 = d/r, onde d representa a dimensão de incorporação e r denota o rank usado no SST
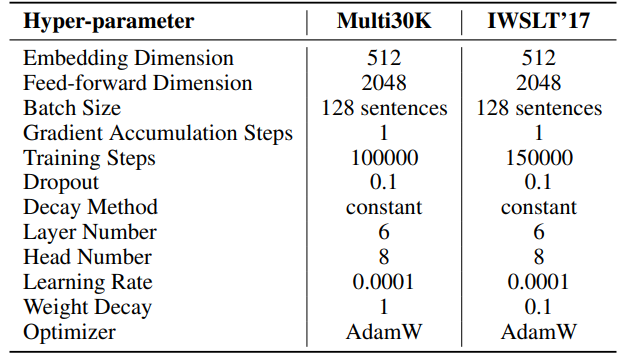
F.3 Hiperparâmetros da Geração de Linguagem Natural
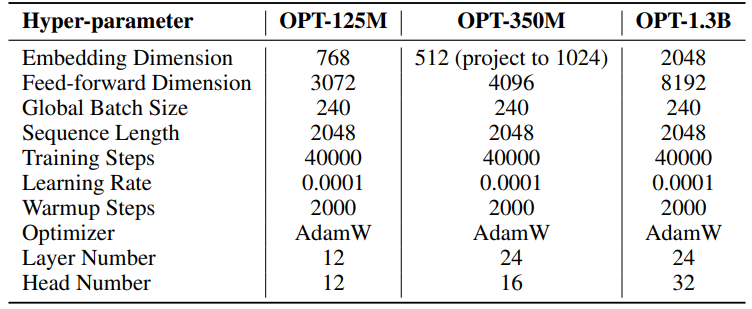
Os hiperparâmetros para as nossas experiências estão detalhados na Tabela 8. Empregamos um aquecimento linear de 2000 passos seguido por uma taxa de aprendizagem estável, sem decaimento. Uma taxa de aprendizagem maior (0,001) é usada apenas para parâmetros de baixo rank (U, VT e Σ para SST, B e A para LoRA e ReLoRA*. O total de tokens de treino para cada experiência é 19,7B, aproximadamente 2 épocas de OpenWebText. O treino distribuído é facilitado usando a biblioteca Accelerate [55] em quatro GPUs A100 num servidor Linux.
\ Para SST, o número de passos por iteração (T3) é definido como 200. Cada iteração começa com uma fase de aquecimento que dura 20 passos. O número de iterações por ronda (T2) é determinado pela fórmula T2 = d/r, onde d representa a dimensão de incorporação e r denota o rank usado no SST.
\ \ 
\ \ \ 
\
F.4 Hiperparâmetros das Redes Neurais Hiperbólicas de Grafos
Usamos o HyboNet [12] como modelo de rank completo, com os mesmos hiperparâmetros utilizados no HyboNet. As experiências foram realizadas numa GPU A100.
\ Para SST, o número de passos por iteração (T3) é definido como 100. Cada iteração começa com uma fase de aquecimento que dura 100 passos. O número de iterações por ronda (T2) é determinado pela fórmula T2 = d/r, onde d representa a dimensão de incorporação e r denota o rank usado no SST.
\ Definimos a taxa de dropout para 0,5 para os métodos LoRA e SST durante a tarefa de classificação de nós no conjunto de dados Cora. Este é o único desvio da configuração do HyboNet.
\ \ \
:::info Autores:
(1) Jialin Zhao, Centro de Inteligência de Redes Complexas (CCNI), Laboratório de Cérebro e Inteligência de Tsinghua (THBI) e Departamento de Ciência da Computação;
(2) Yingtao Zhang, Centro de Inteligência de Redes Complexas (CCNI), Laboratório de Cérebro e Inteligência de Tsinghua (THBI) e Departamento de Ciência da Computação;
(3) Xinghang Li, Departamento de Ciência da Computação;
(4) Huaping Liu, Departamento de Ciência da Computação;
(5) Carlo Vittorio Cannistraci, Centro de Inteligência de Redes Complexas (CCNI), Laboratório de Cérebro e Inteligência de Tsinghua (THBI), Departamento de Ciência da Computação e Departamento de Engenharia Biomédica da Universidade de Tsinghua, Pequim, China.
:::
:::info Este artigo está disponível no arxiv sob a licença CC by 4.0 Deed (Atribuição 4.0 Internacional).
:::
\


Você também pode gostar

Nguồn cung lưu hành USDC tăng khoảng 1,2 tỷ coin trong 7 ngày qua
Giao dịch Avalanche lập đỉnh 2026: AVAX có về lại 10 USD?




