

Ensinando a IA a Ver e Falar: Por Dentro da Abordagem OW-VISCap
Tabela de Links
Resumo e 1. Introdução
-
Trabalhos Relacionados
2.1 Segmentação de Instâncias de Vídeo em Mundo Aberto
2.2 Legendagem Densa de Objetos em Vídeo e 2.3 Perda Contrastiva para Consultas de Objetos
2.4 Compreensão Generalizada de Vídeo e 2.5 Segmentação de Instâncias de Vídeo em Mundo Fechado
-
Abordagem
3.1 Visão Geral
3.2 Consultas de Objetos em Mundo Aberto
3.3 Cabeçalho de Legendagem
3.4 Perda Contrastiva Inter-Consulta e 3.5 Treinamento
-
Experiências e 4.1 Conjuntos de Dados e Métricas de Avaliação
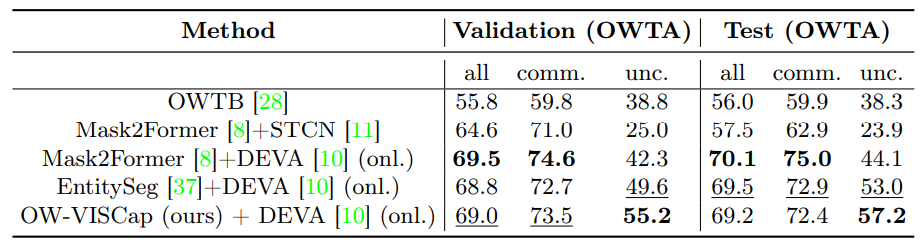
4.2 Resultados Principais
4.3 Estudos de Ablação e 4.4 Resultados Qualitativos
-
Conclusão, Agradecimentos e Referências
\ Material Suplementar
A. Análise Adicional
B. Detalhes de Implementação
C. Limitações
3 Abordagem
Dado um vídeo, o nosso objetivo é detetar, segmentar e legendar conjuntamente as instâncias de objetos presentes no vídeo. É importante notar que as categorias de instâncias de objetos podem não fazer parte do conjunto de treino (por exemplo, os paraquedas mostrados na Fig. 3 (linha superior)), colocando o nosso objetivo num cenário de mundo aberto. Para atingir este objetivo, um vídeo é primeiro dividido em pequenos clipes, cada um consistindo em T frames. Cada clipe é processado usando a nossa abordagem OW-VISCap. Discutimos a fusão dos resultados de cada clipe na Sec. 4.
\ Fornecemos uma visão geral do OW-VISCap para processar cada clipe na Sec. 3.1. Em seguida, discutimos as nossas contribuições: (a) introdução de consultas de objetos em mundo aberto na Sec. 3.2, (b) uso de atenção mascarada para legendagem centrada em objetos na Sec. 3.3, e (c) uso de perda contrastiva inter-consulta para garantir que as consultas de objetos sejam diferentes umas das outras na Sec. 3.4. Na Sec. 3.5, discutimos o objetivo final de treinamento.
3.1 Visão Geral
\ Tanto as consultas de objetos de mundo aberto quanto as de mundo fechado são processadas pelo nosso cabeçalho de legendagem especificamente projetado, que produz uma legenda centrada no objeto, um cabeçalho de classificação que produz um rótulo de categoria, e um cabeçalho de deteção que produz uma máscara de segmentação ou uma caixa delimitadora.
\ 
\ Introduzimos uma perda contrastiva inter-consulta para garantir que as consultas de objetos sejam incentivadas a diferir umas das outras. Fornecemos detalhes na Sec. 3.4. Para objetos de mundo fechado, esta perda ajuda a remover falsos positivos altamente sobrepostos. Para objetos de mundo aberto, ajuda na descoberta de novos objetos.
\ Finalmente, fornecemos o objetivo completo de treinamento na Sec. 3.5.
\
3.2 Consultas de Objetos em Mundo Aberto
\ 
\ 
\ Primeiro, correspondemos os objetos de verdade fundamental com as previsões de mundo aberto minimizando um custo de correspondência usando o algoritmo húngaro [34]. A correspondência ótima é então usada para calcular a perda final de mundo aberto.
\ 
\
3.3 Cabeçalho de Legendagem
\ 
\
3.4 Perda Contrastiva Inter-Consulta
\ 
\
3.5 Treinamento
Nossa perda total de treinamento é
\ 
\ ![Tabela 2: Resultados de legendagem densa de objetos em vídeo no conjunto de dados VidSTG [57]. Off. indica métodos offline e onl. refere-se a métodos online.](https://cdn.hackernoon.com/images/null-0v3336a.png)
\
:::info Autores:
(1) Anwesa Choudhuri, Universidade de Illinois em Urbana-Champaign (anwesac2@illinois.edu);
(2) Girish Chowdhary, Universidade de Illinois em Urbana-Champaign (girishc@illinois.edu);
(3) Alexander G. Schwing, Universidade de Illinois em Urbana-Champaign (aschwing@illinois.edu).
:::
:::info Este artigo está disponível no arxiv sob a licença CC by 4.0 Deed (Atribuição 4.0 Internacional).
:::
\


Você também pode gostar

Nhà đầu tư tập trung vào SIREN và ARIA

Ngân hàng Nhân dân Trung Quốc bổ sung 12 đơn vị kinh doanh RMB số




