

Solução para Escassez de Dados: S-CycleGAN para Tradução de TC para Ultrassom
Tabela de Links
Resumo e 1 Introdução
-
Trabalhos relacionados
-
Definição do problema
-
Metodologia
4.1. Destilação consciente da fronteira de decisão
4.2. Consolidação de conhecimento
-
Resultados experimentais e 5.1. Configuração do experimento
5.2. Comparação com métodos SOTA
5.3. Estudo de ablação
-
Conclusão e trabalho futuro e Referências
\
Material Suplementar
- Detalhes da análise teórica sobre o mecanismo KCEMA em IIL
- Visão geral do algoritmo
- Detalhes do conjunto de dados
- Detalhes de implementação
- Visualização de imagens de entrada empoeiradas
- Mais resultados experimentais
Resumo
A aprendizagem incremental de instâncias (IIL) concentra-se na aprendizagem contínua com dados das mesmas classes. Comparada à aprendizagem incremental de classes (CIL), a IIL é pouco explorada porque sofre menos com o esquecimento catastrófico (CF). No entanto, além de reter conhecimento, em cenários de implantação do mundo real onde o espaço de classes é sempre predefinido, a promoção contínua e econômica do modelo com a potencial indisponibilidade de dados anteriores é uma demanda mais essencial. Portanto, definimos primeiro uma nova e mais prática configuração IIL como promover o desempenho do modelo além de resistir ao CF apenas com novas observações. Duas questões precisam ser abordadas na nova configuração IIL: 1) o notório esquecimento catastrófico devido à falta de acesso aos dados antigos, e 2) ampliar a fronteira de decisão existente para novas observações devido à deriva conceitual. Para enfrentar esses problemas, nossa principal percepção é ampliar moderadamente a fronteira de decisão para casos de falha enquanto mantemos a fronteira antiga. Assim, propomos um novo método de destilação consciente da fronteira de decisão com consolidação de conhecimento para o professor para facilitar a aprendizagem de novos conhecimentos pelo aluno. Também estabelecemos os benchmarks em conjuntos de dados existentes Cifar-100 e ImageNet. Notavelmente, experimentos extensivos demonstram que o modelo professor pode ser um melhor aprendiz incremental do que o modelo aluno, o que inverte os métodos anteriores baseados em destilação de conhecimento que tratam o aluno como o papel principal.
1. Introdução
Nos últimos anos, muitas redes excelentes baseadas em aprendizagem profunda são propostas para uma variedade de tarefas, como classificação de imagens, segmentação e detecção. Embora essas redes tenham bom desempenho nos dados de treinamento, elas inevitavelmente falham em alguns novos dados que não são treinados na aplicação do mundo real. Promover contínua e eficientemente o desempenho de um modelo implantado nesses novos dados é uma demanda essencial. A solução atual de retreinar a rede usando todos os dados acumulados tem duas desvantagens: 1) com o aumento do tamanho dos dados, o custo de treinamento fica mais alto a cada vez, por exemplo, mais horas de GPUs e maior pegada de carbono [20], e 2) em alguns casos, os dados antigos não estão mais acessíveis devido à política de privacidade ou orçamento limitado para armazenamento de dados. No caso em que poucos ou nenhum dado antigo está disponível ou é utilizado, retreinar o modelo de aprendizagem profunda com novos dados sempre causa degradação de desempenho nos dados antigos, ou seja, o problema de esquecimento catastrófico (CF). Para resolver o problema CF, a aprendizagem incremental [4, 5, 22, 29], também conhecida como aprendizagem contínua, é proposta. A aprendizagem incremental promove significativamente o valor prático dos modelos de aprendizagem profunda e está atraindo intensos interesses de pesquisa.
\ 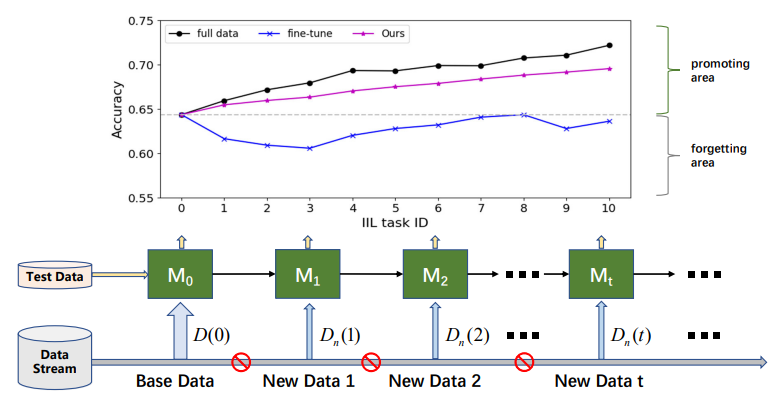
\ De acordo com se os novos dados vêm de classes vistas, a aprendizagem incremental pode ser dividida em três cenários [16, 17]: aprendizagem incremental de instâncias (IIL) [3, 16] onde todos os novos dados pertencem às classes vistas, aprendizagem incremental de classes (CIL) [4, 12, 15, 22] onde novos dados têm rótulos de classe diferentes, e aprendizagem incremental híbrida [6, 30] onde novos dados consistem em novas observações de classes antigas e novas. Comparado ao CIL, o IIL é relativamente inexplorado porque é menos suscetível ao CF. Lomonaco e Maltoni [16] relataram que o ajuste fino de um modelo com parada antecipada pode domar bem o problema CF em IIL. No entanto, essa conclusão nem sempre se mantém quando não há acesso aos dados de treinamento antigos e os novos dados têm um tamanho muito menor que os dados antigos, como mostrado na Fig. 1. O ajuste fino frequentemente resulta em uma mudança na fronteira de decisão em vez de expandi-la para acomodar novas observações. Além de reter conhecimento antigo, a implantação real se preocupa mais com a promoção eficiente do modelo em IIL. Por exemplo, na detecção de defeitos de produtos industriais, as classes de defeitos são sempre limitadas a categorias conhecidas. Mas a morfologia desses defeitos varia de tempos em tempos. Falhas nesses defeitos não vistos devem ser corrigidas de forma oportuna e eficiente para evitar que os produtos defeituosos cheguem ao mercado. Infelizmente, a pesquisa existente se concentra principalmente em reter conhecimento sobre dados antigos em vez de enriquecer o conhecimento com novas observações.
\ Neste artigo, para melhorar rápida e economicamente um modelo treinado com novas observações de classes vistas, primeiro definimos uma nova configuração IIL como reter o conhecimento aprendido e promover o desempenho do modelo em novas observações sem acesso a dados antigos. Em palavras simples, nosso objetivo é promover o modelo existente aproveitando apenas os novos dados e atingir um desempenho comparável ao modelo retreinado com todos os dados acumulados. O novo IIL é desafiador devido à deriva conceitual [6] causada pelas novas observações, como a variação de cor ou forma em comparação com os dados antigos. Portanto, duas questões precisam ser abordadas na nova configuração IIL: 1) o notório esquecimento catastrófico devido à falta de acesso aos dados antigos, e 2) ampliar a fronteira de decisão existente para novas observações.
\ Para abordar as questões acima na nova configuração IIL, propomos uma nova estrutura IIL baseada na estrutura professor-aluno. A estrutura proposta consiste em um processo de destilação consciente da fronteira de decisão (DBD) e um processo de consolidação de conhecimento (KC). O DBD permite que o modelo aluno aprenda com novas observações com consciência das fronteiras de decisão interclasses existentes, o que permite ao modelo determinar onde fortalecer seu conhecimento e onde retê-lo. No entanto, a fronteira de decisão é intratável quando há amostras insuficientes localizadas ao redor da fronteira devido à falta de acesso aos dados antigos em IIL. Para superar isso, nos inspiramos na prática de polvilhar o chão com farinha para revelar pegadas ocultas. Da mesma forma, introduzimos ruído gaussiano aleatório para poluir o espaço de entrada e manifestar a fronteira de decisão aprendida para destilação. Durante o treinamento do modelo aluno com destilação de fronteira, o conhecimento atualizado é ainda mais consolidado de volta ao modelo professor intermitentemente e repetidamente com o mecanismo EMA [28]. Utilizar o modelo professor como modelo alvo é uma tentativa pioneira e sua viabilidade é explicada teoricamente.
\ De acordo com a nova configuração IIL, reorganizamos o conjunto de treinamento de alguns conjuntos de dados existentes comumente usados em CIL, como Cifar-100 [11] e ImageNet [24] para estabelecer os benchmarks. O modelo é avaliado nos dados de teste, bem como nos dados base não disponíveis em cada fase incremental. Nossas principais contribuições podem ser resumidas da seguinte forma: 1) Definimos uma nova configuração IIL para buscar promoção rápida e econômica do modelo em novas observações e estabelecer os benchmarks; 2) Propomos um novo método de destilação consciente da fronteira de decisão para reter o conhecimento aprendido e enriquecê-lo com novos dados; 3) Consolidamos criativamente o conhecimento aprendido do aluno para o modelo professor para atingir melhor desempenho e generalização, e provamos a viabilidade teoricamente; e 4) Experimentos extensivos demonstram que o método proposto acumula bem o conhecimento apenas com novos dados, enquanto a maioria dos métodos de aprendizagem incremental existentes falhou.
\
:::info Este artigo está disponível no arxiv sob a licença CC BY-NC-ND 4.0 Deed (Atribuição-NãoComercial-SemDerivações 4.0 Internacional).
:::
:::info Autores:
(1) Qiang Nie, Universidade de Ciência e Tecnologia de Hong Kong (Guangzhou);
(2) Weifu Fu, Tencent Youtu Lab;
(3) Yuhuan Lin, Tencent Youtu Lab;
(4) Jialin Li, Tencent Youtu Lab;
(5) Yifeng Zhou, Tencent Youtu Lab;
(6) Yong Liu, Tencent Youtu Lab;
(7) Qiang Nie, Universidade de Ciência e Tecnologia de Hong Kong (Guangzhou);
(8) Chengjie Wang, Tencent Youtu Lab.
:::
\


Você também pode gostar

Nhà đầu tư tập trung vào SIREN và ARIA

Ngân hàng Nhân dân Trung Quốc bổ sung 12 đơn vị kinh doanh RMB số




