

Nova Configuração IIL: Melhorando Modelos Implementados Apenas com Novos Dados
Tabela de Links
Resumo e 1 Introdução
-
Trabalhos relacionados
-
Definição do problema
-
Metodologia
4.1. Destilação consciente da fronteira de decisão
4.2. Consolidação de conhecimento
-
Resultados experimentais e 5.1. Configuração do Experimento
5.2. Comparação com métodos SOTA
5.3. Estudo de ablação
-
Conclusão e trabalho futuro e Referências
\
Material Suplementar
- Detalhes da análise teórica sobre o mecanismo KCEMA em IIL
- Visão geral do algoritmo
- Detalhes do conjunto de dados
- Detalhes de implementação
- Visualização de imagens de entrada com poeira
- Mais resultados experimentais
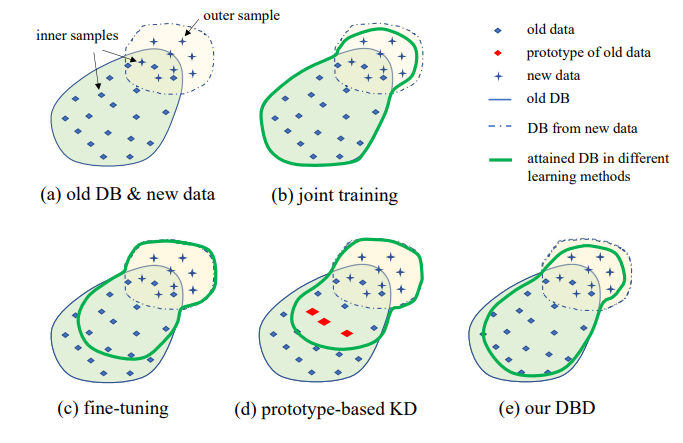
3. Definição do problema
A ilustração da configuração IIL proposta é mostrada na Fig. 1. Como pode ser visto, os dados são gerados continuamente e de forma imprevisível no fluxo de dados. Geralmente em aplicações reais, as pessoas tendem a coletar dados suficientes primeiro e treinar um modelo forte M0 para implantação. Não importa quão forte seja o modelo, ele inevitavelmente encontrará dados fora da distribuição e falhará neles. Estes casos de falha e outras novas observações de baixa pontuação serão anotados para treinar o modelo de tempos em tempos. Retreinar o modelo com todos os dados acumulados a cada vez leva a custos cada vez mais altos em tempo e recursos. Portanto, o novo IIL visa melhorar o modelo existente apenas com os novos dados a cada vez.
\ 
\ 
\
:::info Autores:
(1) Qiang Nie, Universidade de Ciência e Tecnologia de Hong Kong (Guangzhou);
(2) Weifu Fu, Tencent Youtu Lab;
(3) Yuhuan Lin, Tencent Youtu Lab;
(4) Jialin Li, Tencent Youtu Lab;
(5) Yifeng Zhou, Tencent Youtu Lab;
(6) Yong Liu, Tencent Youtu Lab;
(7) Qiang Nie, Universidade de Ciência e Tecnologia de Hong Kong (Guangzhou);
(8) Chengjie Wang, Tencent Youtu Lab.
:::
:::info Este artigo está disponível no arxiv sob a licença CC BY-NC-ND 4.0 Deed (Atribuição-NãoComercial-SemDerivações 4.0 Internacional).
:::
\


Você também pode gostar
![[LENTE | ATUALIZAÇÃO] As sessões de Educação Eleitoral para as Eleições BARMM de 2026 continuam em Tawi-Tawi!](https://lente.rappler.com/tachyon/sites/12/2026/04/LENTE-1-scaled.png?resize=150%2C150&crop_strategy=attention)
[LENTE | ATUALIZAÇÃO] As sessões de Educação Eleitoral para as Eleições BARMM de 2026 continuam em Tawi-Tawi!

Trump não está a mentir — está a fazer algo pior: académico




