

5 Maneiras Surpreendentes Como a IA Atual Falha em Realmente "Pensar"

Os modelos de linguagem de grande escala (LLMs) explodiram em capacidade, mostrando um desempenho notável em tarefas desde a compreensão de linguagem natural até à geração de código. Interagimos com eles diariamente, e a sua fluência pode ser surpreendente, colocando-nos claramente num vale estranho de inteligência artificial. Mas será que este desempenho sofisticado equivale a um pensamento genuíno, ou é apenas uma ilusão de alta tecnologia?
\ Um crescente corpo de pesquisa sugere que por trás da cortina de competência encontra-se um conjunto de limitações profundas e contraintuitivas. Este artigo explora cinco das falhas mais significativas que expõem o abismo entre o desempenho da IA e a verdadeira compreensão semelhante à humana.
Eles não raciocinam mais intensamente; simplesmente colapsam
Um artigo recente da Apple Research, intitulado "A Ilusão do Pensamento", revela uma falha crítica mesmo nos mais avançados "Modelos de Raciocínio de Grande Escala" (LRMs) que utilizam técnicas como Chain-of-Thought. A pesquisa mostra que estes modelos não estão verdadeiramente a raciocinar, mas são simuladores sofisticados que atingem um muro intransponível quando os problemas se tornam suficientemente complexos.
\ Os investigadores utilizaram o puzzle da Torre de Hanói para testar os modelos, identificando três regimes de desempenho distintos baseados na complexidade do puzzle:
\
- Baixa Complexidade (3 discos): Modelos padrão, sem raciocínio, tiveram um desempenho tão bom quanto, ou até melhor que, os modelos LRM "pensantes".
- Média Complexidade (6 discos): Os LRMs que geram uma cadeia de pensamento mais longa mostraram uma clara vantagem.
- Alta Complexidade (7+ discos): Ambos os tipos de modelo experimentaram um "colapso completo", com a sua precisão a cair para zero.
\
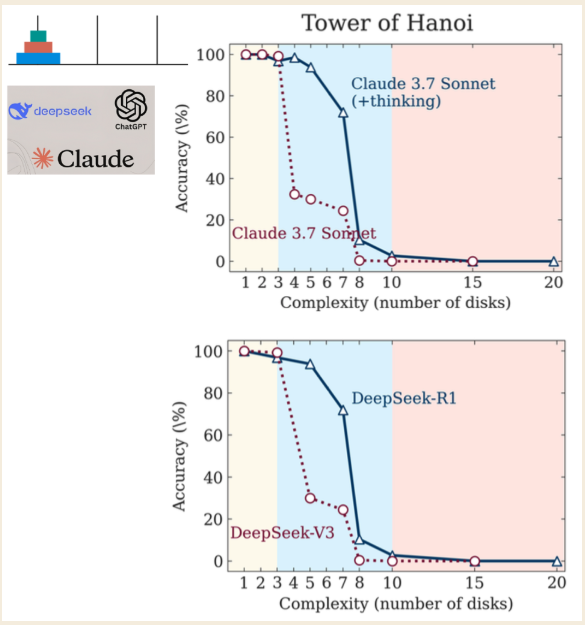
A descoberta mais contraintuitiva foi que os modelos "pensam" menos à medida que os problemas se tornam mais difíceis. Ainda mais condenável, eles falham em calcular corretamente mesmo quando lhes são explicitamente dados os algoritmos necessários para resolver o puzzle. Isto sugere uma incapacidade fundamental de aplicar regras sob pressão, uma imitação vazia de pensamento que se despedaça quando é mais importante. (Os investigadores observam que, embora a Anthropic, um laboratório de IA rival, tenha levantado objeções, estas permanecem pequenas críticas em vez de uma refutação fundamental das descobertas.)
\ Como os investigadores da Universidade do Arizona colocaram, este comportamento captura a essência da ilusão:
...sugerindo que os LLMs não são raciocinadores baseados em princípios, mas sim simuladores sofisticados de texto semelhante ao raciocínio.
A sua "Cadeia de Pensamento" é frequentemente uma miragem
Chain-of-Thought (CoT) é o processo pelo qual um LLM escreve o seu raciocínio passo a passo antes de entregar uma resposta final, uma característica projetada para melhorar a precisão e revelar a sua lógica interna. No entanto, um estudo recente analisando como os LLMs lidam com aritmética básica mostra que este processo é frequentemente uma "miragem frágil".
\ Surpreendentemente, existem vastas inconsistências entre os passos de raciocínio no CoT e a resposta final que o modelo fornece. Em tarefas envolvendo adição simples, foi feita uma descoberta chocante: em mais de 60% das amostras, o modelo produziu passos de raciocínio incorretos que, de alguma forma, misteriosamente, levaram à resposta final correta.
\ Isto é equivalente a um estudante mostrar um trabalho sem sentido num teste de matemática, mas milagrosamente escrever o número final correto. Não concluirias que ele entende o material; suspeitarias que copiou a resposta. Na IA, isto sugere que o "raciocínio" é frequentemente uma justificação post-hoc, não um processo de pensamento genuíno. Isto não é um bug que se resolve com escalabilidade; o problema piora com modelos mais avançados, com a taxa deste comportamento contraditório aumentando para 74% no GPT-4.
\ Se o "processo de pensamento" interno do modelo é uma miragem, o que acontece quando é forçado a resolver um problema real e complexo? Frequentemente, desce à loucura.
Ficam presos em ciclos de "Descida à Loucura"
Ao usar LLMs para tarefas complexas como depuração de código, um padrão perigoso pode emergir: uma "descida à loucura" ou um "ciclo de alucinação". Este é um ciclo de feedback onde um LLM, tentando corrigir um erro de programação, fica preso num ciclo irracional e interminável. Sugere uma correção aparentemente plausível que falha, e quando solicitado por outra solução, frequentemente reintroduz o erro original, prendendo o utilizador num ciclo infrutífero.
\ Um estudo que atribuiu a programadores a tarefa de depurar código revelou uma tendência bombástica para fluxos de trabalho assistidos por IA. Os resultados foram claros: os programadores não assistidos por IA resolveram mais tarefas corretamente e menos tarefas incorretamente do que o grupo que usou LLMs para ajuda.
\ Deixa isso afundar: numa tarefa complexa de depuração, ter um assistente de IA de última geração não era apenas inútil—era ativamente prejudicial, levando a resultados piores do que não ter IA alguma. Participantes usando IA frequentemente ficavam presos nestes ciclos infrutíferos, desperdiçando tempo em correções conceitualmente infundadas. Os investigadores também identificaram o problema da "solução ruidosa", onde uma correção correta está enterrada dentro de uma enxurrada de sugestões irrelevantes, uma receita perfeita para a frustração humana. Esta "assistência" defeituosa destaca como o verniz impressionante da IA pode esconder um núcleo profundamente não confiável, especialmente quando os riscos são altos.
Os seus benchmarks impressionantes são construídos sobre uma base de falhas
Quando empresas de IA lançam novos modelos, apontam para pontuações impressionantes em benchmarks para provar a sua superioridade. Um olhar mais atento, no entanto, pode revelar uma imagem muito menos lisonjeira.
\ O SWE-bench (Software Engineering Benchmark), usado para medir a capacidade de um LLM de corrigir problemas de software do mundo real do GitHub, é um estudo de caso primordial. Um estudo independente da Universidade de York encontrou falhas críticas que inflacionaram selvagemente as capacidades percebidas dos modelos:
\
- Vazamento de Solução ("Trapaça"): Em 32,67% dos patches bem-sucedidos, a solução correta já estava fornecida no próprio relatório do problema.
- Testes Fracos: Em 31,08% dos casos onde o modelo "passou", os testes de verificação eram demasiado fracos para realmente confirmar que a correção estava correta.
\ Quando estas instâncias falhas foram filtradas, o desempenho no mundo real de um modelo de topo (SWE-Agent + GPT-4) despencou. A sua taxa de resolução caiu de um anunciado 12,47% para apenas 3,97%. Além disso, mais de 94% dos problemas no benchmark foram criados antes das datas de corte de conhecimento dos LLMs, levantando sérias questões sobre vazamento de dados.
\ Isto revela uma realidade preocupante: benchmarks são frequentemente ferramentas de marketing que apresentam um cenário de melhor caso, criado em laboratório, que desmorona sob escrutínio do mundo real. A lacuna entre o poder anunciado e o desempenho verificado não é uma fenda; é um cânion.
Eles dominam regras mas fundamentalmente carecem de compreensão
Mesmo que todas as falhas técnicas acima fossem corrigidas, permanece uma barreira mais profunda e filosófica. Os LLMs carecem dos componentes centrais da inteligência humana. Enquanto filósofos discutem consciência e intencionalidade, muitos argumentos sugerem que a racionalidade, ou seja, a nossa capacidade de compreender conceitos universais e raciocinar logicamente, é o aspecto-chave único aos humanos e ausente na IA.
\ Esta ideia é reforçada pelo físico Roger Penrose, que usa o teorema da incompletude de Gödel para argumentar que a compreensão matemática humana transcende qualquer conjunto fixo de regras algorítmicas. Pense em qualquer algoritmo como um livro de regras finito. O teorema de Gödel mostra que um matemático humano pode sempre olhar para o livro de regras de fora e entender verdades que o próprio livro de regras não pode provar.
\ As nossas mentes não estão apenas a seguir as regras no livro; podemos ler o livro inteiro e compreender as suas limitações. Esta capacidade de insight, esta compreensão "não computável", é o que separa a cognição humana mesmo da IA mais avançada.
\ Os LLMs são mestres em manipular símbolos baseados em algoritmos e padrões estatísticos. Eles não possuem, no entanto, a consciência necessária para uma compreensão genuína. Como um argumento poderoso conclui:
O truque do mágico
Embora os LLMs sejam inegavelmente ferramentas poderosas que podem simular comportamento inteligente com precisão inquietante, as evidências crescentes mostram que são mais como simuladores sofisticados do que pensadores genuínos. O seu desempenho é uma grande ilusão, um espetáculo deslumbrante de competência que se desfaz sob pressão, contradiz a sua própria lógica e depende de métricas falhas. É semelhante a um truque de mágica (aparentemente impossível), mas em última análise uma ilusão construída sobre técnicas inteligentes, não magia real. À medida que continuamos a integrar estes sistemas no nosso mundo, devemos permanecer críticos e fazer a pergunta essencial:
\ Se estas máquinas de IA falham em problemas mais difíceis, mesmo quando lhes dás os algoritmos e regras, estão realmente a pensar ou apenas a fingir muito bem?
Podcast:
\
- Apple: AQUI
- Spotify: AQUI
\


Você também pode gostar

Negociações intensificam-se enquanto equipas dos EUA e do Irão entram em conflito sobre importante 'ponto de bloqueio'

OKX Wallet Adiciona Acesso Nativo ao Aave na X Layer à Medida que o Protocolo se Aproxima de 30% do TVL DeFi




