

Torne os seus pipelines de dados 5 vezes mais rápidos com o processamento em lote adaptativo
Tem muitas chamadas LLM no seu fluxo de transformação de dados?
CocoIndex pode ajudar. É alimentado por um motor Rust ultra-performante e agora suporta processamento em lote adaptativo de fábrica. Isto melhorou o Throughput em ~5× (≈80% de tempo de execução mais rápido) para fluxos de trabalho nativos de IA. E o melhor de tudo, não precisa de alterar nenhum código porque o processamento em lote acontece automaticamente, adaptando-se ao seu tráfego e mantendo as GPUs totalmente utilizadas.
Aqui está o que aprendemos enquanto construíamos suporte de processamento em lote adaptativo no Cocoindex.
Mas primeiro, vamos responder a algumas perguntas que podem estar na sua mente.
Por que o processamento em lote acelera o processamento?
-
Sobrecarga fixa por chamada: Isto consiste em todo o trabalho preparatório e administrativo necessário antes que o cálculo real possa começar. Os exemplos incluem configuração de lançamento do kernel da GPU, transições de Python para C/C++, agendamento de tarefas, alocação e gestão de memória, e contabilidade realizada pelo framework. Estas tarefas de sobrecarga são largamente independentes do tamanho de entrada, mas devem ser pagas na totalidade para cada chamada.
\
-
Trabalho dependente de dados: Esta parte do cálculo escala diretamente com o tamanho e complexidade da entrada. Inclui operações de ponto flutuante (FLOPs) realizadas pelo modelo, movimento de dados através de hierarquias de memória, processamento de tokens e outras operações específicas de entrada. Ao contrário da sobrecarga fixa, este custo aumenta proporcionalmente com o volume de dados a serem processados.
Quando os itens são processados individualmente, a sobrecarga fixa é incorrida repetidamente para cada item, o que pode rapidamente dominar o tempo total de execução, especialmente quando o cálculo por item é relativamente pequeno. Em contraste, processar vários itens juntos em lotes reduz significativamente o impacto por item desta sobrecarga. O processamento em lote permite que os custos fixos sejam amortizados em muitos itens, enquanto também permite otimizações de hardware e software que melhoram a eficiência do trabalho dependente de dados. Estas otimizações incluem utilização mais eficaz dos pipelines da GPU, melhor utilização da cache e menos lançamentos de kernel, todos contribuindo para maior throughput e menor latência geral.
\
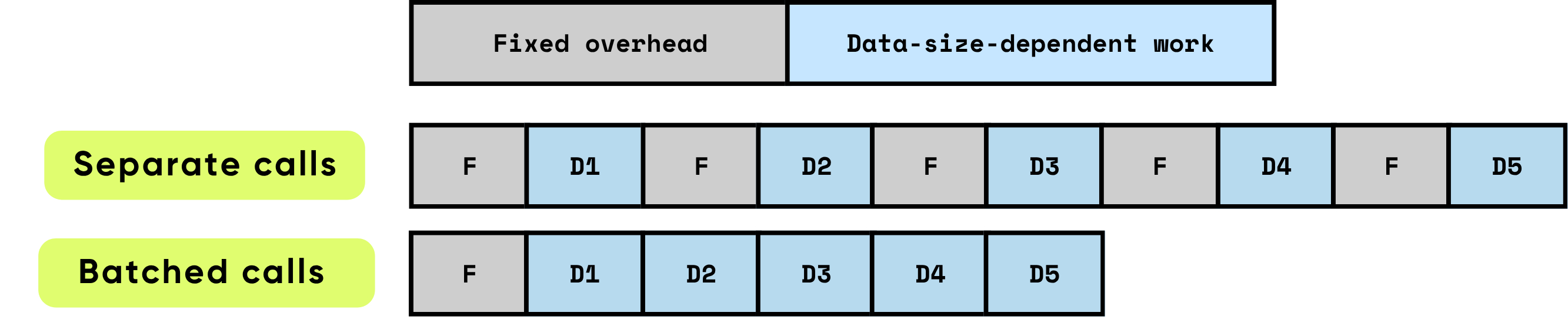
\ O processamento em lote melhora significativamente o desempenho otimizando tanto a eficiência computacional quanto a utilização de recursos. Fornece múltiplos benefícios compostos:
\
-
Amortizando sobrecarga única: Cada função ou chamada de API carrega uma sobrecarga fixa — lançamentos de kernel da GPU, transições de Python para C/C++, agendamento de tarefas, gestão de memória e contabilidade do framework. Ao processar itens em lotes, esta sobrecarga é distribuída por muitas entradas, reduzindo drasticamente o custo por item e eliminando trabalho de configuração repetido.
\
-
Maximizando a eficiência da GPU: Lotes maiores permitem que a GPU execute operações como multiplicações de matriz densas e altamente paralelas, comumente implementadas como Multiplicação de Matriz-Matriz Geral (GEMM). Este mapeamento garante que o hardware funcione com maior utilização, aproveitando totalmente as unidades de computação paralela, minimizando ciclos ociosos e alcançando throughput máximo. Operações pequenas e não processadas em lote deixam grande parte da GPU subutilizada, desperdiçando capacidade computacional cara.
\
-
Reduzindo a sobrecarga de transferência de dados: O processamento em lote minimiza a frequência de transferências de memória entre CPU (host) e GPU (dispositivo). Menos operações Host-to-Device (H2D) e Device-to-Host (D2H) significam menos tempo gasto movendo dados e mais tempo dedicado ao cálculo real. Isto é crítico para sistemas de alto throughput, onde a largura de banda de memória muitas vezes se torna o fator limitante em vez da potência de computação bruta.
Em combinação, estes efeitos levam a melhorias de throughput de ordens de magnitude. O processamento em lote transforma muitos cálculos pequenos e ineficientes em operações grandes e altamente otimizadas que exploram totalmente as capacidades de hardware moderno. Para cargas de trabalho de IA — incluindo grandes modelos de linguagem, visão computacional e processamento de dados em tempo real — o processamento em lote não é apenas uma otimização; é essencial para alcançar desempenho escalável de nível de produção.
\
Como é o processamento em lote para código Python normal
Código sem processamento em lote – simples mas menos eficiente
A forma mais natural de organizar um pipeline é processar dados peça por peça. Por exemplo, um loop de duas camadas como este:
for file in os.listdir(directory): content = file.read() chunks = split_into_chunks(content) for chunk in chunks: vector = model.encode([chunk.text]) # one item at a time index.upsert(file_id=file.name, chunk_offset=chunk.offset, vector=vector)
Isto é fácil de ler e raciocinar: cada fragmento flui diretamente através de múltiplos passos.
Processamento em lote manual – mais eficiente mas complicado
Pode acelerá-lo com processamento em lote, mas mesmo a versão mais simples "apenas processar tudo de uma vez" torna o código significativamente mais complicado:
\
# 1) Collect payloads and remember where each came from batch_texts = [] metadata = [] # (file_id, chunk_id) for file in os.listdir(directory): content = file.read() chunks = split_into_chunks(content) for chunk in chunks: batch_texts.append(chunk.text) metadata.append((file.name, chunk.offset)) # 2) One batched call (library will still mini-batch internally) vectors = model.encode(batch_texts) # 3) Zip results back to their sources for (file_name, chunk_offset), vector in zip(metadata, vectors): index.upsert(file_id=file.name, chunk_offset=chunk.offset, vector=vector)
Além disso, processar tudo de uma vez geralmente não é ideal porque os próximos passos só podem começar depois que esta etapa estiver concluída para todos os dados.
Suporte de Processamento em Lote do CocoIndex
O CocoIndex preenche a lacuna e permite-lhe obter o melhor dos dois mundos – manter a simplicidade do seu código seguindo o fluxo natural, enquanto obtém a eficiência do processamento em lote fornecido pelo runtime do CocoIndex.
Já habilitámos o suporte de processamento em lote para as seguintes funções incorporadas:
- EmbedText
- SentenceTransformerEmbed
- ColPaliEmbedImage
- ColPaliEmbedQuery
Não altera a API. O seu código existente funcionará sem qualquer alteração – ainda seguindo o fluxo natural, enquanto desfruta da eficiência do processamento em lote.
Para funções personalizadas, habilitar o processamento em lote é tão simples como:
- Definir
batching=Trueno decorador de função personalizada. - Alterar os argumentos e tipo de retorno para
list.
Por exemplo, se quiser criar uma função personalizada que chama uma API para construir miniaturas para imagens.
@cocoindex.op.function(batching=True) def make_image_thumbnail(self, args: list[bytes]) -> list[bytes]: ...
:::tip Veja a documentação de processamento em lote para mais detalhes.
:::
Como o CocoIndex Processa em Lote
Abordagens comuns
O processamento em lote funciona coletando solicitações recebidas numa fila e decidindo o momento certo para liberá-las como um único lote. Esse timing é crucial — acerte-o, e você equilibra throughput, latência e uso de recursos de uma só vez.
Duas políticas de processamento em lote amplamente utilizadas dominam o cenário:
- Processamento em lote baseado em tempo (liberar a cada W milissegundos): Nesta abordagem, o sistema libera todas as solicitações que chegaram dentro de uma janela fixa de W milissegundos.
-
Vantagens: O tempo máximo de espera para qualquer solicitação é previsível, e a implementação é direta. Garante que mesmo durante tráfego baixo, as solicitações não permanecerão na fila indefinidamente.
-
Desvantagens: Durante períodos de tráfego esparso, solicitações ociosas acumulam-se lentamente, adicionando latência para chegadas antecipadas. Além disso, a janela ótima W muitas vezes varia com características de carga de trabalho, exigindo ajuste cuidadoso para encontrar o equilíbrio certo entre latência e throughput.
\
- Processamento em lote baseado em tamanho (liberar quando K itens estão na fila): Aqui, um lote é acionado uma vez que a fila atinge um número pré-definido de itens, K.
- Vantagens: O tamanho do lote é previsível, o que simplifica a gestão de memória e o design do sistema. É fácil raciocinar sobre os recursos que cada lote consumirá.
- Desvantagens: Quando o tráfego é leve, as solicitações podem permanecer na fila por um período prolongado, aumentando a latência para os itens que chegaram primeiro. Como o processamento em lote baseado em tempo, o K ótimo depende de padrões de carga de trabalho, exigindo ajuste empírico.
Muitos sistemas de alto desempenho adotam uma abordagem híbrida: eles liberam um lote quando a janela de tempo W expira ou a fila atinge o tamanho K — o que ocorrer primeiro. Esta estratégia captura os benefícios de ambos os métodos, melhorando a capacidade de resposta durante tráfego esparso enquanto mantém tamanhos de lote eficientes durante carga de pico.
Apesar disso, o processamento em lote sempre envolve parâmetros ajustáveis e compensações. Padrões de tráfego, características de carga de trabalho e restrições do sistema influenciam as configurações ideais. Alcançar desempenho ótimo muitas vezes requer monitoramento, perfilamento e ajuste dinâmico desses parâmetros para alinhar com condições em tempo real.
Abordagem do CocoIndex
Nível de framework: adaptativo, sem ajustes
O CocoIndex implementa um mecanismo de processamento em lote simples e natural que se adapta automaticamente à carga de solicitações recebidas. O processo funciona da seguinte forma:
\
- Enfileiramento contínuo: Enquanto o lote atual está sendo processado no dispositivo (por exemplo, GPU), quaisquer novas solicitações recebidas não são processadas imediatamente. Em vez disso, elas são enfileiradas. Isso permite que o sistema acumule trabalho sem interromper o cálculo em andamento.
- Janela de lote automática: Quando o lote atual é concluído, o CocoIndex imediatamente pega todas as solicitações que se acumularam na fila e as trata como o próximo lote. Este conjunto de solicitações forma a nova janela de lote. O sistema então começa a processar este lote imediatamente.
- Processamento em lote adaptativo: Não há temporizadores, tamanhos de lote fixos e limiares pré-configurados. O tamanho de cada lote se adapta naturalmente ao tráfego que chegou durante o tempo de serviço do lote anterior. Períodos de alto tráfego produzem automaticamente lotes maiores, maximizando a utilização da GPU. Períodos de baixo tráfego produzem lotes menores, minimizando a latência para solicitações antecipadas.
Em essência, o mecanismo de processamento em lote do CocoIndex é auto-ajustável. Ele processa continuamente solicitações em lotes enquanto permite que o tamanho do lote reflita a demanda em


Você também pode gostar

Justin Sun Afirma que a World Liberty Financial, Apoiada por Trump, Construiu uma Porta dos Fundos Secreta para Roubar Tokens de Investidores

MPIF reserva P12M para Tubbataha




