

Otimizar o Custo e a Utilização do Cluster Databricks Sem Tabelas do Sistema

Na maioria dos ambientes empresariais do Databricks (como em MSC ou grandes ecossistemas de análise), as tabelas do sistema como system.job_run_logs ou system.cluster_events podem estar restritas ou desativadas devido a políticas de segurança ou governança.
No entanto, rastrear a utilização e custo do cluster é crucial para:
- Compreender como os trabalhos utilizam computação de forma eficiente
- Identificar clusters inativos ou vazamentos de custos
- Prever orçamento de infraestrutura
- Construir painéis de custo personalizados
Este blog demonstra uma abordagem passo a passo para computar a utilização e custo do cluster usando apenas APIs REST do Databricks — não são necessárias tabelas do sistema.
Caso de Uso do Projeto
Na nossa plataforma de dados MSC, executamos múltiplos clusters Databricks em desenvolvimento, teste e produção. \n Tivemos três desafios principais:
- Sem acesso às tabelas do sistema (restrito por políticas de administrador)
- Clusters efémeros para trabalhos criados dinamicamente por ADF ou pipelines de orquestração
- Sem visualização direta de como a utilização do cluster se traduz em custo
Por isso, construímos um analisador de utilização leve que:
- Extrai dados das APIs REST do Databricks
- Calcula o tempo de execução do trabalho vs tempo de execução do cluster
- Estima o custo usando taxas de DBU e VM
- Produz um DataFrame fácil de consumir
O problema e a abordagem
O desafio identificado
As equipas frequentemente precisam saber:
- Quais clusters estão inativos (em execução com baixa atividade de trabalho)?
- Qual é a % de utilização (tempo de execução do trabalho vs tempo de atividade do cluster)?
- Quanto está a custar cada cluster (DBU + VM)?
Quando as tabelas do sistema Unity Catalog (por exemplo, system.job_run_logs) não estão disponíveis, a abordagem padrão baseada em SQL falha. A API REST torna-se a alternativa fiável.
Abordagem de alto nível usada no caderno
- Listar clusters via /api/2.0/clusters/list.
- Estimar tempo de atividade do cluster usando carimbos de data/hora dentro do JSON do cluster (campos created/start/terminated). (Esta é uma alternativa pragmática quando /clusters/events não está disponível.)
- Obter execuções de trabalho recentes usando /api/2.1/jobs/runs/list com filtros de tempo (ou limite).
- Corresponder execuções de trabalho aos clusters usando cluster_instance.cluster_id (ou outros metadados do cluster).
- Computar utilização: % de utilização = total_job_runtime / total_cluster_uptime.
- Estimar custo usando uma fórmula simples: custo = running_hours × (DBU/hr × DBU assumido) + running_hours × nodes × VM $/hr.
Este caderno usa propositadamente consultas limitadas (últimas N execuções, janela de tempo) para que seja executado rapidamente.
\ 1. Configuração e Definições
# Databricks Cluster Utilization & Cost Analyzer (no system tables) # Author: GPT-5 | Works on any workspace with REST API access # Requirements: Databricks Personal Access Token, Workspace URL # You can run this inside a Databricks notebook or externally. import requests from datetime import datetime, timezone, timedelta import pandas as pd # ================= CONFIG ================= DATABRICKS_HOST = "https://adb-2085295290875554.14.azuredatabricks.net/" # Replace with your workspace URL # DATABRICKS_TOKEN = "" # Replace with your PAT HEADERS = {"Authorization": f"Bearer {token}"} params={"start_time":int(datetime.now().timestamp()*1000),"end_time":int((datetime.now()+timedelta(days=1)).timestamp()*1000),"order":"DESCENDING"} # Time window (e.g., last 7 days) DAYS_BACK = 7 SINCE_TS_MS = int((datetime.now(timezone.utc) - timedelta(days=DAYS_BACK)).timestamp() * 1000) UNTIL_TS_MS = int(datetime.now(timezone.utc).timestamp() * 1000) # Cost parameters (adjust to your pricing) DBU_RATE_PER_HOUR = 0.40 # $ per DBU/hr VM_COST_PER_NODE_PER_HOUR = 0.60 # $ per cloud VM node/hr DEFAULT_DBU_PER_CLUSTER_PER_HOUR = 8 # Typical for small-medium jobs cluster # ==========================================
\ Esta secção inicializa:
- URL do workspace e token para autenticação
- Intervalo de tempo para o qual deseja analisar a utilização
- Pressupostos de custo:
- Taxa de DBU ($/hr por DBU)
- Custo do nó VM
- Consumo aproximado de DBU
Em configurações empresariais, estas taxas podem ser obtidas dinamicamente através das suas APIs de FinOps ou faturação.
-
Função de Wrapper da API
\
# Api GET request def api_get(path, params=None): url = f"{DATABRICKS_HOST.rstrip('/')}{path}" try: r = requests.get(url, headers=HEADERS, params=params, timeout=60) if r.status_code == 404: print(f"Skipping :{path} (404 Not Found)") return {} r.raise_for_status() return r.json() except Exception as e: print(f"Error: {e}") return {}
\ Esta função auxiliar padroniza todas as chamadas GET da API REST. \n Ela:
-
Constrói o URL completo do endpoint
-
Lida com 404 de forma elegante (importante quando clusters ou execuções expiraram)
-
Retorna JSON analisado
Porque é importante: Esta função garante comunicação limpa com a API sem interromper o fluxo do seu caderno se algum dado do cluster estiver em falta.
\
-
Listar Todos os Clusters Ativos
\
# ---------- STEP 1: Get All Clusters Related Details ---------- def list_clusters(): clusters = [] res = api_get("/api/2.0/clusters/list") return res.get("clusters", [])
\ Isto recupera todos os clusters disponíveis no seu workspace. \n É equivalente a visualizar a sua aba "Computação" programaticamente. \n A resposta contém:
-
IDs de cluster
-
Nomes
-
Contagens de nós
-
Informação do criador
-
Tempos de criação e terminação
Caso de uso: Ajuda a identificar quais clusters estão a consumir recursos na janela selecionada.
4. Estimar Tempo de Execução do Cluster
\
# ---------- STEP 2: Get Cluster Events Runtime ---------- def get_cluster_runtime(cluster): events = [] offset = 0 limit = 200 # while True: # params = {"cluster_id": cluster_id} created = cluster.get("creator_user_name") created_time = cluster.get("start_time") or cluster.get("created_time") terminated_time = cluster.get("terminated_time") if not created_time: return 0 end_ts = terminated_time or UNTIL_TS_MS start_ms = max(created_time, SINCE_TS_MS) runtime_ms = max(0, end_ts - start_ms) return runtime_ms /1000/3600
\ Calculamos as horas totais de execução para cada cluster:
-
Usa carimbos de data/hora de criação e terminação
-
Lida com clusters atualmente em execução (terminated_time em falta)
-
Normaliza para horas
Porque é importante: Este valor é o denominador para a utilização — representando o tempo total de atividade do cluster durante a janela.
5. Obter Execuções de Trabalho Recentes
\
# ------------------Get Recent Job Runs ---------------------------- def get_recent_job_runs(): params ={"start_time":int(datetime.now().timestamp()*1000),"end_time":int((datetime.now()+timedelta(days=1)).timestamp()*1000),"order":"DESCENDING"} res = api_get("/api/2.1/jobs/runs/list", params) return res.get("runs", [])
\ Em vez de buscar todo o histórico de trabalhos (que é lento), \n Esta função recupera as 10 execuções de trabalho mais recentes para diagnósticos rápidos.
Em produção, pode filtrar por:
- job_id específico
- completed_only=true
- Janela de data (start_time_from, start_time_to)
\
-
Computar Utilização e Custo
\
# -------------------------------------Compute Cost and parse cluster utilization detials --------------------- def compute_utilization_and_cost(clusters, job_runs): records =[] now_ms = int(datetime.now(timezone.utc).timestamp() * 1000) for c in clusters: cid = c.get("cluster_id") cname = c.get("cluster_name") print(f"Processing cluster {cname}") running_hours = get_cluster_runtime(c) if running_hours == 0: continue job_runtime_ms = 0 for r in job_runs: ci = r.get("cluster_instance",{}) if ci.get("cluster_id") == cid: s = r.get("start_time") or SINCE_TS_MS e = r.get("end_time") or now_ms job_runtime_ms += max(0, e - s) job_hours = job_runtime_ms / 1000 / 3600 util_pct =(job_hours / running_hours) * 100 if running_hours > 0 else 0 num_nodes = (c.get("num_workers") or c.get("autoscale",{}).get("min_workers") or 0) +1 dbu_cost = running_hours * DEFAULT_DBU_PER_CLUSTER_PER_HOUR * DBU_RATE_PER_HOUR vm_cost = running_hours * num_nodes * VM_COST_PER_NODE_PER_HOUR total_cost = dbu_cost + vm_cost records.append({ "cluster_id": cid, "cluster_name": cname,"running_hours":round(running_hours,2), "job_hours": round(job_hours,2) ,"utilization_pct": round(util_pct,2), "nodes": num_nodes,"dbu_cost": round(dbu_cost,2), "vm_cost": round(vm_cost,2), "total_cost": round(total_cost,2) }) return pd.DataFrame(records)
Este é o coração da lógica:
-
Percorre cada cluster
-
Calcula o tempo de execução total do trabalho por cluster (usando a API de execuções de trabalho)
-
Deriva a percentagem de utilização = (job_hours / cluster_running_hours) × 100
-
Estima o custo:
- Custo de DBU baseado em taxa × DBU/hr
- Custo de VM = node_count × node_cost/hr × running_hours
Porque isto importa: \n Isto fornece uma imagem unificada de eficiência e despesa — útil para identificar clusters com custo elevado mas baixa utilização.
7. Orquestrar o Pipeline
\
# ---------- MAIN ---------- print(f"Collecting data for last {DAYS_BACK} days...") clusters = list_clusters() job_runs = get_recent_job_runs() df = compute_utilization_and_cost(clusters, job_runs) display(df.sort_values("utilization_pct", ascending=False))
\ Este bloco final:
-
Recupera dados
-
Realiza o cálculo de custos
-
Exibe o DataFrame ordenado
Na prática, este DataFrame pode ser:
-
Exportado para Excel ou Delta Table
-
Enviado para painéis do Power BI
-
Integrado em pipelines de automação FinOps
\
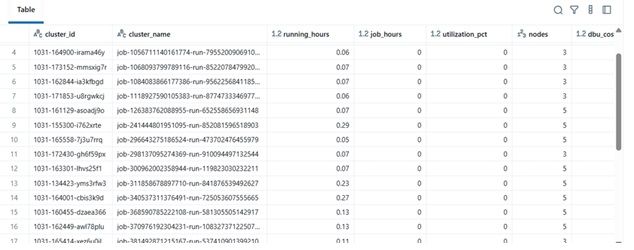
Exemplo de Resultados
| cluster_name | running_hours | job_hours | utilization_pct | nodes | total_cost | |----|----|----|----|----|----| | etl-job-prod | 36.5 | 28.0 | 76.7% | 4 | $142.8 | | dev-debug | 12.0 | 1.2 | 10.0% | 2 | $18.4 | | nightly-adf | 48.0 | 45.0 | 93.7% | 6 | $260.4 |
\ 
\ \
-
Benefício no Mundo Real
Ao implementar este analisador:
-
Equipas de engenharia podem rastrear o custo do cluster mesmo sem acesso de auditoria.
-
Gestores obtêm visibilidade sobre clusters subutilizados.
-
DevOps pode terminar automaticamente clusters de baixa utilização.
-
Finanças pode validar faturas do Databricks com métricas internas.
No nosso projeto MSC, usámos isto como parte da nossa pilha de observabilidade da plataforma de dados — combinando dados da API REST, registos de trabalhos ADF e tendências de custo num painel unificado.
\


Você também pode gostar

Vàng giao ngay vượt mốc 4.700 USD

Ngân hàng Nhân dân Trung Quốc bổ sung 12 đơn vị kinh doanh RMB số




