

Как смесь адаптаций делает точную настройку языковой модели дешевле и умнее
Таблица ссылок
Резюме и 1. Введение
-
Предпосылки
2.1 Смесь экспертов
2.2 Адаптеры
-
Смесь адаптаций
3.1 Политика маршрутизации
3.2 Регуляризация согласованности
3.3 Объединение модулей адаптации и 3.4 Совместное использование модулей адаптации
3.5 Связь с байесовскими нейронными сетями и ансамблированием моделей
-
Эксперименты
4.1 Экспериментальная установка
4.2 Ключевые результаты
4.3 Исследование методом абляции
-
Связанные работы
-
Выводы
-
Ограничения
-
Благодарности и ссылки
Приложение
A. Наборы данных NLU с малым количеством примеров B. Исследование методом абляции C. Подробные результаты по задачам NLU D. Гиперпараметры
3 Смесь адаптаций

\
3.1 Политика маршрутизации
Недавние работы, такие как THOR (Zuo et al., 2021), продемонстрировали, что стохастическая политика маршрутизации, например случайная маршрутизация, работает так же хорошо, как и классический механизм маршрутизации, такой как Switch routing (Fedus et al., 2021), со следующими преимуществами. Поскольку входные примеры случайным образом направляются к разным экспертам, нет необходимости в дополнительной балансировке нагрузки, так как каждый эксперт имеет равные возможности активации, что упрощает структуру. Кроме того, на уровне Switch нет дополнительных параметров и, следовательно, дополнительных вычислений для выбора эксперта. Последнее особенно важно в нашем случае для эффективной тонкой настройки параметров, чтобы сохранить параметры и FLOPs такими же, как у одного модуля адаптации. Для анализа работы AdaMix мы демонстрируем связи стохастической маршрутизации и усреднения весов модели с байесовскими нейронными сетями и ансамблированием моделей в разделе 3.5.
\ \ 
\ \ Такая стохастическая маршрутизация позволяет модулям адаптации изучать различные преобразования во время обучения и получать множественные представления задачи. Однако это также создает проблему выбора модулей для использования во время вывода из-за протокола случайной маршрутизации во время обучения. Мы решаем эту проблему с помощью следующих двух методов, которые дополнительно позволяют нам объединять модули адаптации и получать те же вычислительные затраты (FLOPs, количество настраиваемых параметров адаптации), что и у одного модуля.
3.2 Регуляризация согласованности
\ 
\ \ \ 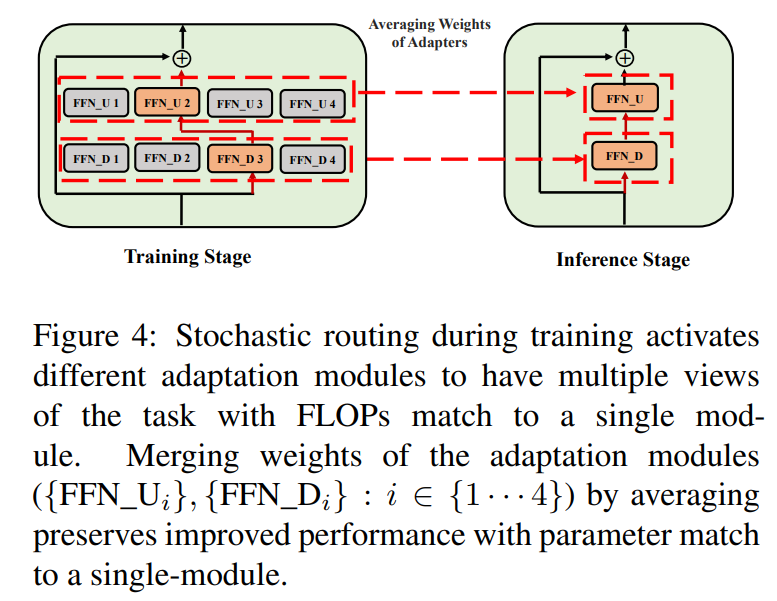
3.3 Объединение модулей адаптации
Хотя вышеуказанная регуляризация смягчает несогласованность при случайном выборе модуля во время вывода, она все еще приводит к увеличению затрат на обслуживание для размещения нескольких модулей адаптации. Предыдущие работы по тонкой настройке языковых моделей для последующих задач показали улучшение производительности при усреднении весов различных моделей, настроенных с разными случайными начальными значениями, превосходя одну настроенную модель. Недавняя работа (Wortsman et al., 2022) также показала, что по-разному настроенные модели с одинаковой инициализацией находятся в одном бассейне ошибок, что мотивирует использование агрегации весов для надежного обобщения задачи. Мы адаптируем и расширяем предыдущие методы тонкой настройки языковых моделей для нашего эффективного обучения модулей адаптации с множественными представлениями
\ \ 
\
3.4 Совместное использование модулей адаптации
\ 
3.5 Связь с байесовскими нейронными сетями и ансамблированием моделей
\ 
\ \ Это требует усреднения по всем возможным весам модели, что на практике невыполнимо. Поэтому было разработано несколько методов аппроксимации, основанных на методах вариационного вывода и методах стохастической регуляризации с использованием дропаутов. В этой работе мы используем еще одну стохастическую регуляризацию в форме случайной маршрутизации. Здесь цель состоит в том, чтобы найти суррогатное распределение qθ(w) в удобном семействе распределений, которое может заменить истинное апостериорное распределение модели, которое трудно вычислить. Идеальный суррогат определяется путем минимизации расхождения Кульбака-Лейблера (KL) между кандидатом и истинным апостериорным распределением.
\ \ 
\ \ \ 
\ \ \ 
\ \ \ \
:::info Авторы:
(1) Yaqing Wang, Университет Пердью (wang5075@purdue.edu);
(2) Sahaj Agarwal, Microsoft (sahagar@microsoft.com);
(3) Subhabrata Mukherjee, Microsoft Research (submukhe@microsoft.com);
(4) Xiaodong Liu, Microsoft Research (xiaodl@microsoft.com);
(5) Jing Gao, Университет Пердью (jinggao@purdue.edu);
(6) Ahmed Hassan Awadallah, Microsoft Research (hassanam@microsoft.com);
(7) Jianfeng Gao, Microsoft Research (jfgao@microsoft.com).
:::
:::info Эта статья доступна на arxiv по лицензии CC BY 4.0 DEED.
:::
\


Вам также может быть интересно

Венесуэла выдала разрешение на добычу природного газа британской Shell

Торговля между США и ССАГПЗ замедляется в апреле из-за войны с Ираном

Капитан сборной Японии Ватару Эндо не попадёт на Чемпионат мира и завершает карьеру в национальной команде



