

Решение самого большого узкого места 3D-сегментации
:::info Авторы:
(1) Джордж Танг, Массачусетский технологический институт;
(2) Кришна Мурти Джатаваллабхула, Массачусетский технологический институт;
(3) Антонио Торральба, Массачусетский технологический институт.
:::
Содержание
Аннотация и I. Введение
II. Предпосылки
III. Метод
IV. Эксперименты
V. Заключение и Ссылки
\ 
\ Аннотация— Мы решаем проблему изучения неявного представления сцены для 3D сегментации экземпляров из последовательности позированных RGB-изображений. Для этого мы представляем 3DIML, новую структуру, которая эффективно изучает поле меток, которое может быть визуализировано с новых точек обзора для создания согласованных между ракурсами масок сегментации экземпляров. 3DIML значительно улучшает время обучения и вывода существующих методов, основанных на неявном представлении сцены. В отличие от предыдущих работ, которые оптимизируют нейронное поле самоконтролируемым способом, требуя сложных процедур обучения и проектирования функций потерь, 3DIML использует двухфазный процесс. Первая фаза, InstanceMap, принимает на вход 2D маски сегментации последовательности изображений, созданные фронтенд-моделью сегментации экземпляров, и связывает соответствующие маски на изображениях с 3D метками. Эти почти согласованные между ракурсами псевдометки затем используются во второй фазе, InstanceLift, для контроля обучения нейронного поля меток, которое интерполирует области, пропущенные InstanceMap, и разрешает неоднозначности. Кроме того, мы представляем InstanceLoc, который обеспечивает локализацию экземпляров масок в режиме, близком к реальному времени, с использованием обученного поля меток и готовой модели сегментации изображений путем объединения выходных данных обоих. Мы оцениваем 3DIML на последовательностях из наборов данных Replica и ScanNet и демонстрируем эффективность 3DIML при умеренных предположениях для последовательностей изображений. Мы достигаем значительного практического ускорения по сравнению с существующими методами неявного представления сцены при сопоставимом качестве, демонстрируя его потенциал для обеспечения более быстрого и эффективного понимания 3D сцены.
I. ВВЕДЕНИЕ
Интеллектуальные агенты требуют понимания сцены на уровне объектов для эффективного выполнения контекстно-зависимых действий, таких как навигация и манипуляция. В то время как сегментация объектов из изображений достигла значительного прогресса с масштабируемыми моделями, обученными на наборах данных интернет-масштаба [1], [2], расширение таких возможностей на 3D-среду остается сложной задачей.
\ В этой работе мы решаем проблему изучения 3D-представления сцены из позированных 2D-изображений, которое факторизует базовую сцену на набор составляющих ее объектов. Существующие подходы к решению этой проблемы были сосредоточены на обучении агностических к классам 3D-моделей сегментации [3], [4], требующих большого количества аннотированных 3D-данных и работающих непосредственно с явными 3D-представлениями сцены (например, облаками точек). Альтернативный класс подходов [5], [6] вместо этого предложил напрямую переносить маски сегментации из готовых моделей сегментации экземпляров в неявные 3D-представления, такие как нейронные поля излучения (NeRF) [7], позволяя им визуализировать 3D-согласованные маски экземпляров с новых точек обзора.
\ Однако подходы, основанные на нейронных полях, остаются печально известными своей сложностью оптимизации, причем [5] и [6] требуют нескольких часов для оптимизации изображений с низким и средним разрешением (например, 300 × 640). В частности, Panoptic Lifting [5] масштабируется кубически с увеличением числа объектов в сцене, что препятствует его применению к сценам с сотнями объектов, в то время как Contrastively Lifting [6] требует сложной многоэтапной процедуры обучения, затрудняя практическое использование в робототехнических приложениях.
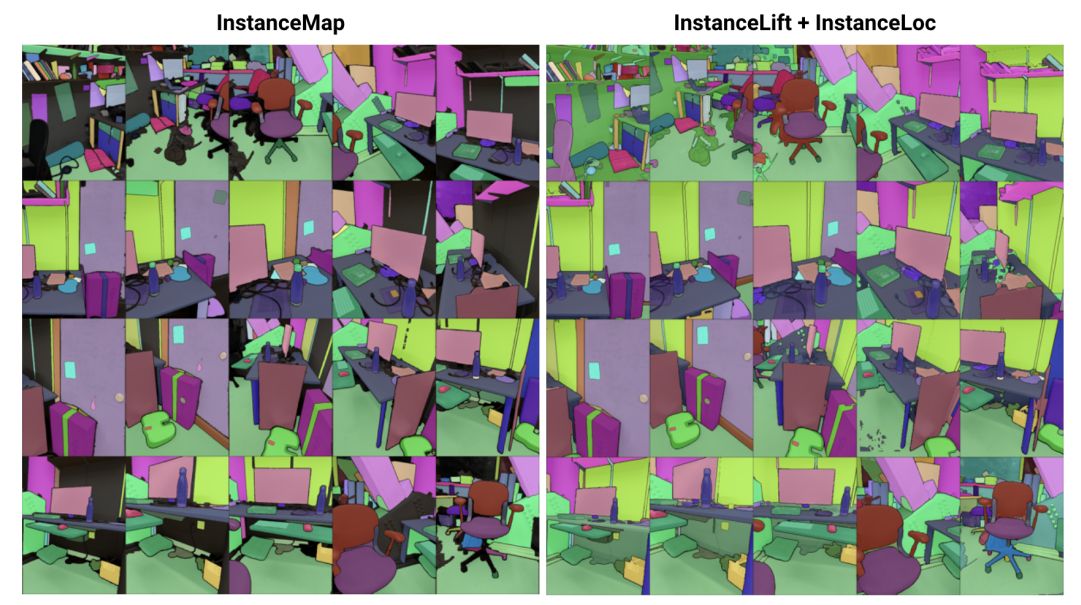
\ С этой целью мы предлагаем 3DIML, эффективную технику для изучения 3D-согласованной сегментации экземпляров из позированных RGB-изображений. 3DIML состоит из двух фаз: InstanceMap и InstanceLift. Учитывая несогласованные между ракурсами 2D-маски экземпляров, извлеченные из RGB-последовательности с использованием фронтенд-модели сегментации экземпляров [2], InstanceMap создает последовательность согласованных между ракурсами масок экземпляров. Для этого мы сначала связываем маски между кадрами, используя совпадения ключевых точек между похожими парами изображений. Затем мы используем эти потенциально шумные ассоциации для контроля нейронного поля меток, InstanceLift, которое использует 3D-структуру для интерполяции отсутствующих меток и разрешения неоднозначностей. В отличие от предыдущих работ, которые требуют многоэтапного обучения и дополнительной разработки функций потерь, мы используем единую функцию потерь рендеринга для контроля меток экземпляров, что позволяет процессу обучения сходиться значительно быстрее. Общее время выполнения 3DIML, включая InstanceMap, составляет 10-20 минут, в отличие от 3-6 часов для предыдущих методов.
\ Кроме того, мы разрабатываем InstaLoc, быстрый конвейер локализации, который принимает новый ракурс и локализует все экземпляры, сегментированные на этом изображении (используя быструю модель сегментации экземпляров [8]), путем разреженных запросов к полю меток и объединения прогнозов меток с извлеченными областями изображения. Наконец, 3DIML чрезвычайно модульный, и мы можем легко заменять компоненты нашего метода на более производительные по мере их появления.
\ Подводя итог, наши вклады:
\ • Эффективный подход к обучению нейронного поля, который факторизует 3D-сцену на составляющие ее объекты
\ • Быстрый алгоритм локализации экземпляров, который объединяет разреженные запросы к обученному полю меток с производительными моделями сегментации экземпляров изображений для создания 3D-согласованных масок сегментации экземпляров
\ • Общее практическое улучшение времени выполнения в 14-24 раза по сравнению с предыдущими методами, протестированное на одном GPU (NVIDIA RTX 3090)
II. ПРЕДПОСЫЛКИ
2D сегментация: Распространение архитектуры vision transformer и увеличение масштаба наборов данных изображений привели к созданию серии современных моделей сегментации изображений. Panoptic и Contrastive Lifting оба переносят панорамные маски сегментации, созданные Mask2Former [1], в 3D, изучая нейронное поле. В направлении сегментации с открытым набором, segment anything (SAM) [2] достигает беспрецедентной производительности, обучаясь на миллиарде масок на 11 миллионах изображений. HQ-SAM [9] улучшает SAM для детализированных масок. FastSAM [8] дистиллирует SAM в архитектуру CNN и достигает аналогичной производительности, будучи на порядки быстрее. В этой работе мы используем GroundedSAM [10], [11], который улучшает SAM для создания масок сегментации на уровне объектов, а не на уровне частей.
\ Нейронные поля для 3D сегментации экземпляров: NeRF - это неявные представления сцены, которые могут точно кодировать сложную геометрию, семантику и другие модальности, а также разрешать несогласованный между ракурсами контроль [12]. Panoptic lifting [5] строит семантические ветви и ветви экземпляров на эффективном варианте NeRF, TensoRF [13], используя функцию потерь венгерского сопоставления для назначения изученных масок экземпляров суррогатным идентификаторам объектов, учитывая эталонные несогласованные между ракурсами маски. Это плохо масштабируется с увеличением числа объектов (из-за кубической сложности венгерского сопоставления). Contrastive lifting [6] решает эту проблему, вместо этого применяя контрастное обучение на признаках сцены, с положительными и отрицательными отношениями, определяемыми тем, проецируются ли они на одну и ту же маску. Кроме того, contrastive lifting требует медленно-быстрой функции потерь, основанной на кластеризации, для стабильного обучения, что приводит к более быстрой производительности, чем panoptic lifting, но требует нескольких этапов обучения, что приводит к медленной сходимости. Одновременно с нами, Instance-NeRF [14] напрямую изучает поле меток, но они основывали свою ассоциацию масок на использовании NeRF-RPN [15] для обнаружения объектов в NeRF. Наш подход, напротив, позволяет масштабироваться до очень высоких разрешений изображений, требуя лишь небольшого числа (40-60) запросов к нейронному полю для визуализации масок сегментации.
\ Структура из движения: Во время ассоциации масок в InstanceMap мы вдохновляемся масштабируемыми конвейерами 3D-реконструкции, такими как hLoc [16], включая использование визуальных дескрипторов для сопоставления точек обзора изображений сначала, а затем применение сопоставления ключевых точек в качестве предварительного этапа для ассоциации масок. Мы используем LoFTR [17] для извлечения и сопоставления ключевых точек.
\
:::info Эта статья доступна на arxiv под лицензией CC by 4.0 Deed (Attribution 4.0 International).
:::
\


Вам также может быть интересно

Отток из Bitcoin ETF достиг рекордных $6,35 млрд, но паническая распродажа может замедляться

Флагманский мыльный сериал BBC используется для продвижения про-мигрантской пропаганды активистами-инфильтраторами

Пенсионный фонд Японии планирует выделить средства в криптовалюту на фоне опасений относительно фиатных валют



