

Как гибридные модели ИИ балансируют память и эффективность
Таблица ссылок
Резюме и 1. Введение
-
Методология
-
Эксперименты и результаты
3.1 Языковое моделирование на данных vQuality
3.2 Исследование внимания и линейной рекурсии
3.3 Эффективная экстраполяция длины
3.4 Понимание длинного контекста
-
Анализ
-
Заключение, благодарности и ссылки
A. Детали реализации
B. Дополнительные результаты экспериментов
C. Детали измерения энтропии
D. Ограничения
\
A Детали реализации
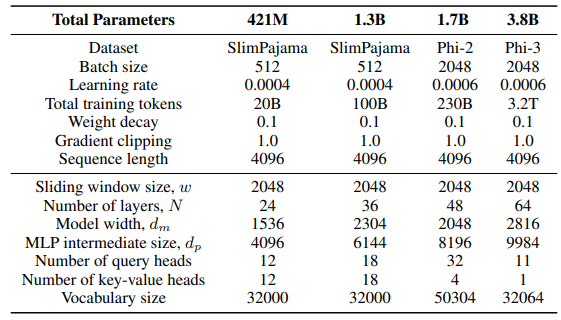
\ Для слоя GLA в архитектуре Sliding GLA мы используем количество головок dm/384, коэффициент расширения ключа 0,5 и коэффициент расширения значения 1. Для слоя RetNet мы используем количество головок, равное половине количества головок запроса внимания, коэффициент расширения ключа 1 и коэффициент расширения значения 2. Реализации GLA и RetNet взяты из репозитория Flash Linear Attention[3] [YZ24]. Мы используем реализацию на основе FlashAttention для экстраполяции Self-Extend[4]. Модель Mamba 432M имеет ширину модели 1024, а модель Mamba 1.3B имеет ширину модели 2048. Все модели, обученные на SlimPajama, имеют одинаковые конфигурации обучения и промежуточный размер MLP, как у Samba, если не указано иное. Инфраструктура обучения на SlimPajama основана на модифицированной версии кодовой базы TinyLlama[5].
\ 
\ В конфигурациях генерации для нисходящих задач мы используем жадное декодирование для GSM8K и выборку Nucleus Sampling [HBD+19] с температурой τ = 0,2 и top-p = 0,95 для HumanEval. Для MBPP и SQuAD мы устанавливаем τ = 0,01 и top-p = 0,95.
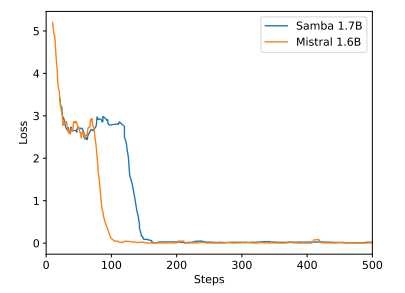
B Дополнительные результаты экспериментов
\ 
\ 
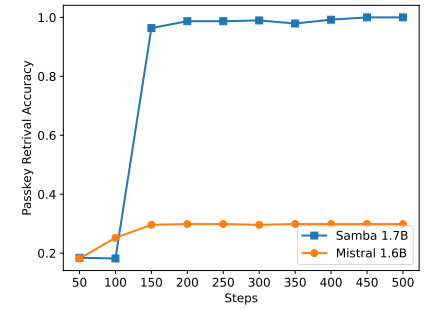
\ 
\
C Детали измерения энтропии
\ 
\
D Ограничения
Хотя Samba демонстрирует многообещающую производительность извлечения памяти через инструктивную настройку, его предварительно обученная базовая модель имеет производительность извлечения, аналогичную модели на основе SWA, как показано на рисунке 7. Это открывает будущее направление по дальнейшему улучшению способности Samba к извлечению без ущерба для его эффективности и способности к экстраполяции. Кроме того, стратегия гибридизации Samba не всегда лучше других альтернатив во всех задачах. Как показано в таблице 2, MambaSWA-MLP показывает улучшенную производительность в таких задачах, как WinoGrande, SIQA и GSM8K. Это дает нам возможность инвестировать в более сложный подход для выполнения зависящих от входных данных динамических комбинаций моделей на основе SWA и SSM.
\
:::info Авторы:
(1) Liliang Ren, Microsoft и University of Illinois at Urbana-Champaign (liliangren@microsoft.com);
(2) Yang Liu†, Microsoft (yaliu10@microsoft.com);
(3) Yadong Lu†, Microsoft (yadonglu@microsoft.com);
(4) Yelong Shen, Microsoft (yelong.shen@microsoft.com);
(5) Chen Liang, Microsoft (chenliang1@microsoft.com);
(6) Weizhu Chen, Microsoft (wzchen@microsoft.com).
:::
:::info Эта статья доступна на arxiv по лицензии CC BY 4.0.
:::
[3] https://github.com/sustcsonglin/flash-linear-attention
\ [4] https://github.com/datamllab/LongLM/blob/master/selfextendpatch/Llama.py
\ [5] https://github.com/jzhang38/TinyLlama





