

Новая настройка IIL: улучшение развернутых моделей только с новыми данными
Таблица ссылок
Резюме и 1 Введение
-
Связанные работы
-
Постановка проблемы
-
Методология
4.1. Дистилляция с учетом границы решения
4.2. Консолидация знаний
-
Экспериментальные результаты и 5.1. Настройка эксперимента
5.2. Сравнение с современными методами
5.3. Исследование методом абляции
-
Заключение и дальнейшая работа и Ссылки
\
Дополнительные материалы
- Детали теоретического анализа механизма KCEMA в IIL
- Обзор алгоритма
- Детали набора данных
- Детали реализации
- Визуализация запыленных входных изображений
- Дополнительные экспериментальные результаты
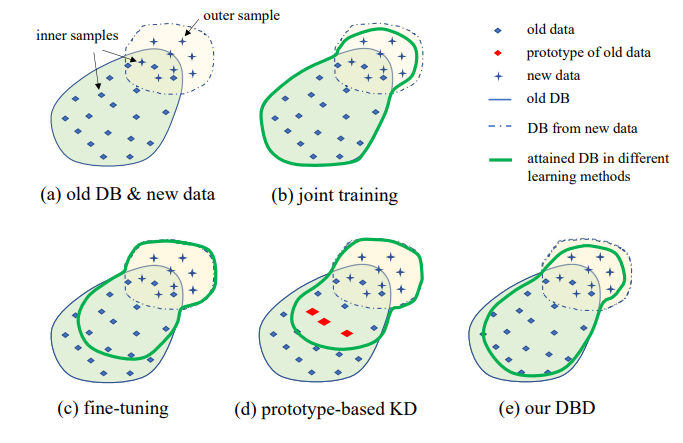
3. Постановка проблемы
Иллюстрация предложенной настройки IIL показана на Рис. 1. Как видно, данные генерируются непрерывно и непредсказуемо в потоке данных. Обычно в реальных приложениях люди склонны сначала собирать достаточно данных и обучать сильную модель M0 для развертывания. Независимо от того, насколько сильна модель, она неизбежно столкнется с данными вне распределения и потерпит неудачу. Эти неудачные случаи и другие новые наблюдения с низкими оценками будут аннотированы для периодического обучения модели. Переобучение модели со всеми накопленными данными каждый раз приводит к все более высоким затратам времени и ресурсов. Поэтому новый IIL направлен на улучшение существующей модели только с новыми данными каждый раз.
\ 
\ 
\
:::info Авторы:
(1) Цян Не, Гонконгский университет науки и технологии (Гуанчжоу);
(2) Вэйфу Фу, Лаборатория Tencent Youtu;
(3) Юхуань Линь, Лаборатория Tencent Youtu;
(4) Цзялинь Ли, Лаборатория Tencent Youtu;
(5) Ифэн Чжоу, Лаборатория Tencent Youtu;
(6) Юн Лю, Лаборатория Tencent Youtu;
(7) Цян Не, Гонконгский университет науки и технологии (Гуанчжоу);
(8) Чэнцзе Ван, Лаборатория Tencent Youtu.
:::
:::info Эта статья доступна на arxiv под лицензией CC BY-NC-ND 4.0 Deed (Attribution-Noncommercial-Noderivs 4.0 International).
:::
\


Вам также может быть интересно

Инфляция ИПЦ Китая замедлилась до 1,0% г/г в марте против ожидаемых 1,2%

Прогноз по серебру: XAG/USD движется в боковом диапазоне ниже $75,50; 200-EMA ограничивает рост




