RLM: Почему ваш LLM-агент забывает цель и как это исправить
10 проблем LLM-приложений и как RLM их обходит — без изменения самой модели.
Теоретические основы https://habr.com/ru/articles/986702/
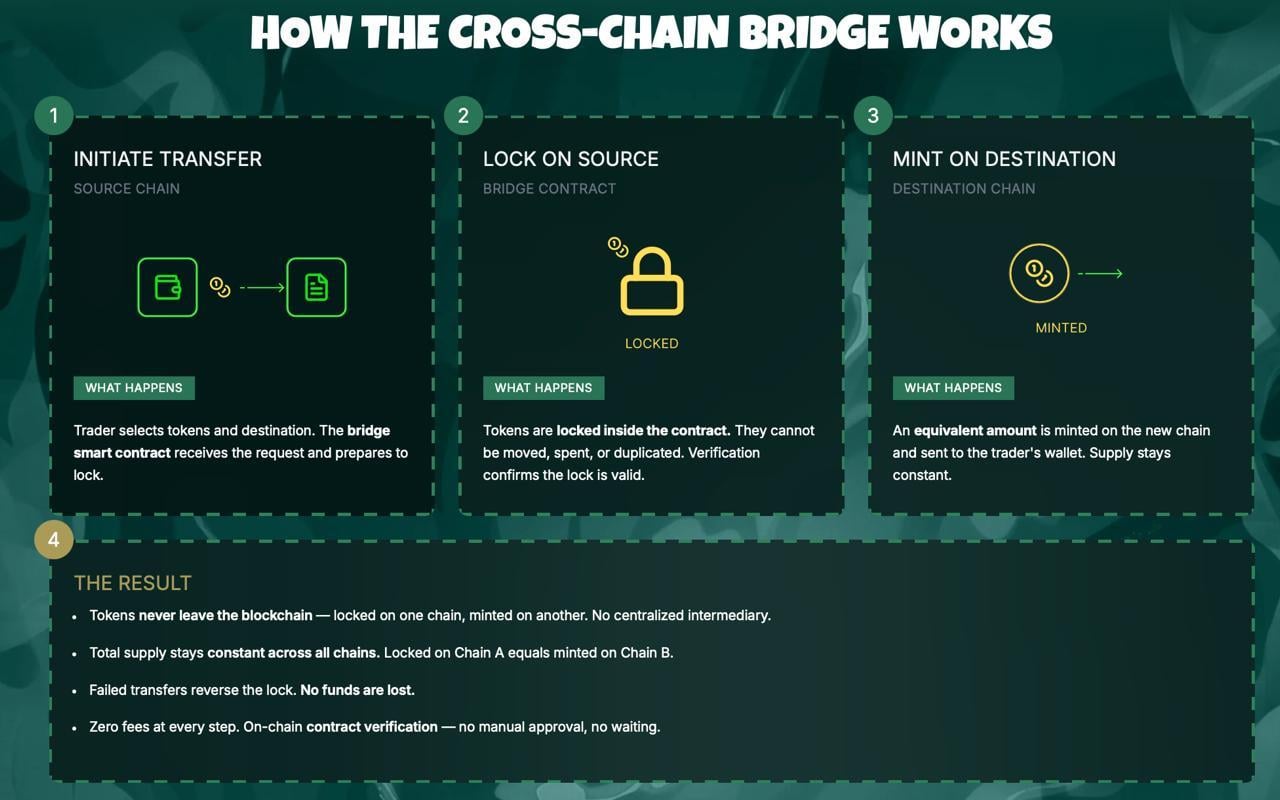
Что такое RLM?
Recursive Language Model — способ использования любой LLM через Python REPL и рекурсивные sub-LLM вызовы.
Обычный подход: [Огромный контекст] → LLM → [Ответ] RLM подход: [Данные в Python] → [Код] → [Sub-LLM] → [Ответ]
Придумал Alex Zhang (октябрь 2025). Я сделал production-ready реализацию.
Проблема 1: Context Rot 🧠💀
Суть: Чем больше контекст, тем хуже работает модель. На 150K токенов модель работает заметно хуже, чем на 10K — attention "размывается".
# Плохо: весь документ в контексте response = llm(f"Документ: {huge_doc}\n\nНайди X") # Context rot! # Хорошо: RLM — документ в Python, LLM пишет код rlm = RLM.from_ollama("llama3") result = rlm.run( context=huge_doc, # В REPL, не в промпте query="Найди X" ) # LLM видит только релевантные куски
Проблема 2: Lost in the Middle 📍
Суть: Информация в середине длинного контекста игнорируется. LLM хорошо помнит начало и конец, но "слепнет" посередине.
# RLM решение: нет "середины" # Данные подгружаются по запросу через Python code = """ # LLM сама решает что читать for chunk in split_document(data['doc'], 1000): if is_relevant(chunk, query): results.append(analyze(chunk)) """
Проблема 3: Goal Drift 🎯
Суть: Агент через 10 шагов забывает изначальную цель. Контекст засоряется, приоритеты сбиваются.
# RLM решение: каждый sub-LLM получает цель заново def solve(goal): plan = llm(f"Создай план для: {goal}") # Свежий контекст for step in plan: # Каждый шаг — новый sub-LLM со свежим контекстом result = llm(f"Цель: {goal}\nВыполни: {step}") return llm(f"Цель: {goal}\nСинтезируй результаты")
Проблема 4: Context Pollution 🗑️
Суть: Мусор накапливается — ошибки, промежуточные шаги, неудачные попытки. Всё это остаётся в контексте.
# RLM решение: только структурированные результаты results = llm_batch([ f"Обработай chunk {i}" for i in range(10) ]) # В main LLM попадает только: clean_results = [r.summary for r in results] # Без мусора
Проблема 5: Credit Assignment 📊
Суть: В long-horizon задачах непонятно, какое действие привело к успеху/провалу. Нет причинно-следственной связи.
# RLM решение: явный trace через иерархию trace = [] for step in plan: result = llm(step) trace.append({ 'step': step, 'result': result, 'contribution': estimate_contribution(result, goal) }) # Теперь видно какой шаг на что повлиял
Проблема 6: Hallucinations 🌈
Суть: LLM уверенно генерирует неправду. "Австралия — столица Австрии!"
# RLM решение: верификация через внешние источники def grounded_answer(question): draft = llm(question) # Проверка через Knowledge Graph / Python facts = verify_with_kg(draft) if facts.has_errors: return llm(f"Исправь: {facts.errors}\n\n{draft}") return draft
Проблема 7: Catastrophic Forgetting 🔥
Суть: Fine-tune модель на задачу A — отлично. Fine-tune на задачу B — задачу A забыла!
# RLM решение: внешняя память H-MEM from rlm_toolkit.memory import HierarchicalMemory hmem = HierarchicalMemory() hmem.add_episode("Пользователь любит Python") hmem.add_episode("Проект на FastAPI") hmem.consolidate() # Модель не меняется, но "помнит" через внешнюю память def respond(query): context = hmem.retrieve(query) return llm(f"{context}\n\n{query}")
Проблема 8: Privacy Leakage 🔐
Суть: Чтобы LLM что-то анализировала — данные нужно отправить в промпт. Конфиденциальные данные утекают.
# RLM решение: данные обрабатываются локально def analyze_private(data_path): code = """ data = load(data_path) # LLM видит только агрегаты, не raw data stats = compute_stats(data) # Без PII! answer['content'] = llm(f"Интерпретируй: {stats}") """ return rlm.run(code)
Проблема 9: Cost Explosion 💸
Суть: Длинный контекст = много токенов = дорого. 100K токенов на GPT-4o = ~$1 за запрос.
# Плохо: весь контекст каждый раз cost = len(huge_context) * n_requests * price_per_token # $$$ # RLM: минимальный контекст каждый раз # Sub-LLM видят только нужные куски cost = avg_chunk_size * n_sub_calls * price_per_token # $
Реальная экономия: В 10-50 раз меньше токенов при работе с большими документами.
Проблема 10: Single Point of Failure 💥
Суть: Одна ошибка LLM ломает всю цепочку. Особенно критично для multi-step агентов.
# RLM решение: изолированные sub-LLM results = [] for chunk in chunks: try: result = llm(f"Обработай: {chunk}") results.append(result) except: results.append(None) # Ошибка изолирована # 9 из 10 успешных — задача всё равно решена final = llm(f"Синтезируй: {[r for r in results if r]}")
FAQ для тех, кто ничего не понял
Q: Что такое LLM?
A: Large Language Model — это ChatGPT, Claude, Gemini и подобные. Нейросеть, которая понимает и генерирует текст.
Q: Что такое "контекст"?
A: Всё что вы отправляете модели: ваш вопрос + история чата + документы. У моделей есть лимит — например, 128K токенов (~100K слов).
Q: Почему "больше контекста = хуже"?
A: Модель как студент на экзамене: дайте ему 3 страницы — запомнит. Дайте 300 — запутается и забудет главное.
Q: Что такое RLM простыми словами?
A: Вместо того чтобы засовывать весь документ в модель, мы даём ей Python. Она сама пишет код чтобы найти нужное, и видит только маленькие кусочки.
Q: Sub-LLM — это что?
A: "Дочерняя" модель. Как делегирование задачи коллеге — он делает свою часть работы со свежей головой.
Q: Это работает с ChatGPT?
A: Да, RLM-Toolkit работает с 75+ провайдерами: OpenAI, Anthropic, Google, Ollama, ваш локальный сервер.
Q: Мне нужно менять модель?
A: Нет! RLM — это обёртка. Модель остаётся той же, меняется только способ её использования.
Q: Сколько это стоит?
A: RLM-Toolkit бесплатный (Apache 2.0). Платите только за API модели, причём меньше — потому что меньше токенов.
Итого
|
# |
Проблема |
Обычный LLM |
RLM |
|---|---|---|---|
|
1 |
Context Rot |
💀 |
✅ Минимальный контекст |
|
2 |
Lost in Middle |
💀 |
✅ Данные по запросу |
|
3 |
Goal Drift |
💀 |
✅ Свежий контекст |
|
4 |
Pollution |
💀 |
✅ Только результаты |
|
5 |
Credit Assignment |
💀 |
✅ Явный trace |
|
6 |
Hallucinations |
💀 |
✅ Верификация |
|
7 |
Forgetting |
💀 |
✅ Внешняя память |
|
8 |
Privacy |
💀 |
✅ Локально |
|
9 |
Cost |
💀 |
✅ Меньше токенов |
|
10 |
Single Failure |
💀 |
✅ Изоляция |
Попробовать
pip install rlm-toolkit
from rlm_toolkit import RLM rlm = RLM.from_ollama("llama3") # 75+ провайдеров result = rlm.run( context=open("huge_file.txt").read(), query="Найди главные выводы" ) print(result.answer)
Ссылки:
-
PyPI
-
Документация
-
Оригинал Alex Zhang
-
Prime Intellect research
Источник


Вам также может быть интересно
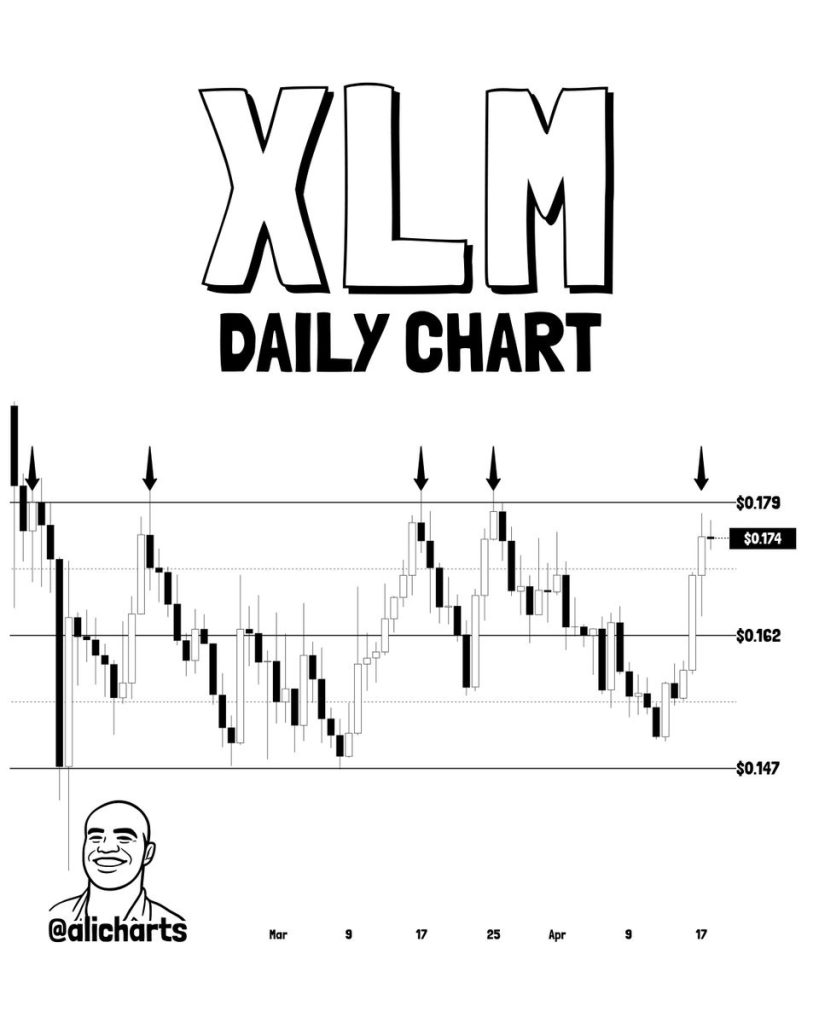
Цена Stellar (XLM) продолжает упираться в одну и ту же стену, но этот четвертый повторный тест может стать тем, который прорвется

Стейблкоины не представляют угрозы для банков в ближайшей перспективе: аналитик Moody's