

Як суміш адаптацій робить точне налаштування мовної моделі дешевшим і розумнішим
Таблиця посилань
Анотація та 1. Вступ
-
Передумови
2.1 Суміш експертів
2.2 Адаптери
-
Суміш адаптацій
3.1 Політика маршрутизації
3.2 Регуляризація узгодженості
3.3 Об'єднання модулів адаптації та 3.4 Спільне використання модулів адаптації
3.5 Зв'язок з байєсівськими нейронними мережами та ансамблюванням моделей
-
Експерименти
4.1 Експериментальна установка
4.2 Ключові результати
4.3 Дослідження абляції
-
Пов'язані роботи
-
Висновки
-
Обмеження
-
Подяки та посилання
Додаток
A. Набори даних NLU з малою кількістю прикладів B. Дослідження абляції C. Детальні результати на завданнях NLU D. Гіперпараметри
3 Суміш адаптацій

\
3.1 Політика маршрутизації
нещодавні роботи, такі як THOR (Zuo et al., 2021), продемонстрували, що стохастична політика маршрутизації, наприклад випадкова маршрутизація, працює так само добре, як і класичний механізм маршрутизації, такий як Switch routing (Fedus et al., 2021), з наступними перевагами. оскільки вхідні приклади випадково направляються до різних експертів, немає потреби в додатковому балансуванні навантаження, оскільки кожен експерт має рівні можливості бути активованим, що спрощує структуру. крім того, немає додаткових параметрів і, отже, додаткових обчислень на рівні Switch для вибору експерта. останнє особливо важливо в нашому налаштуванні для параметрично-ефективного точного налаштування, щоб зберегти параметри та FLOPs такими ж, як у одного модуля адаптації. для аналізу роботи AdaMix ми демонструємо зв'язки між стохастичною маршрутизацією та усередненням ваг моделі з байєсівськими нейронними мережами та ансамблюванням моделей у розділі 3.5.
\ \ 
\ \ така стохастична маршрутизація дозволяє модулям адаптації вивчати різні перетворення під час навчання та отримувати кілька поглядів на завдання. однак це також створює проблему щодо того, які модулі використовувати під час виведення через протокол випадкової маршрутизації під час навчання. ми вирішуємо цю проблему за допомогою наступних двох методів, які додатково дозволяють нам згорнути модулі адаптації та отримати ті самі обчислювальні витрати (FLOPs, кількість налаштовуваних параметрів адаптації), що й у одного модуля.
3.2 Регуляризація узгодженості
\ 
\ \ \ 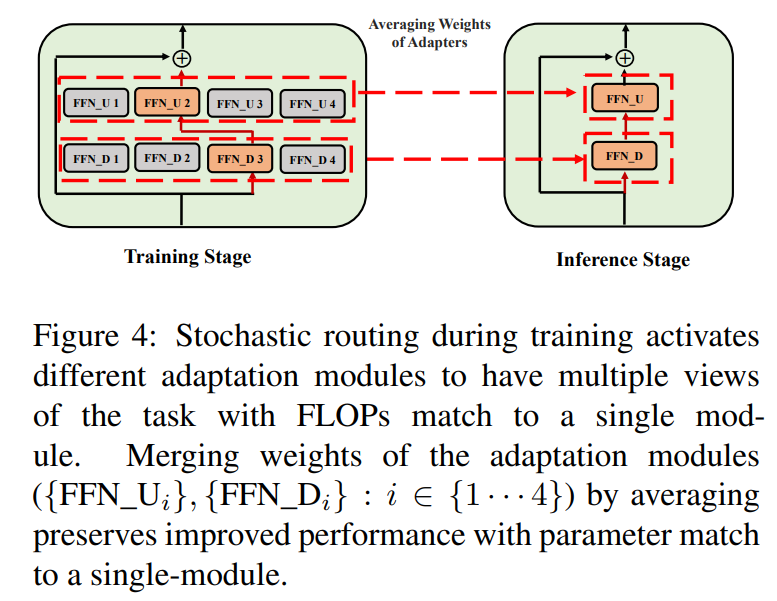
3.3 Об'єднання модулів адаптації
хоча вищезазначена регуляризація зменшує неузгодженість у випадковому виборі модуля під час виведення, вона все ще призводить до збільшення витрат на обслуговування для розміщення кількох модулів адаптації. попередні роботи з точного налаштування мовних моделей для подальших завдань показали покращену продуктивність при усередненні ваг різних моделей, точно налаштованих з різними випадковими зернами, перевершуючи одну точно налаштовану модель. нещодавня робота (Wortsman et al., 2022) також показала, що по-різному точно налаштовані моделі з однаковою ініціалізацією лежать в одному басейні помилок, що мотивує використання агрегації ваг для надійного узагальнення завдань. ми адаптуємо та розширюємо попередні методи для точного налаштування мовної моделі до нашого параметрично-ефективного навчання модулів адаптації з кількома поглядами
\ \ 
\
3.4 Спільне використання модулів адаптації
\ 
3.5 Зв'язок з байєсівськими нейронними мережами та ансамблюванням моделей
\ 
\ \ це вимагає усереднення за всіма можливими вагами моделі, що на практиці нездійсненно. тому було розроблено кілька методів апроксимації на основі методів варіаційного виведення та методів стохастичної регуляризації з використанням дропаутів. у цій роботі ми використовуємо іншу стохастичну регуляризацію у формі випадкової маршрутизації. тут метою є знаходження сурогатного розподілу qθ(w) у керованому сімействі розподілів, який може замінити справжній апостеріорний розподіл моделі, який важко обчислити. ідеальний сурогат визначається шляхом мінімізації розбіжності Кульбака-Лейблера (KL) між кандидатом і справжнім апостеріорним розподілом.
\ \ 
\ \ \ 
\ \ \ 
\ \ \ \
:::info Автори:
(1) Yaqing Wang, Purdue University (wang5075@purdue.edu);
(2) Sahaj Agarwal, Microsoft (sahagar@microsoft.com);
(3) Subhabrata Mukherjee, Microsoft Research (submukhe@microsoft.com);
(4) Xiaodong Liu, Microsoft Research (xiaodl@microsoft.com);
(5) Jing Gao, Purdue University (jinggao@purdue.edu);
(6) Ahmed Hassan Awadallah, Microsoft Research (hassanam@microsoft.com);
(7) Jianfeng Gao, Microsoft Research (jfgao@microsoft.com).
:::
:::info Ця стаття доступна на arxiv за ліцензією CC BY 4.0 DEED.
:::
\
Вам також може сподобатися

Eumir Marcial здобуває єдине золото Філіппін у боксі на Іграх Південно-Східної Азії 2025

Ліофільні сушарки: повний посібник із збереження продуктів харчування, фармацевтичних препаратів та іншого
