

Вирішення найбільшого вузького місця 3D-сегментації
:::info Автори:
(1) Джордж Танг, Массачусетський технологічний інститут;
(2) Крішна Мурті Джатаваллабхула, Массачусетський технологічний інститут;
(3) Антоніо Торральба, Массачусетський технологічний інститут.
:::
Зміст посилань
Анотація та I. Вступ
II. Передумови
III. Метод
IV. Експерименти
V. Висновок та посилання
\ 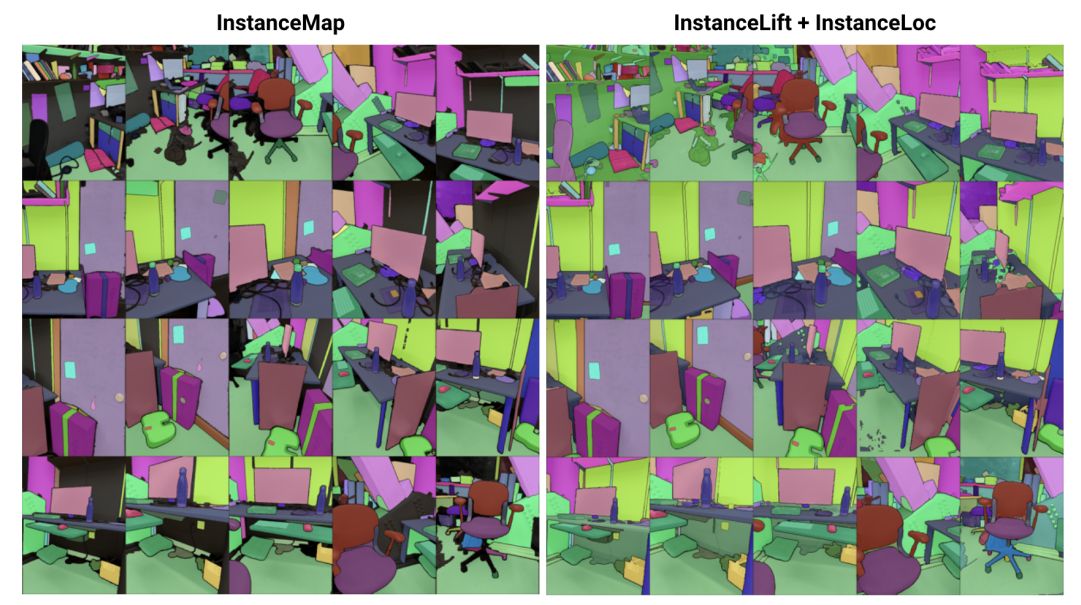
\ Анотація— Ми вирішуємо проблему вивчення неявного представлення сцени для 3D сегментації екземплярів із послідовності позиціонованих RGB-зображень. Для цього ми представляємо 3DIML, новий фреймворк, який ефективно вивчає поле міток, яке можна відтворювати з нових точок зору для створення візуально-послідовних масок сегментації екземплярів. 3DIML значно покращує час навчання та виведення існуючих методів, заснованих на неявному представленні сцени. На відміну від попередніх підходів, які оптимізують нейронне поле в режимі самонавчання, що вимагає складних процедур навчання та проектування функцій втрат, 3DIML використовує двофазний процес. Перша фаза, InstanceMap, приймає як вхідні дані 2D маски сегментації послідовності зображень, створені фронтенд-моделлю сегментації екземплярів, і пов'язує відповідні маски між зображеннями з 3D мітками. Ці майже візуально-послідовні псевдомітки потім використовуються у другій фазі, InstanceLift, для нагляду за навчанням нейронного поля міток, яке інтерполює області, пропущені InstanceMap, і вирішує неоднозначності. Крім того, ми представляємо InstanceLoc, який забезпечує локалізацію масок екземплярів у режимі, близькому до реального часу, за допомогою навченого поля міток і готової моделі сегментації зображень шляхом об'єднання виходів обох. Ми оцінюємо 3DIML на послідовностях із наборів даних Replica та ScanNet і демонструємо ефективність 3DIML за помірних припущень для послідовностей зображень. Ми досягаємо значного практичного прискорення порівняно з існуючими методами неявного представлення сцени з порівнянною якістю, демонструючи його потенціал для сприяння швидшому та ефективнішому розумінню 3D сцен.
I. ВСТУП
Інтелектуальні агенти потребують розуміння сцени на рівні об'єктів для ефективного виконання контекстно-специфічних дій, таких як навігація та маніпуляція. Хоча сегментація об'єктів із зображень досягла значного прогресу завдяки масштабованим моделям, навченим на наборах даних інтернет-масштабу [1], [2], розширення таких можливостей до 3D-налаштування залишається складним завданням.
\ У цій роботі ми вирішуємо проблему вивчення 3D-представлення сцени з позиціонованих 2D-зображень, яке факторизує основну сцену на набір її складових об'єктів. Існуючі підходи до вирішення цієї проблеми зосереджувалися на навчанні класово-агностичних 3D-моделей сегментації [3], [4], що вимагають великої кількості анотованих 3D-даних і працюють безпосередньо з явними 3D-представленнями сцени (наприклад, хмарами точок). Альтернативний клас підходів [5], [6] натомість запропонував безпосередньо переносити маски сегментації з готових моделей сегментації екземплярів у неявні 3D-представлення, такі як нейронні поля випромінювання (NeRF) [7], що дозволяє їм відтворювати 3D-послідовні маски екземплярів з нових точок зору.
\ Однак підходи, засновані на нейронних полях, залишаються надзвичайно складними для оптимізації, при цьому [5] і [6] витрачають кілька годин на оптимізацію для зображень низької та середньої роздільної здатності (наприклад, 300 × 640). Зокрема, Panoptic Lifting [5] масштабується кубічно з кількістю об'єктів у сцені, що перешкоджає його застосуванню до сцен із сотнями об'єктів, тоді як Contrastively Lifting [6] вимагає складної багатоетапної процедури навчання, що перешкоджає практичності використання в робототехнічних застосунках.
\ З цією метою ми пропонуємо 3DIML, ефективну техніку для вивчення 3D-послідовної сегментації екземплярів із позиціонованих RGB-зображень. 3DIML складається з двох фаз: InstanceMap та InstanceLift. Враховуючи візуально-непослідовні 2D-маски екземплярів, витягнуті з RGB-послідовності за допомогою фронтенд-моделі сегментації екземплярів [2], InstanceMap створює послідовність візуально-послідовних масок екземплярів. Для цього ми спочатку пов'язуємо маски між кадрами, використовуючи збіги ключових точок між подібними парами зображень. Потім ми використовуємо ці потенційно шумні асоціації для нагляду за нейронним полем міток, InstanceLift, яке використовує 3D-структуру для інтерполяції відсутніх міток і вирішення неоднозначностей. На відміну від попередніх робіт, які вимагають багатоетапного навчання та додаткового проектування функцій втрат, ми використовуємо єдину функцію втрат для рендерингу для нагляду за мітками екземплярів, що дозволяє процесу навчання сходитися значно швидше. Загальний час виконання 3DIML, включаючи InstanceMap, становить 10-20 хвилин, на відміну від 3-6 годин для попередніх підходів.
\ Крім того, ми розробляємо InstaLoc, швидкий конвеєр локалізації, який приймає новий вигляд і локалізує всі екземпляри, сегментовані на цьому зображенні (використовуючи швидку модель сегментації екземплярів [8]), шляхом розрідженого запиту до поля міток і об'єднання прогнозів міток із витягнутими областями зображення. Нарешті, 3DIML є надзвичайно модульним, і ми можемо легко замінювати компоненти нашого методу на більш продуктивні, коли вони стають доступними.
\ Підсумовуючи, наші внески такі:
\ • Ефективний підхід до вивчення нейронного поля, який факторизує 3D-сцену на її складові об'єкти
\ • Швидкий алгоритм локалізації екземплярів, який об'єднує розріджені запити до навченого поля міток із продуктивними моделями сегментації екземплярів зображень для створення 3D-послідовних масок сегментації екземплярів
\ • Загальне практичне покращення часу виконання в 14-24 рази порівняно з попередніми підходами, протестоване на одному GPU (NVIDIA RTX 3090)
II. ПЕРЕДУМОВИ
2D сегментація: Поширення архітектури трансформерів зору та збільшення масштабу наборів даних зображень призвели до появи серії сучасних моделей сегментації зображень. Panoptic та Contrastive Lifting обидва переносять панорамні маски сегментації, створені Mask2Former [1], у 3D, вивчаючи нейронне поле. Для сегментації з відкритим набором, segment anything (SAM) [2] досягає безпрецедентної продуктивності, навчаючись на мільярді масок на 11 мільйонах зображень. HQ-SAM [9] покращує SAM для детальних масок. FastSAM [8] дистилює SAM у CNN-архітектуру і досягає подібної продуктивності, будучи на порядки швидшим. У цій роботі ми використовуємо GroundedSAM [10], [11], який удосконалює SAM для створення сегментаційних масок на рівні об'єктів, а не на рівні частин.
\ Нейронні поля для 3D сегментації екземплярів: NeRF - це неявні представлення сцени, які можуть точно кодувати складну геометрію, семантику та інші модальності, а також вирішувати непослідовний нагляд з точки зору [12]. Panoptic lifting [5] будує семантичні гілки та гілки екземплярів на ефективному варіанті NeRF, TensoRF [13], використовуючи функцію втрат угорського зіставлення для призначення вивчених масок екземплярів сурогатним ідентифікаторам об'єктів, враховуючи еталонні візуально-непослідовні маски. Це погано масштабується зі збільшенням кількості об'єктів (через кубічну складність угорського зіставлення). Contrastive lifting [6] вирішує це, натомість застосовуючи контрастне навчання на ознаках сцени, з позитивними та негативними відносинами, визначеними тим, чи проектуються вони на ту саму маску. Крім того, contrastive lifting вимагає повільно-швидкої функції втрат на основі кластеризації для стабільного навчання, що призводить до швидшої продуктивності, ніж panoptic lifting, але вимагає кількох етапів навчання, що призводить до повільної збіжності. Паралельно з нами, Instance-NeRF [14] безпосередньо вивчає поле міток, але вони базували свою асоціацію масок на використанні NeRF-RPN [15] для виявлення об'єктів у NeRF. Наш підхід, навпаки, дозволяє масштабування до дуже високої роздільної здатності зображень, вимагаючи лише невеликої кількості (40-60) запитів до нейронного поля для відтворення масок сегментації.
\ Структура з руху: Під час асоціації масок в InstanceMap ми черпаємо натхнення з масштабованих конвеєрів 3D-реконструкції, таких як hLoc [16], включаючи використання візуальних дескрипторів для зіставлення точок зору зображень спочатку, а потім застосування зіставлення ключових точок як попереднього етапу для асоціації масок. Ми використовуємо LoFTR [17] для витягування та зіставлення ключових точок.
\
:::info Ця стаття доступна на arxiv за ліцензією CC by 4.0 Deed (Attribution 4.0 International).
:::
\
Вам також може сподобатися

Чому деякі все ще переїжджають до "Блакитної зони" Боракай

Очікується, що основна галузь штучного інтелекту в Китаї перевищить один трильйон юанів за масштабом до 2025 року.
