

Як гібридні моделі ШІ балансують пам'ять та ефективність
Таблиця посилань
Анотація та 1. Вступ
-
Методологія
-
Експерименти та результати
3.1 Моделювання мови на даних vQuality
3.2 Дослідження уваги та лінійної рекурсії
3.3 Ефективна екстраполяція довжини
3.4 Розуміння довгого контексту
-
Аналіз
-
Висновок, подяка та посилання
A. Деталі реалізації
B. Додаткові результати експериментів
C. Деталі вимірювання ентропії
D. Обмеження
\
A Деталі реалізації
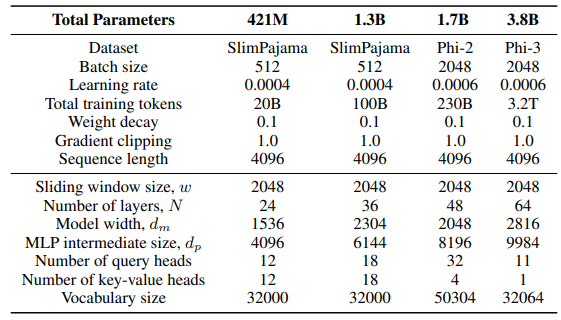
\ Для шару GLA в архітектурі Sliding GLA ми використовуємо кількість голів dm/384, коефіцієнт розширення ключа 0,5 та коефіцієнт розширення значення 1. Для шару RetNet ми використовуємо кількість голів, що становить половину кількості голів запиту уваги, коефіцієнт розширення ключа 1 та коефіцієнт розширення значення 2. Реалізації GLA та RetNet взяті з репозиторію Flash Linear Attention[3] [YZ24]. Ми використовуємо реалізацію на основі FlashAttention для екстраполяції Self-Extend[4]. Модель Mamba 432M має ширину моделі 1024, а модель Mamba 1.3B має ширину моделі 2048. Усі моделі, навчені на SlimPajama, мають однакові конфігурації навчання та проміжний розмір MLP як у Samba, якщо не вказано інше. Інфраструктура навчання на SlimPajama базується на модифікованій версії кодової бази TinyLlama[5].
\ 
\ У конфігураціях генерації для завдань нижчого рівня ми використовуємо жадібне декодування для GSM8K та вибірку Nucleus [HBD+19] з температурою τ = 0,2 та top-p = 0,95 для HumanEval. Для MBPP та SQuAD ми встановлюємо τ = 0,01 та top-p = 0,95.
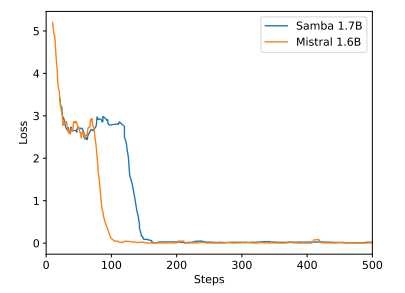
B Додаткові результати експериментів
\ 
\ 
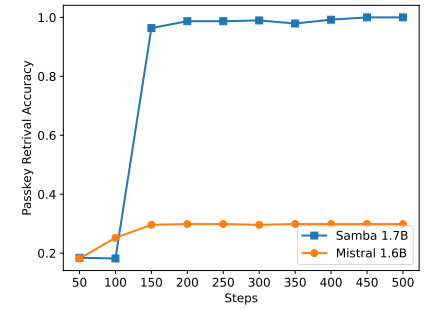
\ 
\
C Деталі вимірювання ентропії
\ 
\
D Обмеження
Хоча Samba демонструє перспективну продуктивність отримання пам'яті через інструктивне налаштування, її попередньо навчена базова модель має продуктивність отримання, подібну до моделі на основі SWA, як показано на рисунку 7. Це відкриває майбутній напрямок для подальшого покращення здатності Samba до отримання без шкоди для її ефективності та здатності до екстраполяції. Крім того, стратегія гібридизації Samba не завжди краща за інші альтернативи у всіх завданнях. Як показано в таблиці 2, MambaSWA-MLP показує покращену продуктивність у таких завданнях, як WinoGrande, SIQA та GSM8K. Це дає нам потенціал для інвестування в більш складний підхід для виконання залежних від вхідних даних динамічних комбінацій моделей на основі SWA та SSM.
\
:::info Автори:
(1) Liliang Ren, Microsoft та University of Illinois at Urbana-Champaign (liliangren@microsoft.com);
(2) Yang Liu†, Microsoft (yaliu10@microsoft.com);
(3) Yadong Lu†, Microsoft (yadonglu@microsoft.com);
(4) Yelong Shen, Microsoft (yelong.shen@microsoft.com);
(5) Chen Liang, Microsoft (chenliang1@microsoft.com);
(6) Weizhu Chen, Microsoft (wzchen@microsoft.com).
:::
:::info Ця стаття доступна на arxiv за ліцензією CC BY 4.0.
:::
[3] https://github.com/sustcsonglin/flash-linear-attention
\ [4] https://github.com/datamllab/LongLM/blob/master/selfextendpatch/Llama.py
\ [5] https://github.com/jzhang38/TinyLlama
Вам також може сподобатися

'Bitcoin Rodney' загрожує десятиліття у в'язниці, оскільки федерали додали шахрайство з використанням електронних засобів зв'язку до звинувачень у справі HyperFund

Ціна Solana застигла навіть після нових угод, експерти вважають, що GeeFi (GEE) може перевершити її
