

Нове налаштування IIL: покращення розгорнутих моделей лише з новими даними
Таблиця посилань
Анотація та 1 Вступ
-
Пов'язані роботи
-
Постановка проблеми
-
Методологія
4.1. Дистиляція з урахуванням меж прийняття рішень
4.2. Консолідація знань
-
Експериментальні результати та 5.1. Налаштування експерименту
5.2. Порівняння з методами SOTA
5.3. Дослідження абляції
-
Висновок та майбутня робота та Посилання
\
Додатковий матеріал
- Деталі теоретичного аналізу механізму KCEMA в IIL
- Огляд алгоритму
- Деталі набору даних
- Деталі реалізації
- Візуалізація запилених вхідних зображень
- Більше експериментальних результатів
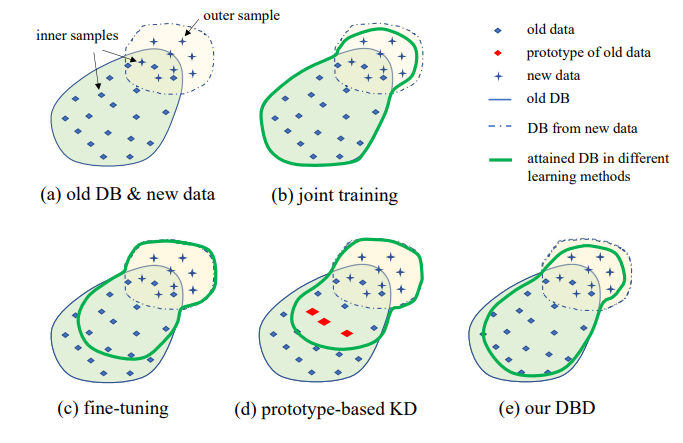
3. Постановка проблеми
Ілюстрація запропонованого налаштування IIL показана на рис. 1. Як можна побачити, дані генеруються безперервно та непередбачувано в потоці даних. Загалом у реальному застосуванні люди схильні спочатку зібрати достатньо даних і навчити сильну модель M0 для розгортання. Незалежно від того, наскільки сильною є модель, вона неминуче зіткнеться з даними поза розподілом і зазнає невдачі. Ці невдалі випадки та інші нові спостереження з низькою оцінкою будуть анотовані для навчання моделі час від часу. Перенавчання моделі з усіма накопиченими даними щоразу призводить до все більших витрат часу та ресурсів. Тому новий IIL спрямований на вдосконалення існуючої моделі лише з новими даними кожного разу.
\ 
\ 
\
:::info Автори:
(1) Цян Не, Гонконгський університет науки і технології (Гуанчжоу);
(2) Вейфу Фу, Лабораторія Tencent Youtu;
(3) Юхуань Лінь, Лабораторія Tencent Youtu;
(4) Цзялінь Лі, Лабораторія Tencent Youtu;
(5) Іфен Чжоу, Лабораторія Tencent Youtu;
(6) Юн Лю, Лабораторія Tencent Youtu;
(7) Цян Не, Гонконгський університет науки і технології (Гуанчжоу);
(8) Ченцзе Ван, Лабораторія Tencent Youtu.
:::
:::info Ця стаття доступна на arxiv за ліцензією CC BY-NC-ND 4.0 Deed (Attribution-Noncommercial-Noderivs 4.0 International).
:::
\
Вам також може сподобатися

'Bitcoin Rodney' загрожує десятиліття у в'язниці, оскільки федерали додали шахрайство з використанням електронних засобів зв'язку до звинувачень у справі HyperFund

Чи завершено скидання ціни Bittensor (TAO)? Цей рівень може визначити наступне зростання в 5 разів
