

Matting hướng dẫn bằng mặt nạ mạnh mẽ: Quản lý đầu vào nhiễu và tính linh hoạt của đối tượng
Bảng Liên Kết
Tóm tắt và 1. Giới thiệu
-
Các Công Trình Liên Quan
-
MaGGIe
3.1. Matting Thực Thể Có Hướng Dẫn Mặt Nạ Hiệu Quả
3.2. Tính Nhất Quán Thời Gian Feature-Matte
-
Bộ Dữ Liệu Matting Thực Thể
4.1. Matting Thực Thể Ảnh và 4.2. Matting Thực Thể Video
-
Thí Nghiệm
5.1. Tiền huấn luyện trên dữ liệu ảnh
5.2. Huấn luyện trên dữ liệu video
-
Thảo Luận và Tài Liệu Tham Khảo
\ Tài Liệu Bổ Sung
-
Chi tiết kiến trúc
-
Matting ảnh
8.1. Tạo và chuẩn bị bộ dữ liệu
8.2. Chi tiết huấn luyện
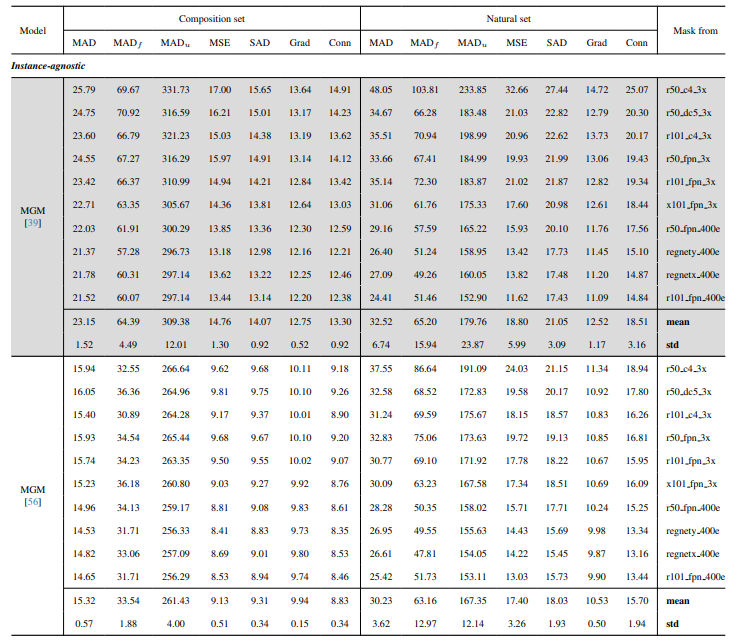
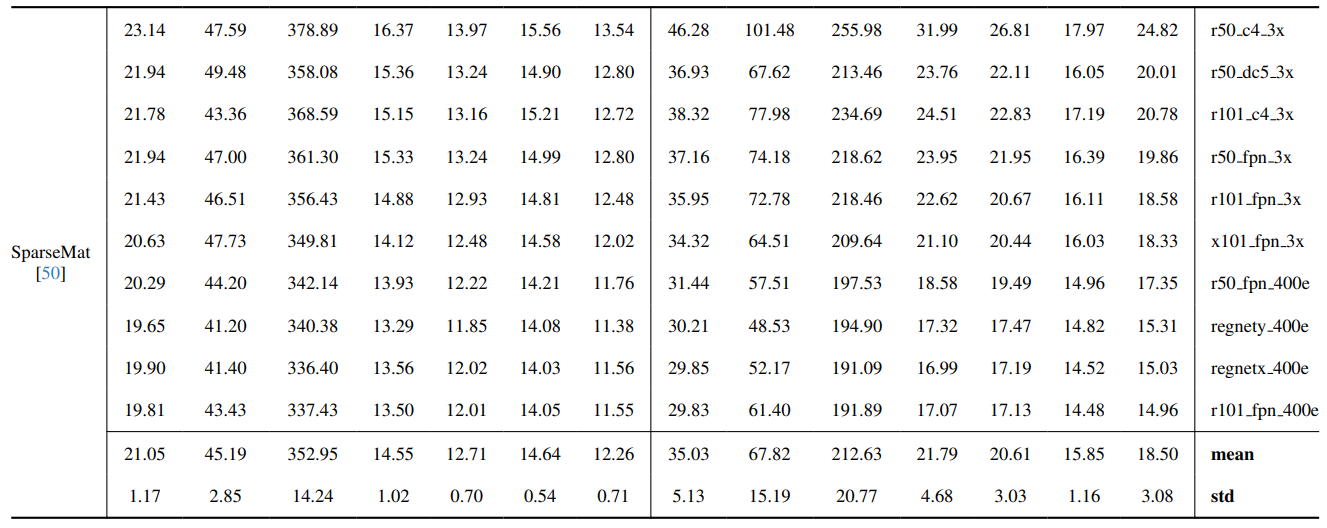
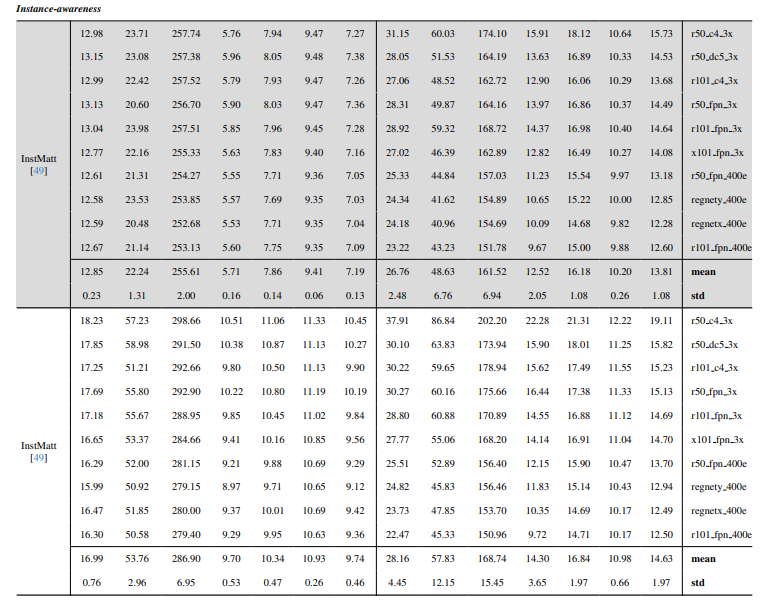
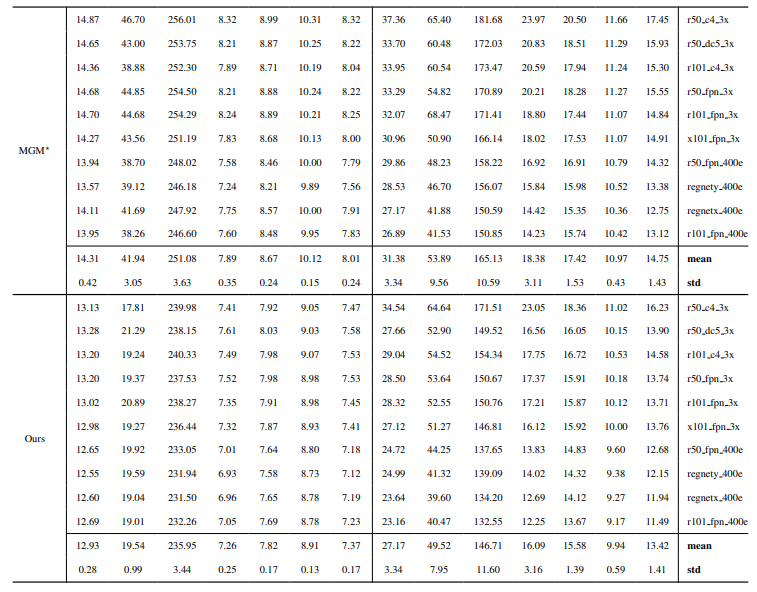
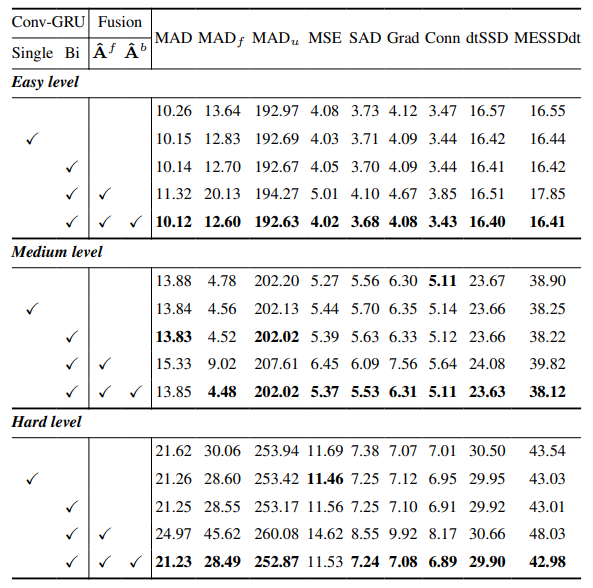
8.3. Chi tiết định lượng
8.4. Thêm kết quả định tính trên ảnh tự nhiên
-
Matting video
9.1. Tạo bộ dữ liệu
9.2. Chi tiết huấn luyện
9.3. Chi tiết định lượng
9.4. Thêm kết quả định tính
8.4. Thêm kết quả định tính trên ảnh tự nhiên
Hình 13 giới thiệu hiệu suất của mô hình chúng tôi trong các tình huống thử thách, đặc biệt là trong việc tái tạo chính xác vùng tóc. Framework của chúng tôi luôn vượt trội hơn MGM⋆ trong việc bảo toàn chi tiết, đặc biệt trong các tương tác thực thể phức tạp. So với InstMatt, mô hình của chúng tôi thể hiện khả năng phân tách thực thể và độ chính xác chi tiết vượt trội trong các vùng mơ hồ.
\ Hình 14 và Hình 15 minh họa hiệu suất của mô hình chúng tôi và các công trình trước đây trong các trường hợp cực đoan liên quan đến nhiều thực thể. Trong khi MGM⋆ gặp khó khăn với nhiễu và độ chính xác trong các tình huống thực thể dày đặc, mô hình của chúng tôi duy trì độ chính xác cao. InstMatt, không có dữ liệu huấn luyện bổ sung, cho thấy những hạn chế trong các cài đặt phức tạp này.
\ Sự mạnh mẽ của phương pháp có hướng dẫn mặt nạ của chúng tôi được chứng minh thêm trong Hình 16. Ở đây, chúng tôi nêu bật những thách thức mà các biến thể MGM và SparseMat gặp phải trong việc dự đoán các phần còn thiếu trong đầu vào mặt nạ, mà mô hình của chúng tôi giải quyết. Tuy nhiên, điều quan trọng cần lưu ý là mô hình của chúng tôi không được thiết kế như một mạng phân đoạn thực thể con người. Như được hiển thị trong Hình 17, framework của chúng tôi tuân thủ hướng dẫn đầu vào, đảm bảo dự đoán alpha matte chính xác ngay cả với nhiều thực thể trong cùng một mặt nạ.
\ Cuối cùng, Hình 12 và Hình 11 nhấn mạnh khả năng tổng quát hóa của mô hình chúng tôi. Mô hình trích xuất chính xác cả đối tượng con người và các đối tượng khác khỏi nền, thể hiện tính linh hoạt của nó trong các tình huống và loại đối tượng khác nhau.
\ Tất cả các ví dụ là ảnh Internet không có ground-truth và mặt nạ từ r101fpn400e được sử dụng làm hướng dẫn.
\ 
\ 
\ 
\ 
\ 
\ 
\ 
\ 
\ 
\ 
\
:::info Tác giả:
(1) Chuong Huynh, University of Maryland, College Park (chuonghm@cs.umd.edu);
(2) Seoung Wug Oh, Adobe Research (seoh,jolee@adobe.com);
(3) Abhinav Shrivastava, University of Maryland, College Park (abhinav@cs.umd.edu);
(4) Joon-Young Lee, Adobe Research (jolee@adobe.com).
:::
:::info Bài báo này có sẵn trên arxiv theo giấy phép CC by 4.0 Deed (Attribution 4.0 International).
:::
\


Có thể bạn cũng thích

Không phải lỗ hổng: Kiểm soát xuất khẩu AI của Singapore cho phép Trung Quốc tiếp cận AI của Mỹ một cách hợp pháp

Bitcoin Futures Vĩnh cửu: Tỷ lệ Long/Short trên các sàn giao dịch hàng đầu

Hệ sinh thái LAB Token: Nền tảng giao dịch đa chuỗi & Hướng dẫn phần thưởng


Tin tức xu hướng
ThêmTin tức trực tiếp 24/7
ThêmĐọc nhanh
Thêm
