

كيف توازن نماذج الذكاء الاصطناعي الهجينة بين الذاكرة والكفاءة
جدول الروابط
نبذة مختصرة و 1. المقدمة
-
المنهجية
-
التجارب والنتائج
3.1 نمذجة اللغة على بيانات vQuality
3.2 استكشاف الانتباه والتكرار الخطي
3.3 استقراء الطول الفعال
3.4 فهم السياق الطويل
-
التحليل
-
الخاتمة، شكر وتقدير، والمراجع
أ. تفاصيل التنفيذ
ب. نتائج تجارب إضافية
ج. تفاصيل قياس الإنتروبيا
د. القيود
\
أ تفاصيل التنفيذ
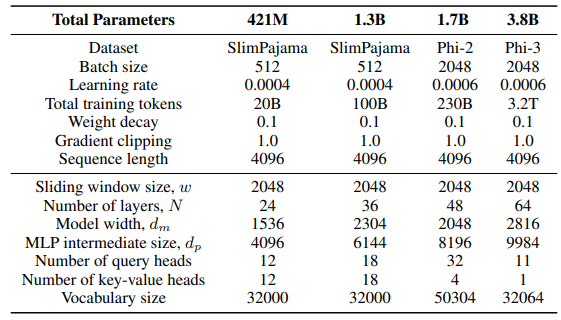
\ بالنسبة لطبقة GLA في بنية Sliding GLA، نستخدم عدد الرؤوس dm/384، ونسبة توسيع المفتاح 0.5، ونسبة توسيع القيمة 1. بالنسبة لطبقة RetNet نستخدم عددًا من الرؤوس يساوي نصف عدد رؤوس استعلام الانتباه، ونسبة توسيع المفتاح 1 ونسبة توسيع القيمة 2. تأتي تطبيقات GLA وRetNet من مستودع Flash Linear Attention[3] [YZ24]. نستخدم التطبيق المعتمد على FlashAttention للاستقراء الذاتي Self-Extend[4]. نموذج Mamba 432M له عرض نموذج 1024 ونموذج Mamba 1.3B له عرض نموذج 2048. جميع النماذج المدربة على SlimPajama لها نفس تكوينات التدريب وحجم MLP الوسيط مثل Samba، ما لم يُذكر خلاف ذلك. تعتمد بنية التدريب على SlimPajama على نسخة معدلة من قاعدة الشفرة TinyLlama[5].
\ 
\ في تكوينات التوليد للمهام اللاحقة، نستخدم فك التشفير الجشع لـ GSM8K، وأخذ العينات النووية [HBD+19] بدرجة حرارة τ = 0.2 وtop-p = 0.95 لـ HumanEval. بالنسبة لـ MBPP وSQuAD، نضبط τ = 0.01 وtop-p = 0.95.
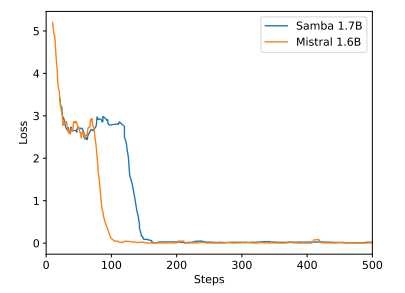
ب نتائج تجارب إضافية
\ 
\ 
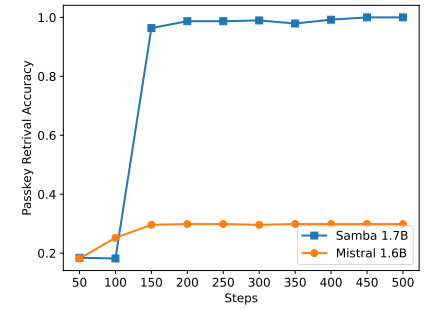
\ 
\
ج تفاصيل قياس الإنتروبيا
\ 
\
د القيود
على الرغم من أن Samba يُظهر أداءً واعدًا في استرجاع الذاكرة من خلال ضبط التعليمات، إلا أن نموذجه الأساسي المدرب مسبقًا له أداء استرجاع مشابه لأداء النموذج المعتمد على SWA، كما هو موضح في الشكل 7. هذا يفتح اتجاهًا مستقبليًا لتحسين قدرة Samba على الاسترجاع دون المساس بكفاءته وقدرته على الاستقراء. بالإضافة إلى ذلك، فإن استراتيجية التهجين في Samba ليست أفضل باستمرار من البدائل الأخرى في جميع المهام. كما هو موضح في الجدول 2، يُظهر MambaSWA-MLP أداءً محسنًا في مهام مثل WinoGrande وSIQA وGSM8K. هذا يمنحنا إمكانية الاستثمار في نهج أكثر تطوراً لإجراء مجموعات ديناميكية تعتمد على المدخلات من النماذج المعتمدة على SWA والنماذج المعتمدة على SSM.
\
:::info المؤلفون:
(1) ليليانغ رين، مايكروسوفت وجامعة إلينوي في أوربانا-شامبين (liliangren@microsoft.com);
(2) يانغ ليو†، مايكروسوفت (yaliu10@microsoft.com);
(3) يادونغ لو†، مايكروسوفت (yadonglu@microsoft.com);
(4) يلونغ شين، مايكروسوفت (yelong.shen@microsoft.com);
(5) تشن ليانغ، مايكروسوفت (chenliang1@microsoft.com);
(6) ويزو تشن، مايكروسوفت (wzchen@microsoft.com).
:::
:::info هذه الورقة متاحة على arxiv تحت ترخيص CC BY 4.0.
:::
[3] https://github.com/sustcsonglin/flash-linear-attention
\ [4] https://github.com/datamllab/LongLM/blob/master/selfextendpatch/Llama.py
\ [5] https://github.com/jzhang38/TinyLlama
قد يعجبك أيضاً

دورة البيتكوين الرباعية مدفوعة الآن بالسياسة، وليس بالتنصيف: محلل

دورة البيتكوين التي تمتد لأربع سنوات لا تزال قائمة، ولكنها مدفوعة بالسياسة والسيولة: محلل
