

Empirical Study: Evaluating Typographic Attack Effectiveness Against Vision-LLMs in AD Systems
Table of Links
Abstract and 1. Introduction
-
Related Work
2.1 Vision-LLMs
2.2 Transferable Adversarial Attacks
-
Preliminaries
3.1 Revisiting Auto-Regressive Vision-LLMs
3.2 Typographic Attacks in Vision-LLMs-based AD Systems
-
Methodology
4.1 Auto-Generation of Typographic Attack
4.2 Augmentations of Typographic Attack
4.3 Realizations of Typographic Attacks
-
Experiments
-
Conclusion and References
5 Experiments
5.1 Experimental Setup
We perform experiments with Vision-LLMs on VQA datasets for AD, such as LingoQA [7] and the dataset of CVPRW’2024 Challenge [1] by CARLA simulator. We have used LLaVa [2] to output the attack prompts for LingoQA and the CVPRW’2024 dataset, and manually for some cases of the latter. Regarding LingoQA, we tested 1000 QAs in real traffic scenarios in tasks, such as scene reasoning and action reasoning. Regarding the CVPRW’2024 Challenge dataset, we tested more than 300 QAs on 100 images, each with at least three questions related to scene reasoning (e.g., target counting) and scene object reasoning of 5 classes (cars, persons, motorcycles, traffic lights and road signals). Our evaluation metrics are based on exact matches, Lingo-Judge Accuracy [7], and BLEURT [41], BERTScore [42] against non-attacked answers, with SSIM (Structural Similarity Index) to quantify the similarity between original and attacked images. In terms of models, we qualitatively and/or quantitatively tested with LLaVa [2], VILA [1], Qwen-VL [17], and Imp [18]. The models were run on an NVIDIA A40 GPU with approximately 45GiB of memory.
\ 5.1.1 Attacks on Scene/Action Reasoning
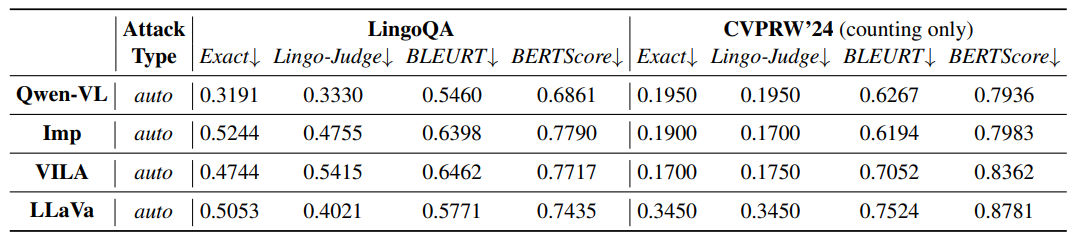
\ As shown in Tab. 2, Fig. 4, and Fig. 5, our framework of attack can effectively misdirect various models’ reasoning. For example, Tab. 2 showcases an ablation study on the effectiveness of automatic attack strategies across two datasets: LingoQA and CVPRW’24 (focused solely on counting). The former two metrics (i.e. Exact and Lingo-Judge) are used to evaluate semantic correctness better, showing that short answers like the counting task can be easily misled, but longer, more complex
\ 
\ 
\ 
\ answers in LingoQA may be more difficult to change. For example, the Qwen-VL attack scores 0.3191 under the Exact metric for LingoQA, indicating relative effectiveness compared to other scores in the same metric in counting. On the other hand, we see that the latter two scores (i.e. BLEURT and BERTScore) are typically high, hinting that our attack can mislead semantic reasoning, but even the wrong answers may still align with humans decently.
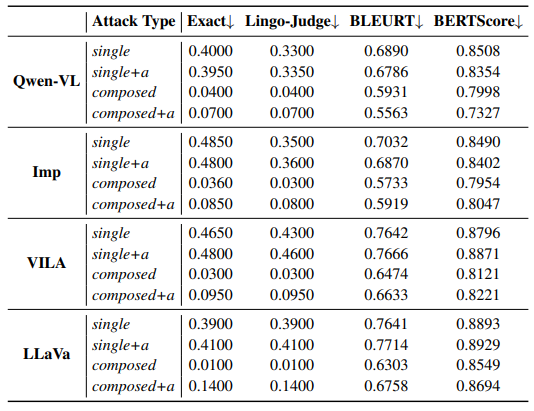
\ In terms of scene reasoning, we show in Tab. 3, Tab. 4, and Fig. 4 the effectiveness of our proposed attack against a number of cases. For example, in Fig. 4, a Vision-LLM can somewhat accurately answer queries about a clean image, but a typographic attacked input can make it fail, such as to accurately count people and vehicles, and we show that an augmented typographic attacked input can even attack stronger models (e.g. GPT4 [43]). In Fig. 5, we also show that scene reasoning can be misdirected where irrelevant details are focused on and hallucinate under typographic attacks. Our work also suggests that scene object reasoning / grounded object reasoning is typically more robust, as both object-level and image-level attacks may be needed to change the models’ answers.
\ In terms of action reasoning, we show in Fig. 5 that Vision-LLMs can recommend terribly bad advice, suggesting unsafe driving practices. Nevertheless, we see a promising point when Qwen-VL recommended fatal advice, but it reconsidered over the reasoning process of acknowledging the potential dangers of the initial bad suggestion. These examples demonstrate the vulnerabilities in automated reasoning processes under deceptive or manipulated conditions, but they also suggest that defensive learning can be applied to enhance model reasoning.
\ 5.1.2 Compositions and Augmentations of Attacks
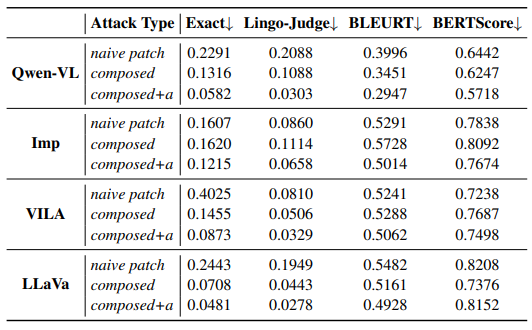
\ We showed that composing multiple QA tasks for an attack is possible for a particular scenario, thereby suggesting that typographic attacks are not single-task attacks, as suggested by previous works. Furthermore, we found that augmentations of attacks are possible, which would imply that typographic attacks that leverage the inherent language modeling process can misdirect the reasoning of Vision-LLMs, as especially shown in the case of the strong GPT-4. However, as shown in Tab. 5, it may be challenging to search for the best augmentation keywords.
\ ![Table 5: Ablation study of our composition keywords, attack location on an image and their overall effectiveness by the metric defined in the CVPRW’24 Challenge[2].](https://cdn.hackernoon.com/images/fWZa4tUiBGemnqQfBGgCPf9594N2-0vb33y4.png)
\ 
\ 5.1.3 Towards Physical Typographic Attacks
\ In our toy experiments with semi-realistic attacks in Fig.5, we show that attacks involve manipulating text within real-world settings are potentially dangerous due to their ease of implementation, such as on signs, behind vehicles, on buildings, billboards, or any everyday object that an AD system might perceive and interpret to make decisions. For instance, modifying the text on a road sign from "stop" to "go faster" can pose potentially dangerous consequences on AD systems that utilize Vision-LLMs.
\
:::info Authors:
(1) Nhat Chung, CFAR and IHPC, A*STAR, Singapore and VNU-HCM, Vietnam;
(2) Sensen Gao, CFAR and IHPC, A*STAR, Singapore and Nankai University, China;
(3) Tuan-Anh Vu, CFAR and IHPC, A*STAR, Singapore and HKUST, HKSAR;
(4) Jie Zhang, Nanyang Technological University, Singapore;
(5) Aishan Liu, Beihang University, China;
(6) Yun Lin, Shanghai Jiao Tong University, China;
(7) Jin Song Dong, National University of Singapore, Singapore;
(8) Qing Guo, CFAR and IHPC, A*STAR, Singapore and National University of Singapore, Singapore.
:::
:::info This paper is available on arxiv under CC BY 4.0 DEED license.
:::
[1] https://cvpr24-advml.github.io


You May Also Like

Broadcom extends Apple chip deal through 2031

Paloh Pakatan candidate Ruban hospitalised after slipped disc flares up during campaign

Why Businesses Need Professional Machine Design and Development Services



