

Ablation of BSGAL: Contribution Estimation and Random Dropout Analysis
Table of Links
Abstract and 1 Introduction
-
Related work
2.1. Generative Data Augmentation
2.2. Active Learning and Data Analysis
-
Preliminary
-
Our method
4.1. Estimation of Contribution in the Ideal Scenario
4.2. Batched Streaming Generative Active Learning
-
Experiments and 5.1. Offline Setting
5.2. Online Setting
-
Conclusion, Broader Impact, and References
\
A. Implementation Details
B. More ablations
C. Discussion
D. Visualization
5.2. Online Setting
5.2.1. MAIN RESULTS
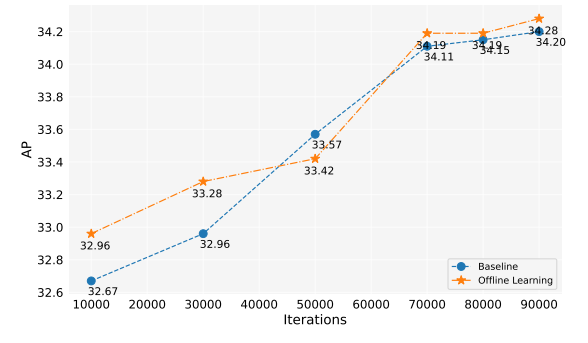
\ To validate the effectiveness of our method in handling longtailed segmentation tasks, we perform experiments on the LVIS (Gupta et al., 2019) dataset. A strong baseline —— XPaste (Zhao et al., 2023), is compared with our method. We further examine the impact of the usage (or non-usage) of CLIP (Radford et al., 2021), as mentioned in their paper, for filtering generated data. Given that X-Paste does not open source the generated data used, we have re-implemented the data generation pipeline and generated thousands of images
\ 
\ 
\ 5.2.2. ABLATION
\ 
\ 
\ 
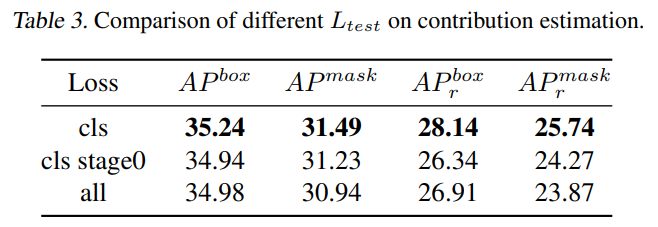
\ Contribution estimation. We are interested in whether the three algorithms proposed in Section 4.2 are effective. Therefore, we conduct comparative experiments here, and the specific results are presented in Table 4.
\ 
\ 
\ 
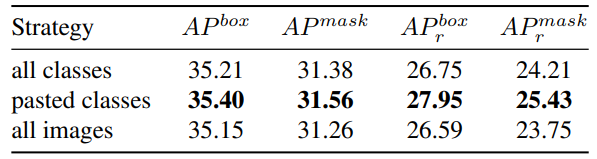
\ Random batch-level dropout. Our algorithm is essentially to accept or reject the generated data on a batch-by-batch basis. Therefore, when the contribution evaluation of the data is completely invalid, our algorithm degenerates into a random batch-level dropout. To verify that it is not this random dropout that brings performance improvement, we conduct a random batch-level Dropout experiment with the same acceptance rate. Table 6 shows that although random dropout will also bring a slight improvement, compared with our method, there is still a very obvious gap, which shows that the improvement brought by our method is not entirely due to random dropout.
\
:::info Authors:
(1) Muzhi Zhu, with equal contribution from Zhejiang University, China;
(2) Chengxiang Fan, with equal contribution from Zhejiang University, China;
(3) Hao Chen, Zhejiang University, China (haochen.cad@zju.edu.cn);
(4) Yang Liu, Zhejiang University, China;
(5) Weian Mao, Zhejiang University, China and The University of Adelaide, Australia;
(6) Xiaogang Xu, Zhejiang University, China;
(7) Chunhua Shen, Zhejiang University, China (chunhuashen@zju.edu.cn).
:::
:::info This paper is available on arxiv under CC BY-NC-ND 4.0 Deed (Attribution-Noncommercial-Noderivs 4.0 International) license.
:::
[1] In CenterNet2, there is only one stage for mask loss. In addition, there are some other losses, which are not listed for simplicity.
You May Also Like

Game Theory and Exchange Economies: A New Model for Pure Exchange and Transferable Payoff

Gold Hits $3,700 as Sprott’s Wong Says Dollar’s Store-of-Value Crown May Slip


