

One Tiny Hypernetwork to Rule All Tasks and Modalities
Table of Links
Abstract and 1. Introduction
- Related Work
- Preliminaries
- Proposed Method
- Experimental Setup
- Results and Analysis
- Discussion and Conclusion, and References
A. The Connection Between Prefix-tuning and Hypernetwork
B. Number of Tunable Parameters
C. Input-output formats
2. Related Work
In this section, we review recent research on parameter-efficient tuning for pure language and V&L tasks, as well as the corresponding work for multi-task learning.
2.1. Parameter-efficient tuning
As recent models grow rapidly in size, how to finetune pretrained models with a small number of trainable parameters becomes more crucial. Existing research (He et al., 2021; Lester et al., 2021; Liu et al., 2021a; Mao et al., 2021) have explored a large amount of methods on parameter-efficient tuning. These methods generally include two categories according to whether new trainable parameters are introduced. One category is that only a subset of model parameters can be updated while freezing the remain (Liu et al., 2021b; Lee et al., 2019). The other is introducing a few task-specific new parameters to different parts of pretrained models, such as before multi-head attention (Li & Liang, 2021), after feedforward layers (Houlsby et al., 2019) or Mixed-and-Match methods (MAM adapter) proposed by He et al. (2021).
2.2. Tuning towards Vision-and-Language
In addition, fine-tuning language models pretrained on pure large text corpora have led to noticeable improvements to V&L tasks. This line of research such as VL-T5 (Cho et al., 2021) and Frozen (Tsimpoukelli et al., 2021) attempts to tune large language models (e.g. T5; GPT-3) to achieve transfer learning for V&L tasks. For example, Frozen aligns the image representation into the word representation space of frozen GPT-3 model which thus is able to generate captions for those images. PICa (Yang et al., 2021) utilizes a pretrained image captioner to convert the image into captions that GPT-3 can understand, and then adapt GPT-3 to solve the VQA tasks in a few-shot manner. Sung et al. (2021) introduces a limited set of new trainable parameters to VL-T5 via a adapter-based method that can match the performance of fine-tuning the entire model.
2.3. Multi-task Learning
Learning a unified model to perform well on multiple different tasks (i.e., multi-task learning) is a challenging problem in both NLP and V&L domains. It has to address many challenges such as catastrophic forgetting, and model overfitting in low-resource tasks while underfitting in high-resource tasks (Aharoni et al., 2019). Radford et al. (2019) highlights the ability of language models to perform a wide range of multitasks in a zero-shot setting. As mentioned above, involving task-specific new parameters such as adapter (Houlsby et al., 2019), can be trained for each task separately while keeping the model fixed. von Oswald et al. (2020) propose a task-conditioned hypernetwork to generate all the weights for the targeted model, while Mahabadi et al. (2021) use a shared hypernetwork to only generate weights for a small number of parameters in adapter modules, to allow the model to adapt to each individual task efficiently.
\ Our motivation. Different from mainstream V&L models that append image tokens to the input sequence, we present a novel perspective of merging textual and visual modalities, by using image embedding and task-specific type embedding of multitasks as input to a shared hypernetwork, which generates weights for prefix-tuning and adapt-tuning modules of PLMs. At the same time, we notice a recent paper (He et al., 2022) that was publicly available days ago. This concurrent work shares the similar motivation like us on generating weights for prefix-tuning modules via a hypernetwork, but their method is only targeted at pure language tasks. Our unified framework is able to improve transfer learning in both pure text and vision-to-language multitasks, in a very parameter-efficient manner.
\
3. Preliminaries
3.1. Pretrained Language Models
All of our models are built on top of the state-of-the-art language model, T5 (Raffel et al., 2020), consisting of an encoder-decoder Transformer (Vaswani et al., 2017) with minor modifications. It frames language tasks as sequence-to-sequence generation, and is trained simultaneously on multiple task datasets. This large-scale T5 model achieves state-of-the-art performances across a diverse set of tasks. We use the T5 backbone as it enables training a universal model that interfaces with many downstream language tasks.
3.2. Multi-task Learning Problem formulation
\ 
\
3.3. Hypernetworks
\ 
\
4. Proposed Method
\ 
\
4.1. Hyper-Embeddings for PELT
\ 
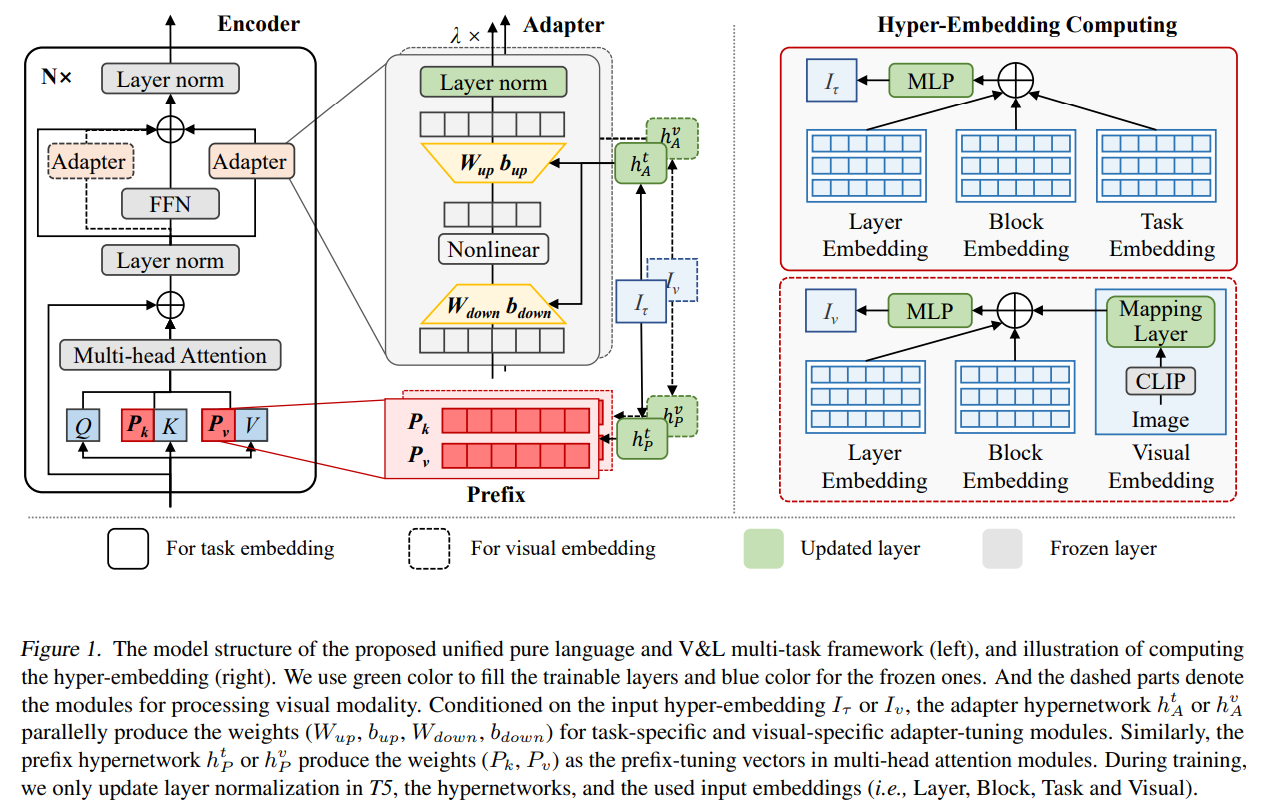
\ 
\ \ \ 
\
4.2. HyperPrefix: Incorporate with Prefix-tuning
Prefix-tuning (Li & Liang, 2021) prepends a number of taskspecific trainable prefix vectors to the parameters of multihead attention (i.e., keys and values) at each transformer layer. In the original implementation, the prefix vectors of each attention block are reparameterized by a two-layer feed-forward network:
\ 
\ 
\
4.3. HyperPELT: Incorporate with Adapter
\ 
\ Note that in Section 4.2, we use the prefix length N as the dimension for hyper-embeddings. We utilize an adaptive pooling operation on hyper-embeddings to adjust the dimension for adapter hypernetwork. Note that due to we extend the dimension of the components of hyper-embeddings in the last section, we utilize an adaptive pooling operation for hyper-embeddings to adjust the dimension for adapter hypernetwork.
4.4. VL-HyperPELT: Incorporate with Visual Modality
\ 
\ 
\
:::info Authors:
(1) Zhengkun Zhang, with Equal contribution from Work is done at the internship of Noah’s Ark Lab, Huawei Technologies
(2) Wenya Guo and TKLNDST, CS, Nankai University, China (yangzl@nankai.edu.cn);
(3) Xiaojun Meng, with Equal contribution from Noah’s Ark Lab, Huawei Technologies;
(4) Yasheng Wang, Noah’s Ark Lab, Huawei Technologies;
(5) Yadao Wang, Noah’s Ark Lab, Huawei Technologies;
(6) Xin Jiang, Noah’s Ark Lab, Huawei Technologies;
(7) Qun Liu, Noah’s Ark Lab, Huawei Technologies;
(8) Zhenglu Yang, TKLNDST, CS, Nankai University, China.
:::
:::info This paper is available on arxiv under CC BY 4.0 DEED license.
:::
\


You May Also Like

Why Stablecoins Don’t Work Without Boring Infrastructure

Reagan adviser: Trump's 'shambolic' admin threatens the republic




