

DiverGen Makes Large-Scale Instance Segmentation Training More Effective
:::info Authors:
(1) Chengxiang Fan, with equal contribution from Zhejiang University, China;
(2) Muzhi Zhu, with equal contribution from Zhejiang University, China;
(3) Hao Chen, Zhejiang University, China (haochen.cad@zju.edu.cn);
(4) Yang Liu, Zhejiang University, China;
(5) Weijia Wu, Zhejiang University, China;
(6) Huaqi Zhang, vivo Mobile Communication Co..
(7) Chunhua Shen, Zhejiang University, China (chunhuashen@zju.edu.cn).
:::
Table of Links
Abstract and 1 Introduction
-
Related Work
-
Our Proposed DiverGen
3.1. Analysis of Data Distribution
3.2. Generative Data Diversity Enhancement
3.3. Generative Pipeline
-
Experiments
4.1. Settings
4.2. Main Results
4.3. Ablation Studies
-
Conclusions, Acknowledgments, and References
\ Appendix
A. Implementation Details
B. Visualization
Abstract
Instance segmentation is data-hungry, and as model capacity increases, data scale becomes crucial for improving the accuracy. Most instance segmentation datasets today require costly manual annotation, limiting their data scale. Models trained on such data are prone to overfitting on the training set, especially for those rare categories. While recent works have delved into exploiting generative models to create synthetic datasets for data augmentation, these approaches do not efficiently harness the full potential of generative models.
\ To address these issues, we introduce a more efficient strategy to construct generative datasets for data augmentation, termed DiverGen. Firstly, we provide an explanation of the role of generative data from the perspective of distribution discrepancy. We investigate the impact of different data on the distribution learned by the model. We argue that generative data can expand the data distribution that the model can learn, thus mitigating overfitting. Additionally, we find that the diversity of generative data is crucial for improving model performance and enhance it through various strategies, including category diversity, prompt diversity, and generative model diversity. With these strategies, we can scale the data to millions while maintaining the trend of model performance improvement. On the LVIS dataset, DiverGen significantly outperforms the strong model X-Paste, achieving +1.1 box AP and +1.1 mask AP across all categories, and +1.9 box AP and +2.5 mask AP for rare categories. Our codes are available at https://github.com/aim-uofa/DiverGen.
1. Introduction
Instance segmentation [2, 4, 9] is one of the challenging tasks in computer vision, requiring the prediction of masks and categories for instances in an image, which serves as the foundation for numerous visual applications. As models’ learning capabilities improve, the demand for training data increases. However, current datasets for instance segmentation heavily rely on manual annotation, which is timeconsuming and costly, and the dataset scale cannot meet the training needs of models. Despite the recent emergence of the automatically annotated dataset SA-1B [12], it lacks category annotations, failing to meet the requirements of instance segmentation. Meanwhile, the ongoing development of the generative model has largely improved the controllability and realism of generated samples. For example, the recent text2image diffusion model [22, 24] can generate high-quality images corresponding to input prompts. Therefore, current methods [27, 28, 34] use generative models for data augmentation by generating datasets to supplement the training of models on real datasets and improve model performance. Although current methods have proposed various strategies to enable generative data to boost model performance, there are still some limitations: 1) Existing methods have not fully exploited the potential of generative models. First, some methods [34] not only use generative data but also need to crawl images from the internet, which is significantly challenging to obtain large-scale data. Meanwhile, the content of data crawled from the internet is uncontrollable and needs extra checking. Second, existing methods do not fully use the controllability of generative models. Current methods often adopt manually designed templates to construct prompts, limiting the potential output of generative models. 2) Existing methods [27, 28] often explain the role of generative data from the perspective of class imbalance or data scarcity, without considering the discrepancy between real-world data and generative data. Moreover, these methods typically show improved model performance only in scenarios with a limited number of real samples, and the effectiveness of generative data on existing large-scale real datasets, like LVIS [8], is not thoroughly investigated.
\ In this paper, we first explore the role of generative data from the perspective of distribution discrepancy, addressing two main questions: 1) Why does generative data augmentation enhance model performance? 2) What types of generative data are beneficial for improving model performance? First, we find that there exist discrepancies between the model learned distribution of the limited real training data and the distribution of real-world data. We visualize the data and find that compared to the real-world data, generative data can expand the data distribution that the model can learn. Furthermore, we find that the role of adding generative data is to alleviate the bias of the real training data, effectively mitigating overfitting the training data. Second, we find that there are also discrepancies between the distribution of the generative data and the real-world data distribution. If these discrepancies are not handled properly, the full potential of the generative model cannot be utilized. By conducting several experiments, we find that using diverse generative data enables models to better adapt to these discrepancies, improving model performance.
\ Based on the above analysis, we propose an efficient strategy for enhancing data diversity, namely, Generative Data Diversity Enhancement. We design various diversity enhancement strategies to increase data diversity from the perspectives of category diversity, prompt diversity, and generative model diversity. For category diversity, we observe that models trained with generative data covering all categories adapt better to distribution discrepancy than models trained with partial categories. Therefore, we introduce not only categories from LVIS [8] but also extra categories from ImageNet-1K [23] to enhance category diversity in data generation, thereby reinforcing the model’s adaptability to distribution discrepancy. For prompt diversity, we find that as the scale of the generative dataset increases, manually designed prompts cannot scale up to the corresponding level, limiting the diversity of output images from the generative model. Thus, we design a set of diverse prompt generation strategies to use large language models, like ChatGPT, for prompt generation, requiring the large language models to output maximally diverse prompts under constraints. By combining manually designed prompts and ChatGPT designed prompts, we effectively enrich prompt diversity and further improve generative data diversity. For generative model diversity, we find that data from different generative models also exhibit distribution discrepancies. Exposing models to data from different generative models during training can enhance adaptability to different distributions. Therefore, we employ Stable Diffusion [22] and DeepFloyd-IF [24] to generate images for all categories separately and mix the two types of data during training to increase data diversity.
\ At the same time, we optimize the data generation workflow and propose a four-stage generative pipeline consisting of instance generation, instance annotation, instance filtration, and instance augmentation. In the instance generation stage, we employ our proposed Generative Data Diversity Enhancement to enhance data diversity, producing diverse raw data. In the instance annotation stage, we introduce an annotation strategy called SAM-background. This strategy obtains high-quality annotations by using background points as input prompts for SAM [12], obtaining the annotations of raw data. In the instance filtration stage, we introduce a metric called CLIP inter-similarity. Utilizing the CLIP [21] image encoder, we extract embeddings from generative and real data, and then compute their similarity. A lower similarity indicates lower data quality. After filtration, we obtain the final generative dataset. In the instance augmentation stage, we use the instance paste strategy [34] to increase model learning efficiency on generative data.
\ Experiments demonstrate that our designed data diversity strategies can effectively improve model performance and maintain the trend of performance gains as the data scale increases to the million level, which enables largescale generative data for data augmentation. On the LVIS dataset, DiverGen significantly outperforms the strong model X-Paste [34], achieving +1.1 box AP [8] and +1.1 mask AP across all categories, and +1.9 box AP and +2.5 mask AP for rare categories.
\ In summary, our main contributions are as follows:
\ • We explain the role of generative data from the perspective of distribution discrepancy. We find that generative data can expand the data distribution that the model can learn, mitigating overfitting the training set and the diversity of generative data is crucial for improving model performance.
\ • We propose the Generative Data Diversity Enhancement strategy to increase data diversity from the aspects of category diversity, prompt diversity, and generative model diversity. By enhancing data diversity, we can scale the data to millions while maintaining the trend of model performance improvement.
\ • We optimize the data generation pipeline. We propose an annotation strategy SAM-background to obtain higher-quality annotations. We also introduce a filtration metric called CLIP inter-similarity to filter data and further improve the quality of the generative dataset.
2. Related Work
Instance segmentation. Instance segmentation is an important task in the field of computer vision and has been extensively studied. Unlike semantic segmentation, instance segmentation not only classifies the pixels at a pixel level but also distinguishes different instances of the same category. Previously, the focus of instance segmentation research has primarily been on the design of model structures. Mask-RCNN [9] unifies the tasks of object detection and instance segmentation. Subsequently, Mask2Former [4] further unified the tasks of semantic segmentation and instance segmentation by leveraging the structure of DETR [2].
\ Orthogonal to these studies focusing on model architecture, our work primarily investigates how to better utilize generated data for this task. We focus on the challenging
\ 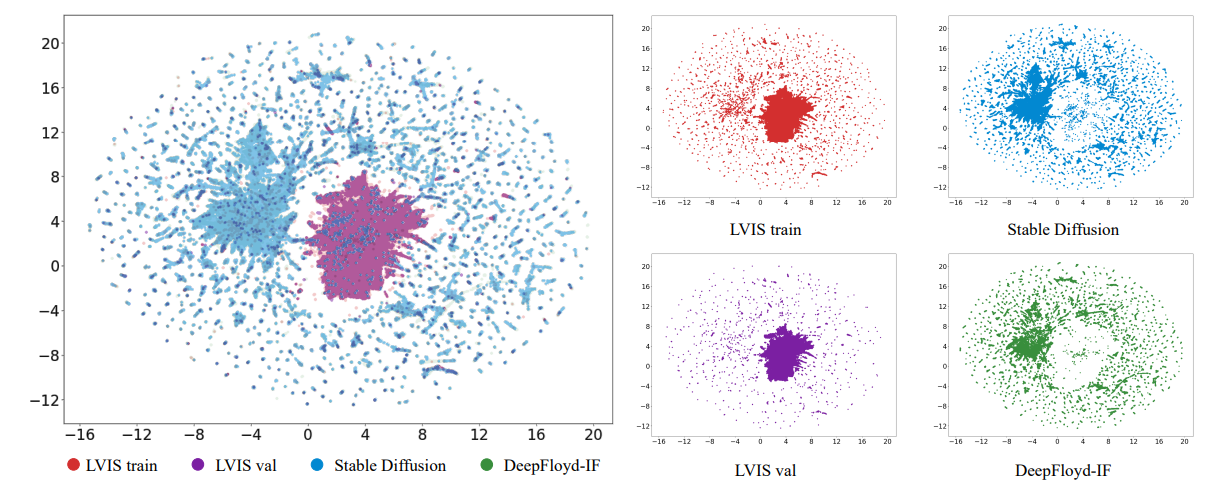
\ long-tail dataset LVIS [8] because it is only the long-tailed categories that face the issue of limited real data and require generative images for augmentation, making it more practically meaningful.
\ Generative data augmentation. The use of generative models to synthesize training data for assisting perception tasks such as classification [6, 32], detection [3, 34], segmentation [14, 27, 28], etc. has received widespread attention from researchers. In the field of segmentation, early works [13, 33] utilize generative adversarial networks (GANs) to synthesize additional training samples. With the rise of diffusion models, there have been numerous efforts [14, 27, 28, 30, 34] to utilize text2image diffusion models, such as Stable Diffusion [22], to boost the segmentation performance. Li et al. [14] combine the Stable Diffusion model with a novel grounding module and establish an automatic pipeline for constructing a segmentation dataset. DiffuMask [28] exploits the potential of cross-attention maps between text and images to synthesize accurate semantic labels. More recently, FreeMask [30] uses a mask-to-image generation model to generate images conditioned on the provided semantic masks. However, the aforementioned work is only applicable to semantic segmentation. The most relevant work to ours is X-Paste [34], which promotes instance segmentation through copy-pasting the generative images and a filter strategy based on CLIP [21].
\ In summary, most methods only demonstrate significant advantages when training data is extremely limited. They consider generating data as a means to compensate for data scarcity or class imbalance. However, in this work, we take a further step to examine and analyze this problem from the perspective of data distribution. We propose a pipeline that enhances diversity from multiple levels to alleviate the impact of data distribution discrepancies. This provides new insights and inspirations for further advancements in this field.
\
:::info This paper is available on arxiv under CC BY-NC-ND 4.0 Deed (Attribution-Noncommercial-Noderivs 4.0 International) license.
:::
\
You May Also Like

The Channel Factories We’ve Been Waiting For


American Bitcoin’s $5B Nasdaq Debut Puts Trump-Backed Miner in Crypto Spotlight
